DataWorks有10亿数据,要从mc到holo,准备用holo外表映射mc然后覆盖写入内表, 然后这个操作是每天都要做的, 所以想做个定时任务, 如果定时任务的话 只能在这做了或者 针对我这种场景 有没啥其他做法建议?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
考虑分布式处理
利用大数据引擎:DataWorks基于MaxCompute、Hologres等大数据引擎,这些引擎天然支持分布式处理。可以考虑将数据分布到多个节点上进行处理,以减轻单个节点的负担。
针对您的场景,以下是一些建议:
使用DataWorks的调度功能:
在DataWorks中,您可以使用调度功能创建定时任务,并指定任务的执行时间、执行周期等信息。例如,您可以使用以下语句创建一个每天凌晨0点执行的定时任务:
schedule interval "1d" start_time "2021-01-01T00:00Z"
在上述语句中,“interval 1d”表示任务的执行周期为每天,“start_time 2021-01-01T00:00Z”表示任务的执行时间为每天凌晨0点。
使用DataWorks的API:
在DataWorks中,您可以使用API来创建、编辑、删除任务等操作。例如,您可以使用以下Python代码创建一个任务:
import odps
client = odps.get_offline_client(ENDPOINT, PROJECT_NAME)
task = client.create_task(name='my_task',
engine=odps.models.TaskEngine.DISTRIBUTED_DAG,
params={'param1': 'value1'})
在上述代码中,“create_task”方法用于创建一个任务,“name”参数指定任务的名称,“engine”参数指定任务的执行引擎,“params”参数指定任务的属性。
使用Datax:
在DataWorks中,您可以使用Datax来同步数据。Datax是一个开源的数据同步工具,支持多种数据源和目标,可以轻松地将数据从MySQL、Oracle、MongoDB等数据源同步到HDFS、HBase、Hive等目标。您可以使用以下语句创建一个Datax任务:
dx job=job.json thread=5 speed=medium mode=standalone quiet=true print=console pidfile=/datax.pid log=/datax.log output=/datax.out error=/datax.err
在上述语句中,“job.json”是Datax任务的配置文件,“thread”是任务的最大线程数,“speed”是任务的速度,“mode”是任务的模式,“quiet”是任务的日志级别,“pidfile”是任务的进程ID文件,“log”是任务的日志文件,“output”是任务的输出文件,“error”是任务的错误文件。
