
我用测试onnx模型的样例代码测试本地某一文件夹下存储的相同类型音频时,有的音频可以,但是有的音频有报错,modelscope-funasr这是什么原因?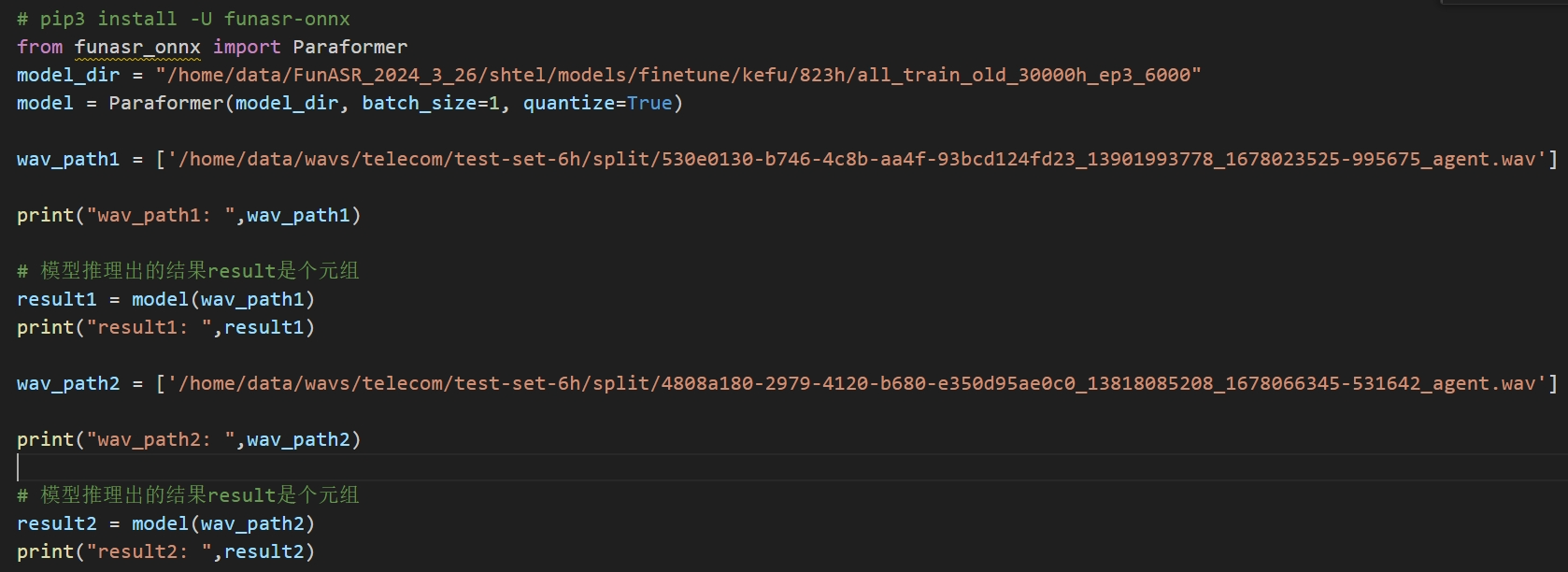
报错是: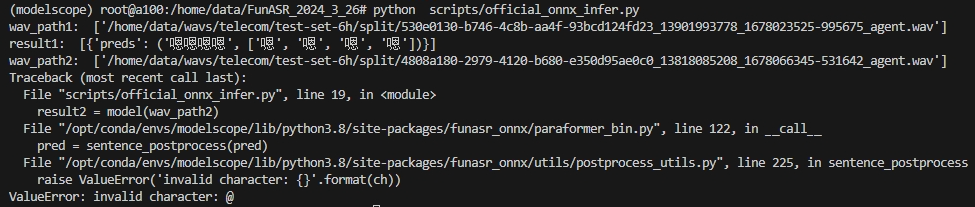
根据您提供的信息,您在使用 modelscope-funasr 测试 ONNX 模型时,部分音频文件可以正常处理,但部分音频文件报错。以下是可能的原因分析及解决方法:
不同的音频文件可能存在格式、采样率、位深度等参数的差异。如果某些音频文件的格式或编码不符合模型的要求,可能会导致报错。
FunASR 的模型通常对输入音频有严格的格式要求,例如采样率(如 16kHz)、单声道、PCM 编码等。如果音频文件的参数不匹配,模型可能无法正确解析。ffmpeg)批量转换音频文件格式。示例命令如下:
ffmpeg -i input_audio_file -ar 16000 -ac 1 -sample_fmt s16 output_audio_file.wav
某些音频文件可能由于录制、存储或传输过程中出现问题而损坏,导致模型无法正确读取。
ffprobe 或 sox)检查音频文件是否完整。示例命令如下:
ffprobe input_audio_file
ONNX 模型对输入数据的长度或内容可能有特定限制。如果某些音频文件的长度超出模型支持的范围,可能会导致报错。
解决方法:
对于超长音频,可以将其分割为多个短音频片段进行处理。示例代码如下:
from pydub import AudioSegment
audio = AudioSegment.from_file("input_audio_file.wav")
chunk_length_ms = 30000 # 每段音频长度(毫秒)
chunks = [audio[i:i + chunk_length_ms] for i in range(0, len(audio), chunk_length_ms)]
for idx, chunk in enumerate(chunks):
chunk.export(f"chunk_{idx}.wav", format="wav")
modelscope-funasr 及其依赖库的版本可能与您的环境不完全兼容,导致某些音频文件处理失败。
modelscope-funasr 和相关依赖库。可以通过以下命令更新:
pip install --upgrade funasr[clip]
如果模型加载或初始化过程中存在问题,可能导致部分音频文件无法正确处理。
如果上述方法均无法解决问题,可能是以下原因导致: - 硬件资源不足:处理大文件或复杂音频时,可能需要更多的内存或计算资源。 - 模型本身的问题:某些模型可能存在已知的 Bug 或限制。
modelscope-funasr 的官方文档或社区论坛,确认是否存在类似问题的解决方案。根据知识库资料,modelscope-funasr 的安装和使用需要满足特定的环境要求,并且对输入音频的格式和内容有严格限制。建议您按照以下步骤逐一排查问题: 1. 统一音频文件格式(采样率、位深度、声道)。 2. 检查音频文件是否损坏。 3. 确认音频长度是否超出模型限制。 4. 更新依赖库并检查环境配置。 5. 添加日志以定位具体问题。
如果问题仍未解决,请提供具体的错误日志和音频文件信息,以便进一步分析。您可以复制页面截图提供更多信息,我可以进一步帮您分析问题原因。
