
"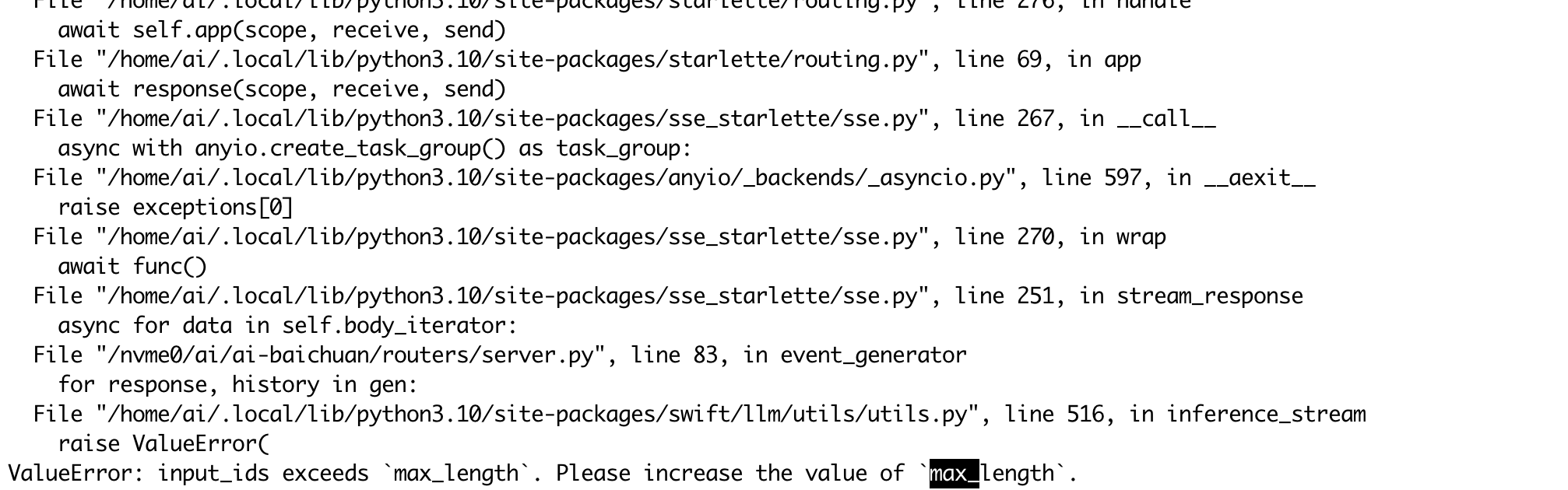
ModelScope模型长度 swift 能控制么 ?"
在ModelScope中,使用Swift微调和部署大语言模型时,是否能够控制模型长度取决于具体的模型配置和推理参数设置。以下是详细说明:
模型长度通常指输入或输出文本的最大Token数量(即上下文长度)。对于大语言模型,这一参数直接影响生成文本的长度以及模型对长上下文的理解能力。
在Swift微调过程中,您可以通过以下方式间接影响模型长度: - 训练数据的截断与填充:在准备训练数据时,您可以对输入序列进行截断或填充,以确保其符合模型支持的最大长度。例如,某些模型可能默认支持最大长度为2048个Token,您可以在数据预处理阶段调整输入长度。 - 模型配置文件修改:部分模型允许通过修改配置文件(如max_position_embeddings)来调整最大上下文长度。但需要注意,这可能会导致模型性能下降或需要重新训练。
在推理阶段,Swift部署的模型通常允许通过请求参数动态控制生成文本的长度。例如: - max_length 或 max_new_tokens 参数:这些参数用于限制生成文本的最大长度。您可以在发送推理请求时指定这些参数,从而控制输出长度。 - 示例代码:
import requests
service_url = 'YOUR_SERVICE_URL'
token = 'YOUR_SERVICE_TOKEN'
# 请求参数中设置最大生成长度
request_data = {
"text_input": "人工智能是什么?",
"parameters": {
"max_new_tokens": 50, # 控制生成文本的最大长度
"temperature": 0.7
}
}
response = requests.post(
service_url,
headers={"Authorization": token, "Content-Type": "application/json"},
json=request_data
)
print(response.json())
在上述代码中,max_new_tokens 参数被设置为50,表示生成的文本最多包含50个Token。
在ModelScope中使用Swift微调和部署大语言模型时,可以通过推理参数(如max_new_tokens)动态控制生成文本的长度。然而,模型的最大上下文长度由其架构决定,无法超出默认限制。如果需要更灵活的长度控制,建议选择支持长上下文的模型或对模型进行定制化修改。
如果您有进一步的具体需求或问题,请提供更多细节以便我们为您提供更精确的解答。
ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!欢迎加入技术交流群:微信公众号:魔搭ModelScope社区,钉钉答疑群:44837352