以上是一些建议,您可以根据自己的需求选择适合自己的方法。如果您还有其他问题,欢迎随时联系我们。
确保外表的定义与MaxCompute源表结构相匹配,特别是对于分区表,需正确配置分区列。
用DataWorks的数据集成服务(Data Integration)创建一个离线同步任务,配置源端为MaxCompute项目,目标端为Hologres项目,指定相应的表进行数据迁移
可以使用DataWorks创建定时任务来实现每天的数据同步。步骤如下:
在DataWorks中,使用DataWorks数仓开发创建SQL任务,配置从MaxCompute(MC)到Hologres的数据同步脚本,确保使用Hologres的外表映射MC表,并通过INSERT INTO或INSERT OVERWRITE语句覆盖写入Hologres的内表。
设置任务调度,根据需求配置每天的执行时间,确保任务按时运行。
参考文档:通过DataWorks周期性导入MaxCompute数据最佳实践
在处理大量数据的任务时,必须制定定时任务来确保数据处理的高效和准时。面对DataWorks中10亿数据的挑战,有多种策略可以采用以优化任务执行的效率和稳定性。以下是一些具体建议和方法:
利用DataWorks的定时任务功能
创建ODPS SQL任务:在DataWorks中创建一个ODPS SQL任务,编写需要执行的SQL语句,确保语句针对大规模数据的高效性。
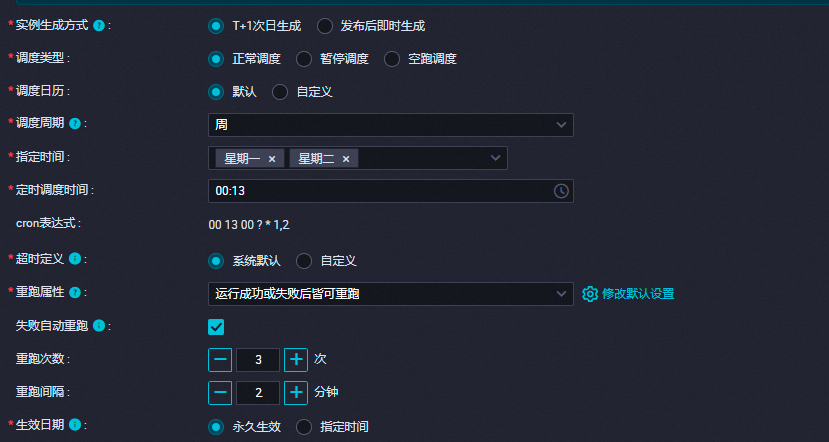
配置调度参数:在任务的“调度配置”页面中,设置任务的调度参数,包括调度类型(如按日调度)、调度周期、起始时间、重复次数等,以确保任务能够按照预定的时间自动执行。
优化SQL语句:特别关注SQL语句的优化,使用合适的索引、避免全表扫描、减少数据关联操作等,以提高查询效率。
考虑分布式处理
利用大数据引擎:DataWorks基于MaxCompute、Hologres等大数据引擎,这些引擎天然支持分布式处理。可以考虑将数据分布到多个节点上进行处理,以减轻单个节点的负担。
并行计算:利用MapReduce、Spark等并行计算技术,将大任务分解成多个小任务并行执行,从而缩短整体执行时间。
数据分区与分批处理
数据分区:将10亿数据按照某种规则(如时间、地区、用户ID等)进行分区,每个分区独立处理,这样可以减少每次处理的数据量,提高处理效率。
分批处理:如果数据量大到一次处理不过来,可以考虑将数据分批处理,每批处理一部分数据,直到所有数据都处理完毕。
监控与调优
监控任务执行:在任务执行过程中,实时监控任务的运行状态和性能指标,如发现异常或性能瓶颈,及时进行调整和优化。
定期评估与调优:定期对定时任务进行评估,检查其执行效率、稳定性和资源占用情况,并根据评估结果对任务进行调优。
