
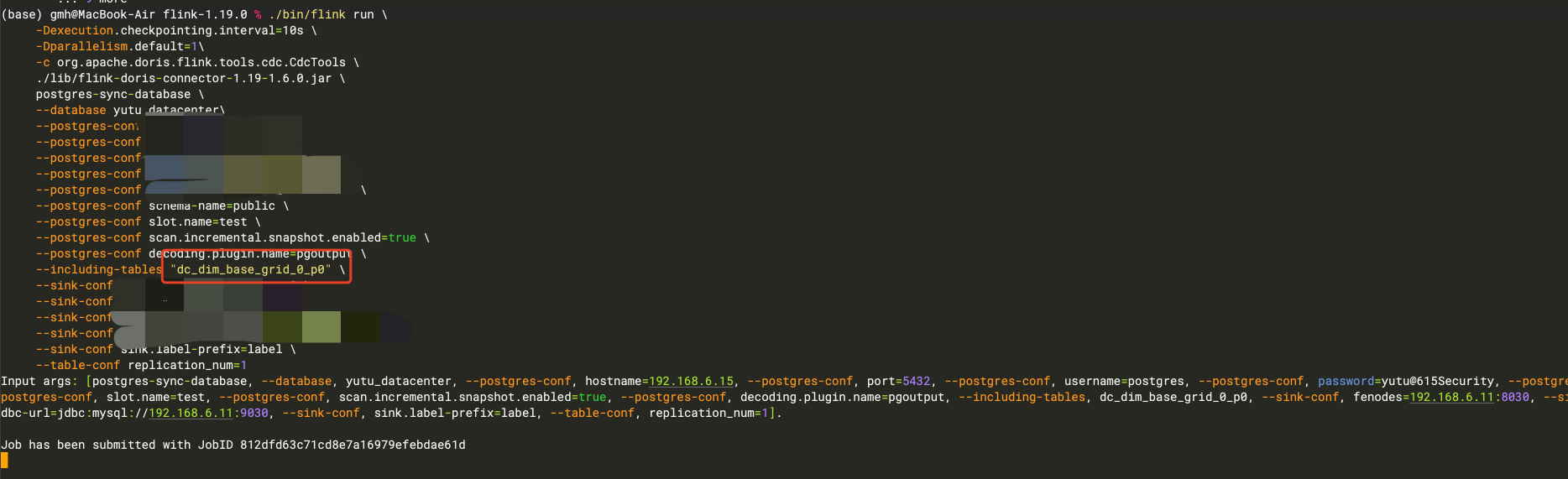
flinkcdc pgsql 怎么读不到分页的表?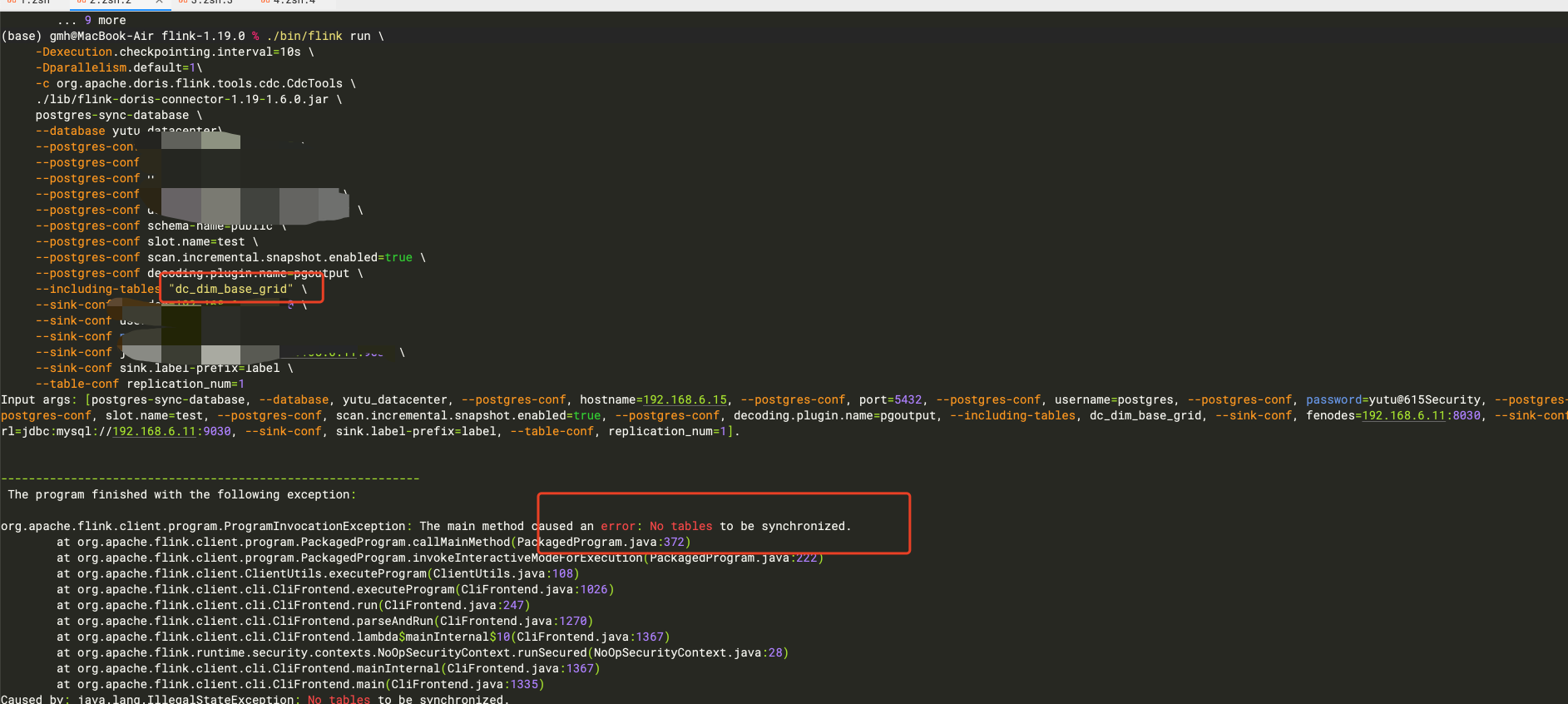
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
Flink CDC 在读取 PostgreSQL 数据库时,如果无法读取到分页的表(例如使用 pg_pathman 插件创建的分区表),可能是由于以下原因导致的。以下是详细分析和解决方法:
Flink CDC 是通过捕获数据库的变更日志(如 MySQL 的 Binlog 或 PostgreSQL 的逻辑复制槽)来实现数据同步的。对于 PostgreSQL,Flink CDC 依赖于逻辑解码(Logical Decoding)功能,它会读取主表的变更日志,但不会自动感知分区表的结构。
如果使用了 pg_pathman 插件创建的分区表,Flink CDC 默认只会读取主表的变更日志,而不会自动递归读取子分区表的数据。
分区表的特殊性
分区表在 PostgreSQL 中是通过主表和多个子表(分区)实现的。pg_pathman 插件会动态管理这些分区,但 Flink CDC 并不会自动识别这些子表的变更日志。
逻辑复制的限制
PostgreSQL 的逻辑复制机制默认只捕获主表的变更日志。如果数据直接写入子分区表,而主表没有记录对应的变更日志,Flink CDC 就无法感知这些变更。
配置问题
如果未正确配置 PostgreSQL 的逻辑复制槽或未启用相关参数,也可能导致 Flink CDC 无法正常读取数据。
为了确保 Flink CDC 能够捕获所有分区表的数据变更,建议在写入数据时,始终通过主表进行操作,而不是直接写入子分区表。PostgreSQL 会自动将数据路由到正确的分区,同时主表会记录变更日志。
操作步骤: 1. 确保应用程序或 ETL 工具在写入数据时,目标表为主表,而非子分区表。 2. 验证主表的变更日志是否包含所有分区的数据。
如果必须直接写入子分区表,可以通过手动配置逻辑复制槽来捕获子分区表的变更日志。
操作步骤: 1. 在 PostgreSQL 中为每个子分区表创建独立的逻辑复制槽:
SELECT pg_create_logical_replication_slot('slot_partition_1', 'test_decoding');
如果分区表的数量较少,可以考虑将分区表合并为单个表,从而避免分区表带来的复杂性。
操作步骤: 1. 使用 pg_pathman 提供的 merge_range_partitions 函数合并相邻分区:
SELECT merge_range_partitions('part_test_1'::regclass, 'part_test_1_2'::regclass);
pg_pathman 插件已被 PostgreSQL 原生分区表功能取代。建议升级到 PostgreSQL 10 或更高版本,并使用原生分区表功能。原生分区表的变更日志会自动记录在主表中,Flink CDC 可以正常读取。
操作步骤: 1. 将现有 pg_pathman 分区表迁移到原生分区表:
CREATE TABLE part_test (
id INT,
info TEXT,
crt_time TIMESTAMP NOT NULL
) PARTITION BY RANGE (crt_time);
CREATE TABLE part_test_1 PARTITION OF part_test
FOR VALUES FROM ('2023-01-01') TO ('2023-02-01');
性能优化
如果分区表数量较多,建议降低 Flink 作业的并发数或调整连接池大小,以避免占用过多的数据库连接资源。
权限配置
确保 Flink CDC 使用的数据库用户具有足够的权限(如 REPLICATION 权限)来读取逻辑复制槽和变更日志。
版本兼容性
确保 PostgreSQL 和 Flink CDC 的版本兼容。建议使用最新版本的 Flink CDC 连接器以获得更好的支持。
通过以上方法,您可以解决 Flink CDC 无法读取 PostgreSQL 分区表的问题。如果问题仍然存在,请检查 PostgreSQL 的逻辑复制日志和 Flink CDC 的配置日志,进一步排查具体原因。
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。
