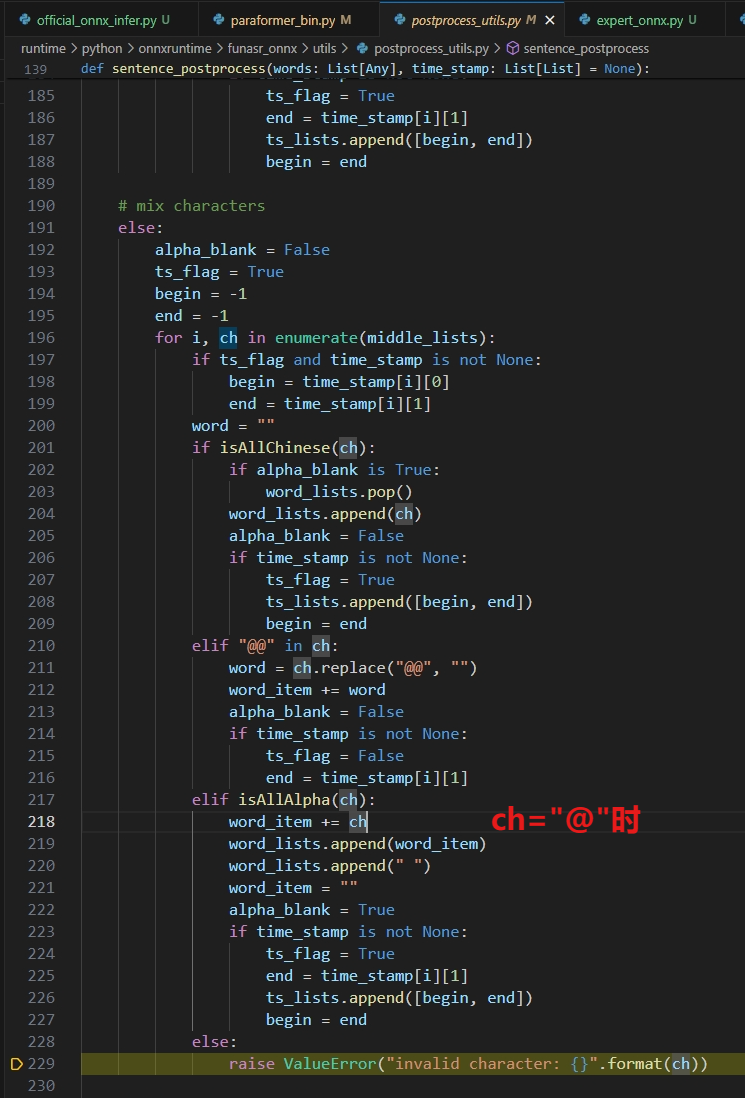
根据您描述的问题,modelscope-funasr的finetune训练的ONNX模型在推理时遇到“@”字符会报错:ValueError: invalid character: @,而使用官方下载的模型时,“@”被正确识别为“艾特”。这表明问题可能与finetune训练过程中对特殊字符的处理方式有关。以下是对此问题的详细分析和解决方案:
1. 问题分析
-
现象描述:
- Finetune后的ONNX模型无法处理“@”字符,导致程序报错。
- 官方模型能够正确将“@”识别为“艾特”。
-
可能原因:
-
字符集不匹配:
- Finetune训练时使用的字符集(词汇表)可能未包含“@”字符,导致模型在推理时无法映射该字符。
- 官方模型可能在预训练阶段已经包含了“@”字符及其对应的映射规则。
-
后处理逻辑差异:
- 模型输出的文本可能需要经过后处理(如解码或标准化),如果finetune后的模型缺少对“@”字符的后处理规则,可能会导致错误。
-
数据预处理问题:
- Finetune训练时,输入数据中可能未包含“@”字符,导致模型未能学习到如何处理该字符。
2. 解决方案
步骤一:检查字符集(词汇表)
- 确认finetune训练时使用的字符集是否包含“@”字符。
- 如果字符集缺失“@”,需要更新字符集并重新训练模型。
- 操作建议:
- 打开finetune训练配置文件,检查
label_map_path参数是否指定了正确的类别映射文件。
- 在类别映射文件中添加“@”字符及其对应的标签(如“艾特”)。
- 重新生成训练数据,并确保训练数据中包含“@”字符的样本。
步骤二:验证后处理逻辑
- 检查模型推理时的后处理逻辑,确保其能够正确处理“@”字符。
- 如果后处理逻辑存在问题,可以参考官方模型的实现进行修改。
- 操作建议:
- 查看推理代码中是否有针对特殊字符的映射规则。
- 如果没有,可以手动添加规则,例如将“@”映射为“艾特”。
步骤三:补充训练数据
- 如果finetune训练数据中缺乏“@”字符的样本,可能导致模型无法学习到该字符的特征。
- 操作建议:
- 收集包含“@”字符的音频数据,并标注为“艾特”。
- 将这些数据加入训练集,重新进行finetune训练。
步骤四:调试与验证
- 在完成上述修改后,重新导出ONNX模型并进行推理测试。
- 验证模型是否能够正确识别“@”字符,并输出“艾特”。
3. 重要提醒
- 字符集一致性:确保训练、评估和推理阶段使用的字符集完全一致,避免因字符集不匹配导致的错误。
- 后处理规则:对于特殊字符(如“@”、“#”等),建议在后处理阶段统一处理,以提高模型的鲁棒性。
- 官方支持:如果您已提交issue(如issue1671),建议持续关注官方回复,可能需要官方提供更详细的字符集或后处理规则。
4. 总结
此问题并非典型的bug,而是由于finetune训练过程中对特殊字符的处理不足导致的。通过更新字符集、完善后处理逻辑以及补充训练数据,可以有效解决该问题。如果问题仍未解决,建议联系官方技术支持,获取进一步的帮助。您可以复制页面截图提供更多信息,我可以进一步帮您分析问题原因。