考虑使用其他技术或服务
数据仓库服务:如果DataWorks的处理能力无法满足需求,可以考虑使用阿里云提供的其他数据仓库服务,如ApsaraDB for Data Lake Analytics(DLA),这些服务通常具有更强的数据处理能力和更高的性能。
云服务集成:考虑将DataWorks与其他云服务(如ECS、RDS等)进行集成,利用云服务的弹性伸缩能力来应对数据量的变化。
备份与恢复
定期备份数据:在处理大量数据时,定期备份数据是非常重要的,一旦数据丢失或损坏,可以通过备份数据进行恢复。
容灾与恢复计划:制定完善的容灾与恢复计划,确保在出现意外情况时能够迅速恢复业务运行。
综上所述,通过充分利用DataWorks平台的功能和优势,结合分布式处理、数据分区与分批处理、监控与调优等多种策略,可以有效提升处理10亿数据任务的执行效率和稳定性。如果DataWorks的处理能力无法满足需求,还可以考虑使用其他技术或服务来应对。
面对DataWorks中处理10亿数据的定时任务,确实需要在DataWorks平台上进行配置和执行,但也可以考虑一些优化策略和其他做法来提升任务执行效率和稳定性。以下是一些建议:
在DataWorks中,处理每天需要同步10亿条数据的任务确实是个挑战。以下是一些建议,希望能帮助您更高效地完成这项工作:
分批处理:将每天的数据分成多个批次进行处理,每次处理一部分数据。这样不仅可以减少一次性处理大量数据带来的压力,也能在过程中及时发现和解决问题。
使用增量同步:如果数据源支持增量同步,可以尝试使用增量同步的方式来减少数据同步的时间和资源消耗。例如,可以只同步当天新增或修改的数据,而不是全量同步。
优化数据同步策略:根据实际情况,优化数据同步策略。例如,可以考虑增加缓存、分批处理、异步执行等策略,以减少数据同步的时间和资源消耗。
可以使用DataWorks创建定时任务来实现每天的数据同步。步骤如下:
在DataWorks中,使用DataStudio创建一个SQL任务,配置SQL脚本来执行Hologres的INSERT INTO...SELECT语句,从MaxCompute(MC)的外部表(通过import foreign schema创建)中选择数据并覆盖写入Hologres的内部表。
设置任务调度,根据需求配置每天执行的时间和频率。
配置任务依赖,确保在MaxCompute数据准备好后执行Hologres的写入任务。
这样每天定时任务会自动执行,将MC的数据同步到Hologres。
可参考文档
对于您提到的需求,即每天从MaxCompute (MC) 将10亿条数据映射到Hologres (Holo),并执行覆盖写入操作,可以考虑几种不同的方法来实现定时任务。这里提供一些可能的解决方案供您参考:
DataWorks 提供了丰富的任务调度能力,可以直接在 DataWorks 中创建一个定时任务来实现这一需求。步骤如下:
INSERT INTO 或 UPSERT INTO 语句将数据写入Hologres表。如果您希望在MaxCompute中处理数据,然后再将其写入Hologres,可以考虑使用MaxCompute SQL来实现数据的映射和写入。步骤如下:
INSERT INTO 或 UPSERT INTO 语句将数据写入Hologres。如果您希望实时捕获MaxCompute表的变化,并将这些变化实时同步到Hologres,可以考虑使用Apache Flink的CDC功能。这种方式可以实现实时的数据同步。
如果您希望采用流式处理的方式来处理数据,可以考虑使用DataHub来作为数据传输通道,再利用Flink进行处理。
如果您希望更灵活地控制任务的执行,可以考虑使用DataWorks API来触发任务。这种方式适合于需要动态控制任务执行的情况。
针对您的需求,推荐使用DataWorks内置的任务调度功能来实现定时任务。这种方式最简单直接,易于管理和维护。如果您有特殊的需求,如实时处理或流式处理,则可以考虑使用Flink CDC或DataHub + Flink的方案。在选择方案时,请根据您的具体需求、资源可用性以及技术栈来进行权衡。
首先你需要
确保MaxCompute与Hologres数据源已配置
。登录DataWorks控制台,进入管理中心,选择对应工作空间,然后在数据源页面新增MaxCompute和Hologres数据源。
步骤二:设计数据同步方案
使用Hologres外表映射MaxCompute表:首先,在Hologres中创建外表直接映射MaxCompute表,这样可以实现数据的即时查询而无需立即迁移全部数据
定时覆盖写入Hologres内表:设计一个ODPS SQL节点任务,用于每天从MaxCompute外表中提取数据并覆盖写入到Hologres的内表中。这一步骤可以通过编写SQL实现数据的筛选、聚合等处理。
步骤三:创建定时任务
新建业务流程:在DataWorks中,创建一个新的业务流程,用于组织和调度数据同步任务。
配置离线同步节点:为MaxCompute到Hologres的数据同步创建一个离线同步节点,配置数据来源为MaxCompute,数据去向为Hologres。设置数据过滤条件以确保只同步当天数据
调度配置:在离线同步节点的调度配置中,设定任务为每天执行一次,比如在每天凌晨执行,确保数据的每日更新。可以设置任务的开始时间为00:00,以符合每日定时需求。
步骤四:目标表映射与转换
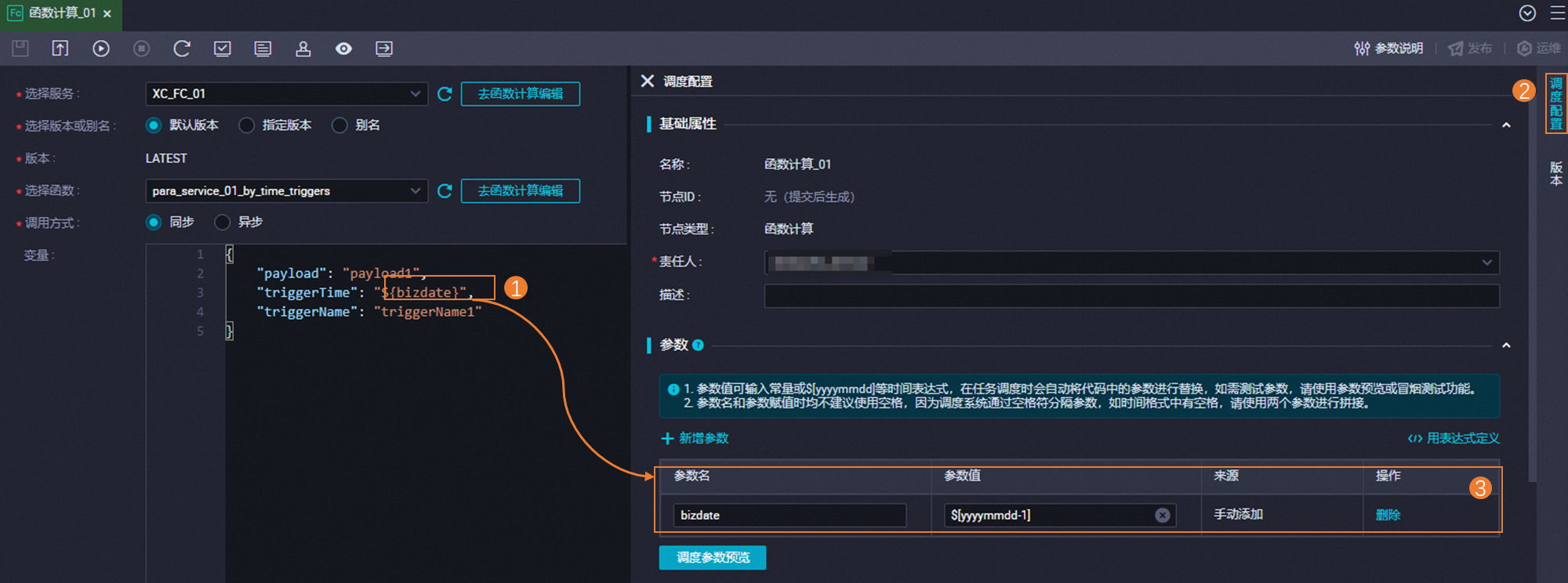
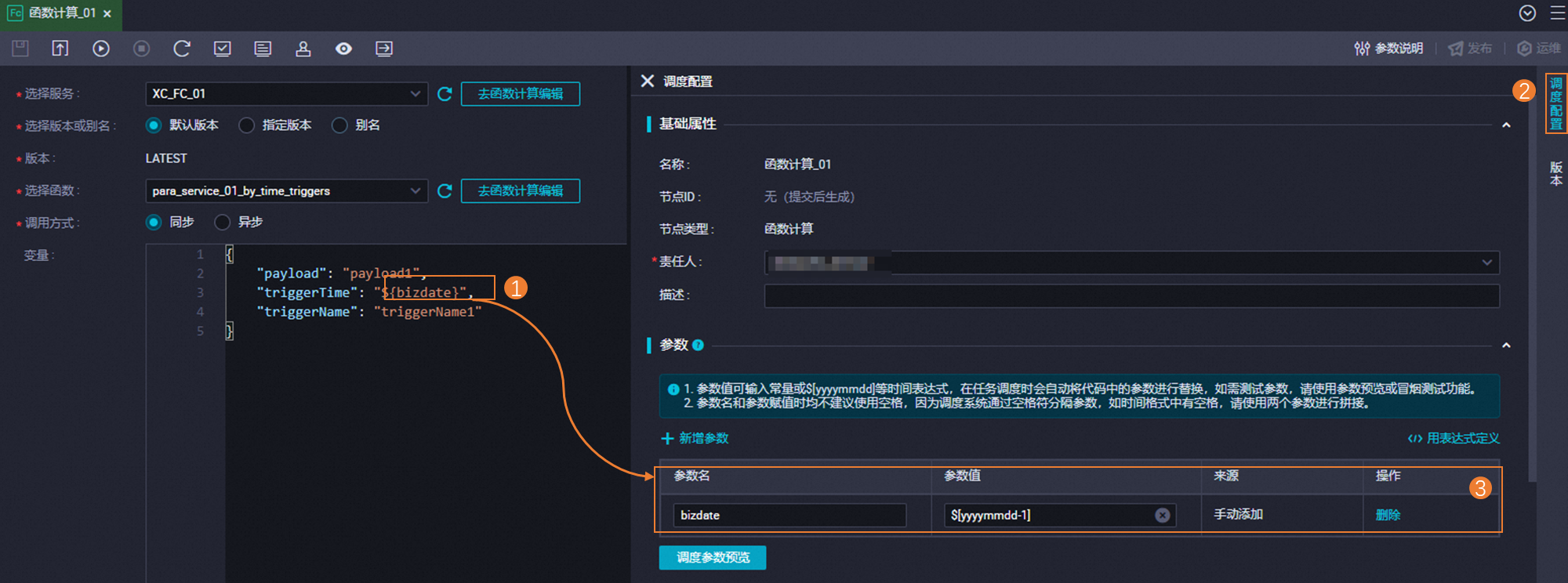
在同步任务配置中,详细定义 目标表的映射规则 ,包括Schema名和表名映射,确保数据正确写入到Hologres的目标表中。利用内置变量和正则表达式简化配置过程,如将MaxCompute表名映射到相应的Hologres表名
