
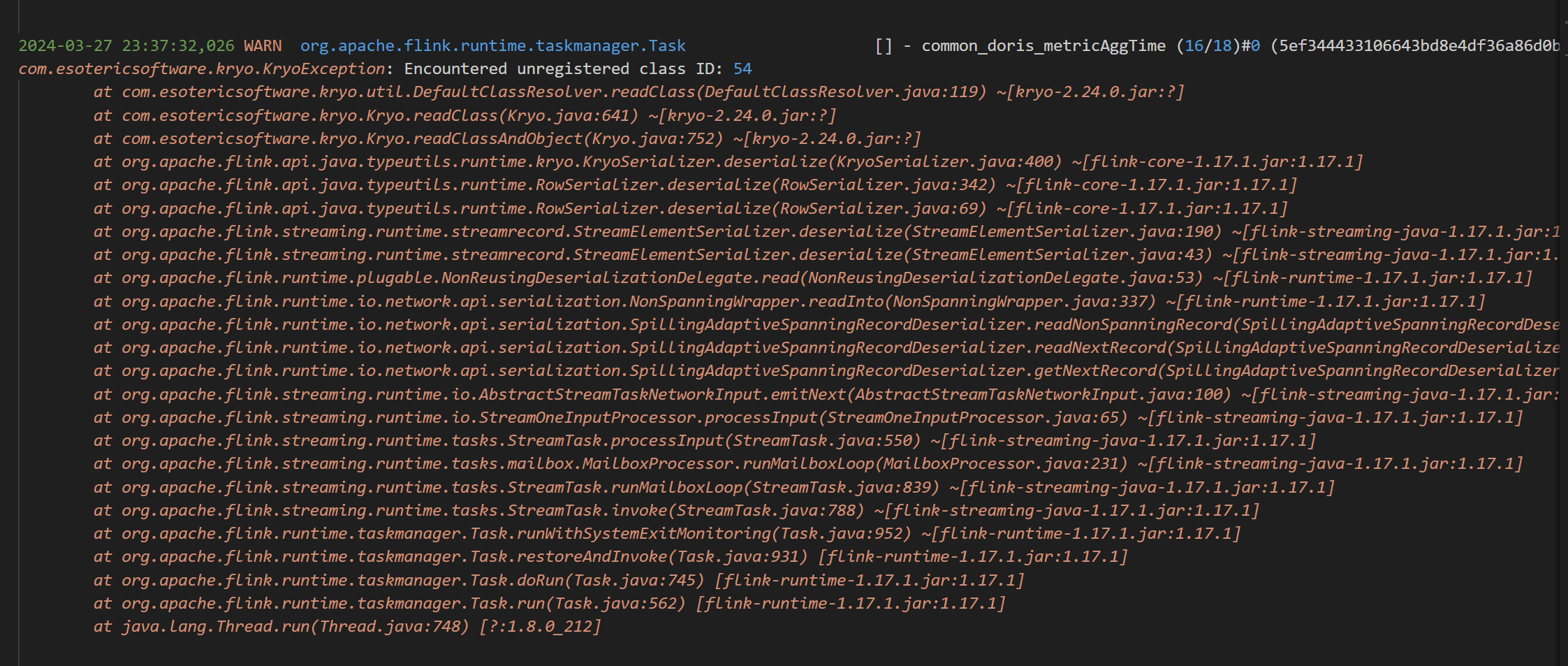
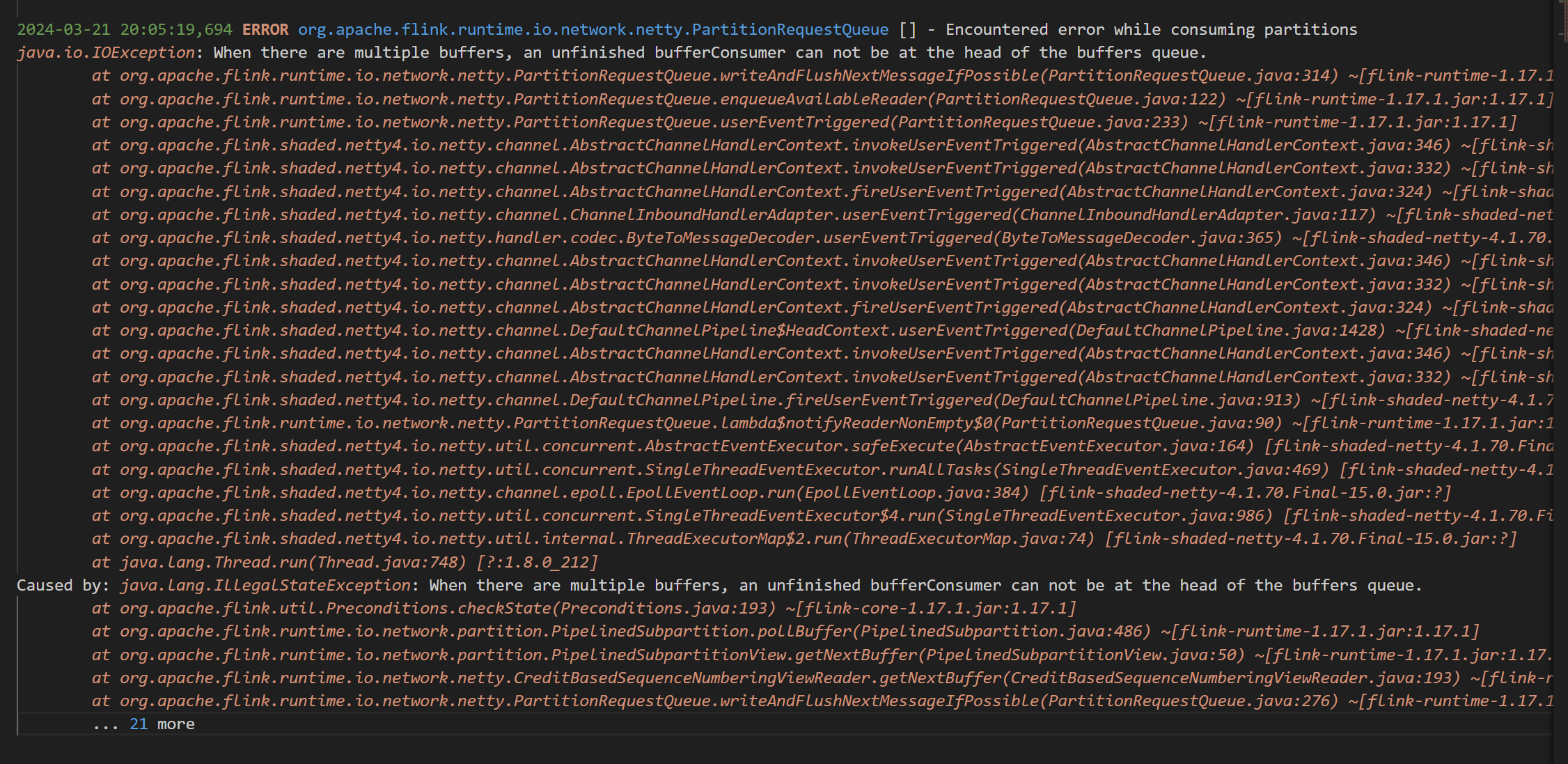
Flink 这个对应的场景是,keyBy分组,然后进行反序列化的时候报错,请问这个有人知道为啥吗?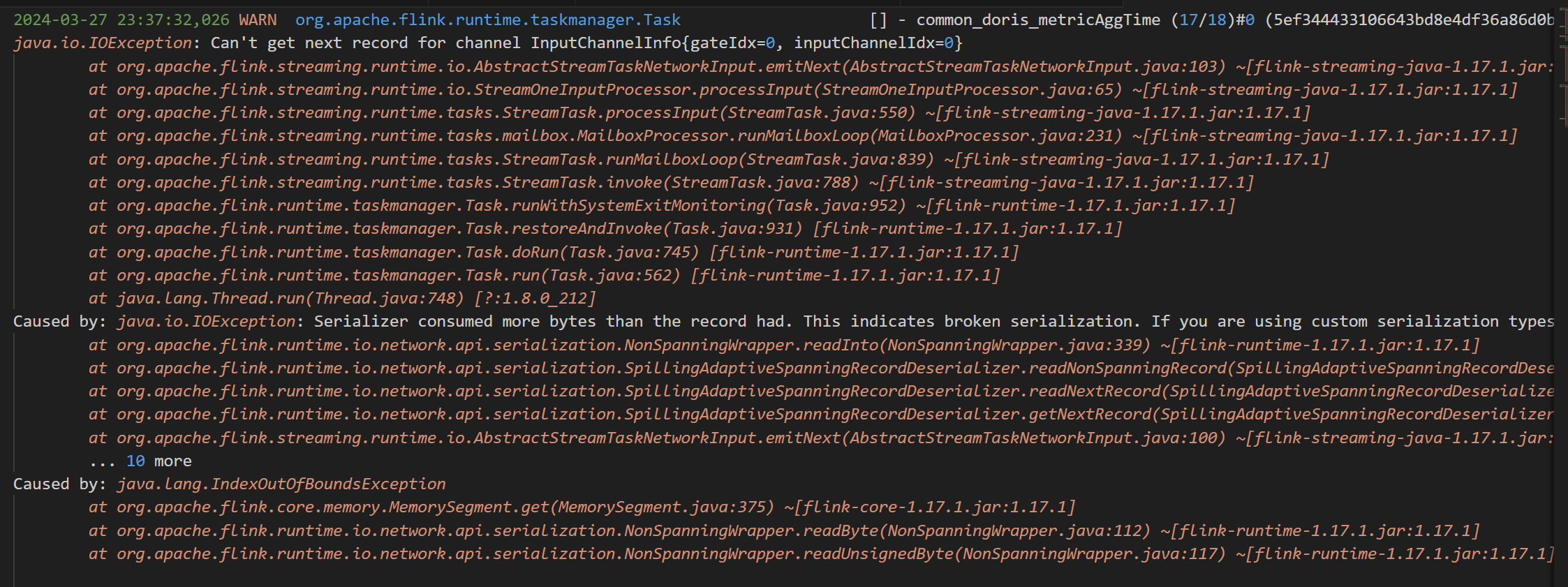

版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在 Flink 作业中,keyBy 分组后进行反序列化时出现报错,可能的原因和解决方案如下:
如果 keyBy 的字段类型与实际数据中的类型不一致,可能会导致反序列化失败。例如,声明的类型比实际数据类型更宽泛或不兼容时,Flink 无法正确解析数据。
keyBy 字段的类型是否与数据源中的实际类型一致。CREATE TABLE source_table (
id BIGINT, -- 确保类型与实际数据一致
name STRING,
price DECIMAL(18, 2)
) WITH (
'connector' = 'kafka',
'format' = 'json'
);
如果实际数据中 price 是 DOUBLE 类型,而您声明为 DECIMAL,则需要调整为正确的类型。
