
我用开源数据集lora微调后,发现很多回答都不太准确,跟指令一模一样的问题都答错了,这种问题怎么解决呀?
微调配置如下:
cutoff_len: 1024
dataset: alpaca_gpt4_data_en.json,alpaca_gpt4_data_zh.json,code_alpaca_20k.json
dataset_dir: /xxx
ddp_timeout: 180000000
deepspeed: cache/ds_z2_config.json
do_train: true
eval_steps: 100
eval_strategy: steps
finetuning_type: lora
flash_attn: auto
fp16: true
gradient_accumulation_steps: 8
include_num_input_tokens_seen: true
learning_rate: 5.0e-05
logging_steps: 10
lora_alpha: 16
lora_dropout: 0
lora_rank: 16
lora_target: all
lr_scheduler_type: cosine
max_grad_norm: 0.5
max_samples: 100000
model_name_or_path: /xxx/Baichuan-7B-Base
num_train_epochs: 2.0
optim: adamw_torch
output_dir: saves/Baichuan-7B-Base/lora/hiyouga_Baichuan-7B-sft
packing: false
per_device_eval_batch_size: 8
per_device_train_batch_size: 8
plot_loss: true
preprocessing_num_workers: 16
quantization_method: bitsandbytes
report_to: none
save_steps: 100
stage: sft
template: default
val_size: 0.01
warmup_steps: 0
{
"epoch": 1.9989299090422685,
"eval_accuracy": 0.7150343523585071,
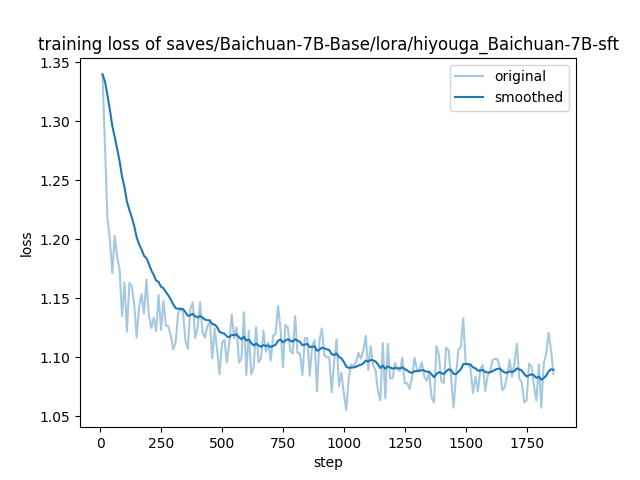
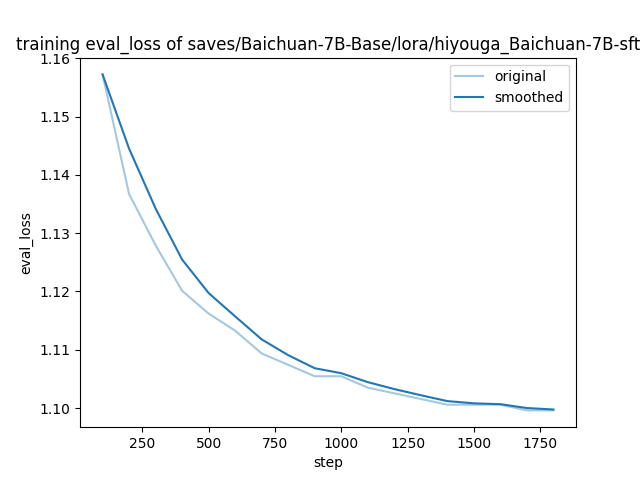
"eval_loss": 1.099609375,
"eval_runtime": 31.0477,
"eval_samples_per_second": 38.94,
"eval_steps_per_second": 2.448,
"num_input_tokens_seen": 91293504,
"total_flos": 3.710641784267735e+18,
"train_loss": 1.1082913645840304,
"train_runtime": 19932.6598,
"train_samples_per_second": 12.002,
"train_steps_per_second": 0.094
}
A100 * 2
cuda_11.7.r11.7