字段类型映射与自定义:检查并调整源表与目标表的字段类型映射,如有必要,为Hologres表添加新字段或调整字段类型。
将MaxCompute (MC) 中的10亿数据每天迁移到AnalyticDB for PostgreSQL (Hologres),并且使用外表映射MC然后覆盖写入内表的方式,你数据是真的多呀
你可以先创建离线同步节点:在DataWorks的数据开发页面中,创建一个离线同步节点,选择MC作为源数据源,Hologres作为目标数据源 。
然后在同步任务配置中,您可以设置MC的外表作为数据来源,并在Hologres中创建相应的内表结构。然后,配置任务以实现数据的覆盖写入操作 。
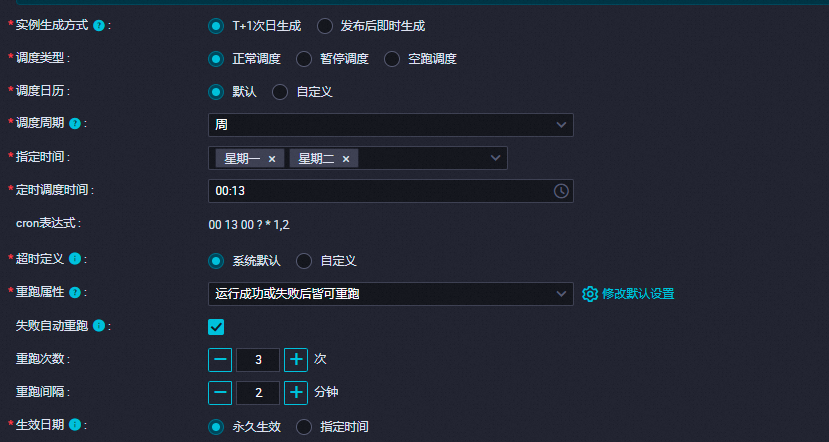
在离线同步节点的编辑页面中,通过调度配置设置任务的自动调度属性。选择适合您业务需求的调度周期,例如,如果您需要每天执行任务,可以选择“日调度”,并设置具体的运行时间点 。
选择合适的实例生成方式,例如“发布后即时生成”,以便任务在发布到生产环境后能够立即按照设定的时间调度运行 。
配置完成后,提交任务并将其发布到生产环境。这样,任务就会根据您设置的调度属性每天自动执行
针对DataWorks中从MC(MaxCompute)到Holo(Hologres)的10亿数据迁移,并希望实现每天定时覆盖写入内表的需求,可以采取以下做法:
设置Holo外表映射MC:首先,在Holo中创建一个外部表(External Table),该表映射到MC中的对应表。这允许Holo在执行查询时直接访问MC中的数据,而无需物理复制。
创建Holo内表:在Holo中创建一个内部表(Internal Table),用于存储最终处理后的数据。这个表将是定时任务的目标表。
编写定时任务:
使用DataWorks的调度功能创建一个定时任务。
在任务中,编写SQL脚本,实现从Holo外表读取MC数据,并将处理后的数据写入到Holo内表中。这可以通过INSERT OVERWRITE或类似的SQL语句实现,以覆盖内表中已有的数据。
设置任务的执行时间和频率,例如每天凌晨执行一次。
优化和监控:
对SQL脚本进行优化,确保数据迁移的效率。
在DataWorks中设置监控,以跟踪任务的执行状态和性能。
备份和恢复:
考虑在实施前备份重要数据,以防万一发生数据丢失或错误。
制定数据恢复计划,以应对可能的数据问题。
此外,也可以考虑使用DataWorks的数据同步功能或DataHub等中间件来实现更高效的数据迁移和同步。这些方法可以根据具体的业务需求和资源情况进行选择。
可以使用DataWorks的调度功能来实现
若任务需要周期性调度运行,您需定义该任务的调度相关属性,包括调度周期、调度依赖、调度参数等。本文为您介绍调度配置的相关内容。
DataWorks基于MaxCompute/Hologres/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。