如果您使用了自定义的反序列化器(如 JSON、Avro 等),可能是反序列化逻辑中存在错误,导致无法正确解析数据。
json.ignore-parse-errors 参数来忽略解析错误的数据:
WITH (
'format' = 'json',
'json.ignore-parse-errors' = 'true'
)
这样可以避免因单条数据格式错误导致整个任务失败。
如果您的作业依赖了多个版本的库(如 org.codehaus.janino.CompilerFactory),可能会导致类加载冲突,从而引发反序列化错误。
org.codehaus.janino.CompilerFactory 是否被重复加载。classloader.parent-first-patterns.additional: org.codehaus.janino
具体操作步骤如下: 1. 进入运维中心 > 作业运维页面。 2. 单击目标作业名称,进入部署详情页签。 3. 在其他配置文本框中添加上述参数,并保存。
如果数据源中的字段是嵌套结构(如 JSON 嵌套对象),而您未正确展开嵌套列,可能会导致反序列化失败。
在源表 DDL 中启用嵌套列展开功能:
WITH (
'json.infer-schema.flatten-nested-columns.enable' = 'true'
)
这会将嵌套列展开至顶层,避免因嵌套结构导致的解析错误。
如果只需要提取特定嵌套字段,可以使用 JSON_VALUE 函数:
SELECT
JSON_VALUE(properties, '$.rowkey') AS rowkey
FROM source_table;
如果 keyBy 的字段值为空(如 NULL),可能会导致反序列化失败。
keyBy 字段是否存在空值。WHERE key_column IS NOT NULL
如果 TaskManager 的内存不足,可能会导致反序列化过程中出现异常。
taskmanager.memory.process.size: 4g
如果您使用了社区版的内部 API 或依赖了非公开方法,可能会因版本差异导致反序列化失败。
@Public 或 @PublicEvolving 的方法。根据上述分析,您可以按照以下步骤排查问题: 1. 检查 keyBy 字段的类型是否与实际数据一致。 2. 确认是否启用了正确的嵌套列解析方式。 3. 检查是否存在类加载冲突,并通过配置解决。 4. 确保数据中不存在空值或格式错误。 5. 检查资源是否充足,必要时增加内存或 CPU 配置。
如果问题仍未解决,请提供具体的报错日志,以便进一步分析。您可以复制页面截图提供更多信息,我可以进一步帮您分析问题原因。
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。