LLaMA-Factory:最新版本
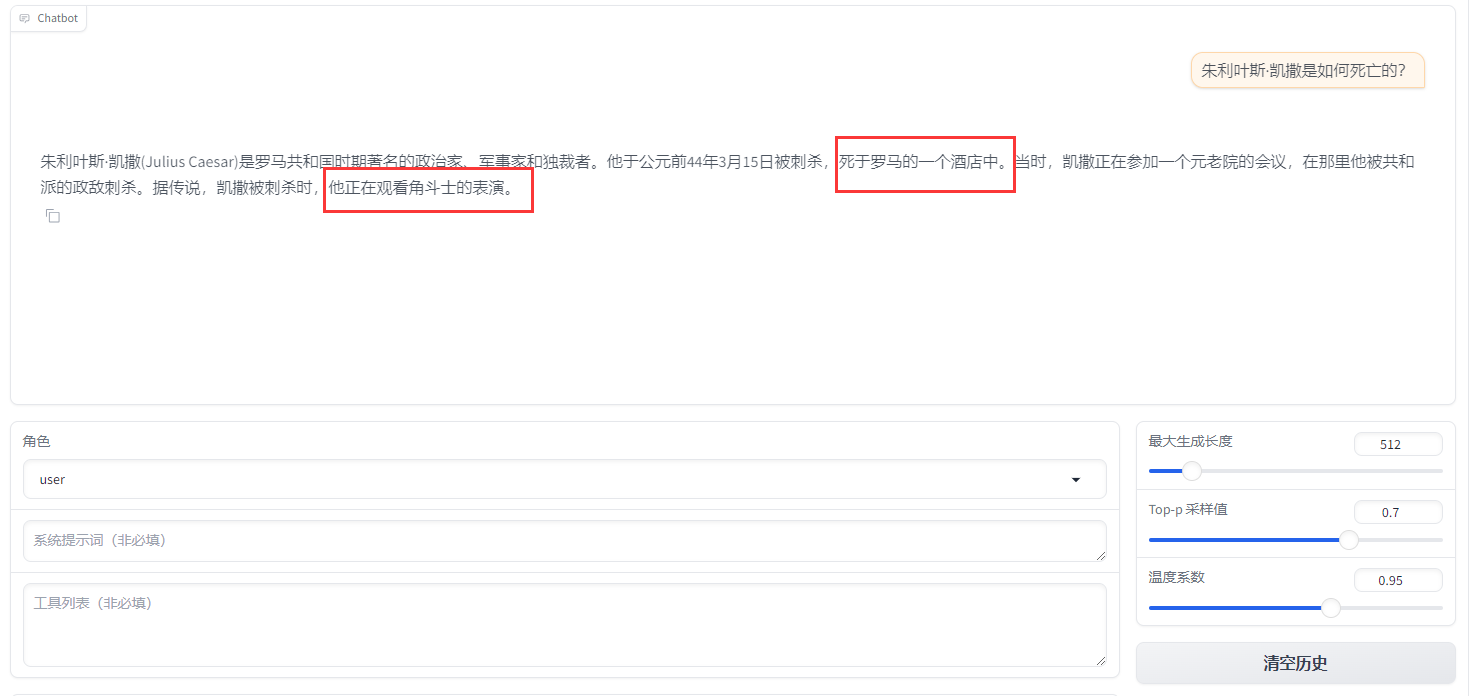
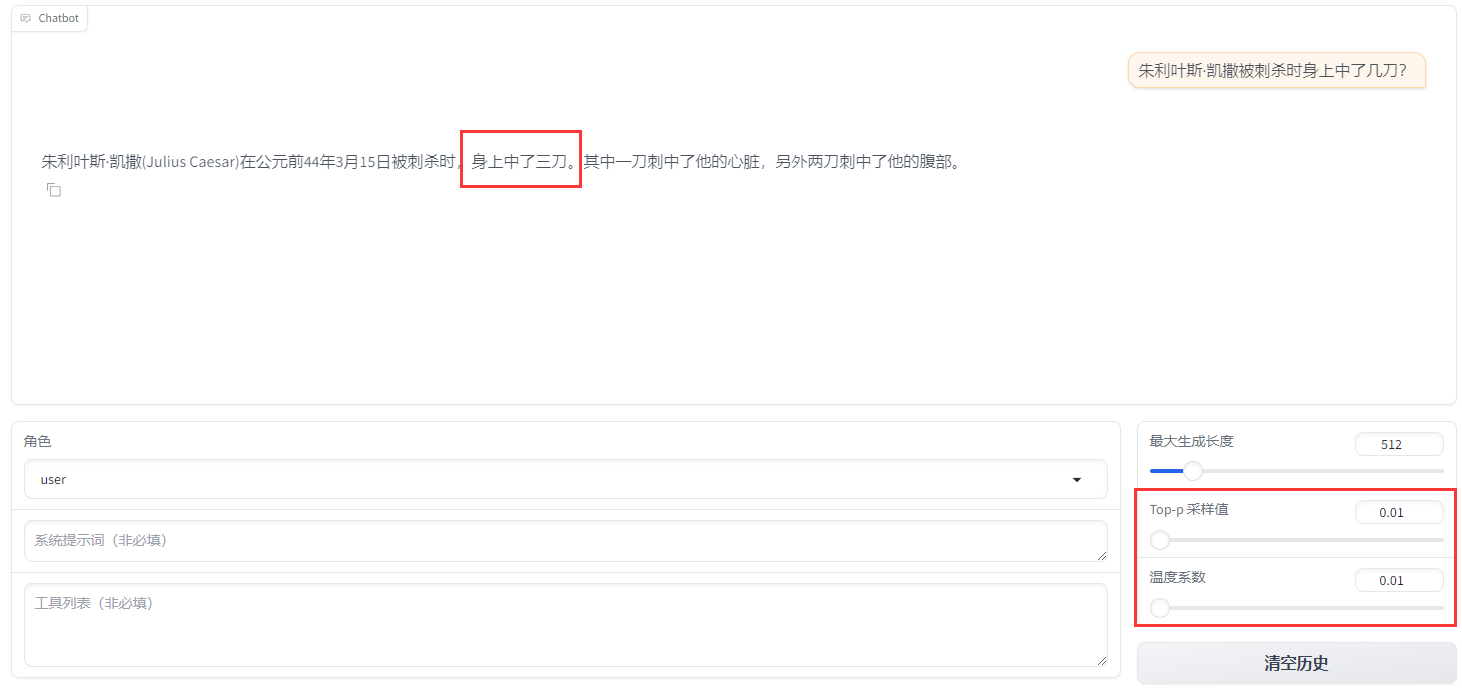
原始数据(alpaca_gpt4_data_zh):
{
"instruction": "朱利叶斯·凯撒是如何死亡的?",
"input": "",
"output": "朱利叶斯·凯撒,又称尤利乌斯·恺撒(Julius Caesar)是古罗马的政治家、军事家和作家。他于公元前44年3月15日被刺杀。 \n\n根据历史记载,当时罗马元老院里一些参议员联合起来策划了对恺撒的刺杀行动,因为他们担心恺撒的统治将给罗马共和制带来威胁。在公元前44年3月15日(又称“3月的艾达之日”),恺撒去参加元老院会议时,被一群参议员包围并被攻击致死。据记载,他身中23刀,其中一刀最终致命。"
},
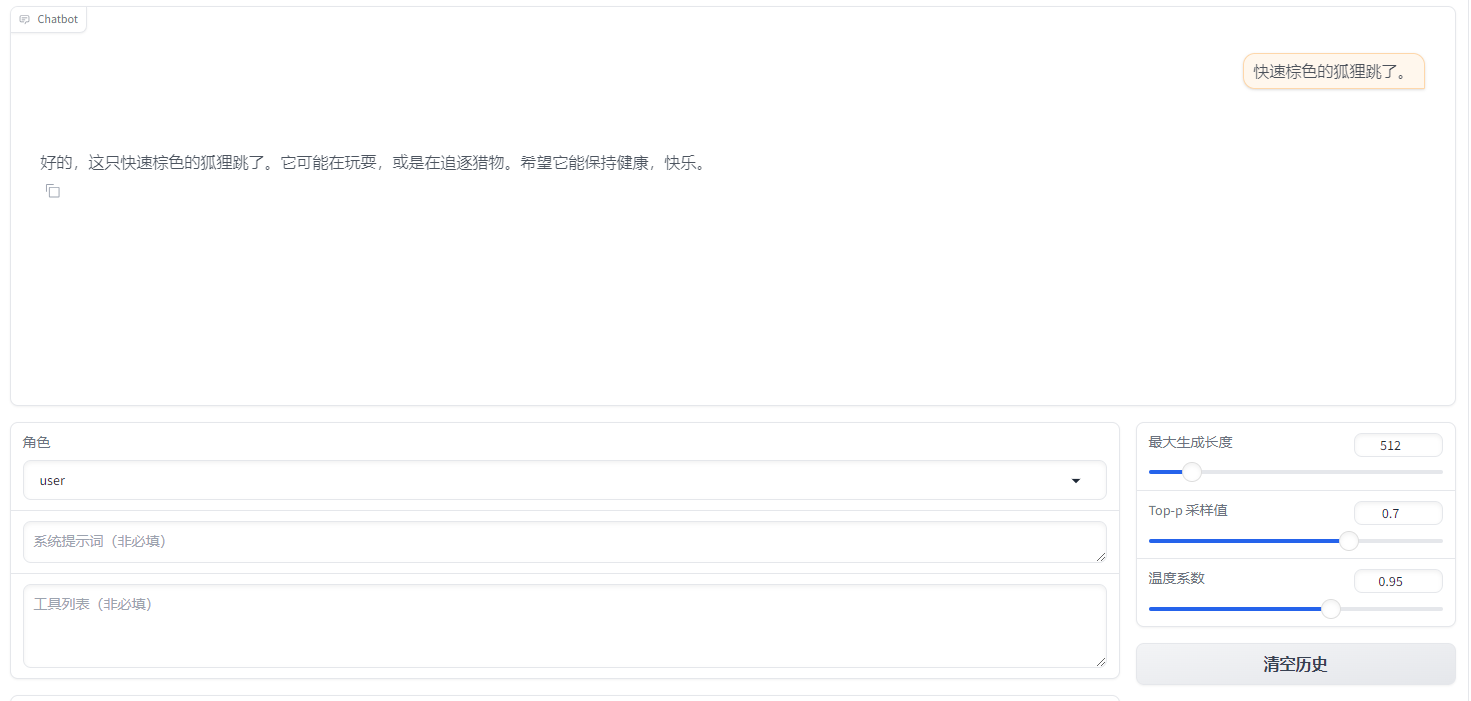
原始数据(alpaca_gpt4_data_zh):
{
"instruction": "快速棕色的狐狸跳了。",
"input": "",
"output": "This sentence in Chinese roughly translates to \"The quick brown fox jumps.\" in English. Is there something specific you would like me to do with this information?"
},
可以尝试使用相对较低的版本mlx 框架,之前Apple 有说过有的版本对中文支持不太好。现在可以使用最新版本试试。
