请教flink专家,同一个partition下的数据,使用flinksql deduplicate算子 如果分组键变化 是否会引发乱序 ?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在Flink SQL中,使用DEDUPlication算子(或简称为deduplicate)处理数据时,其设计目的是为了去除指定分组键下的重复记录,确保每个分组键值对应的记录是唯一的。关于您的问题,如果分组键发生变化,理论上不会直接引发数据在同一个partition内的乱序问题。这是因为deduplicate操作是基于分组键进行的,它关注的是如何在每个分组内去重,而不是改变数据的原始顺序。
然而,需要注意的是,数据在进入DEDUPlication算子之前的操作,比如shuffle过程,可能会因为网络延迟、任务调度等因素导致数据在不同分区间的乱序。此外,如果上游算子处理逻辑复杂,特别是涉及到多路复用或多步转换,也可能间接影响到数据的有序性,尽管这不直接由deduplicate操作引起。
总结来说,分组键的变化本身不直接导致乱序,但整个数据流的处理链路,包括数据的重组、转换等步骤,都可能影响数据的顺序。确保数据有序通常需要结合恰当的数据分区策略、排序保证以及选择合适的时间窗口或 watermark机制来共同完成。
Flink SQL中的DEDUPicate算子(或DISTINCT)基于分组键进行去重,如果分组键变化,数据会被重新分区,这可能导致数据重新排序,因为在分布式处理中,不同的分区键可能对应不同的并行任务处理。这种重分区可能会引入乱序,特别是如果您的数据有时间顺序敏感的依赖。为了保持顺序,您可能需要使用Window或ProcessFunction等操作,并结合Watermark来处理时间事件的顺序。
Apache Flink 在处理流数据时,默认保证的是事件时间的排序,而不是处理时间或摄入时间的排序。当数据在同一个分区(partition)内流动时,如果按照某个键进行分组(keyBy),Flink 会尽力保持这个键内部的顺序。但是,如果分组键发生变化,是否会导致乱序取决于几个因素:
事件时间戳:如果事件时间戳是递增的,并且你的应用程序是以事件时间处理(Event Time Processing),那么即使键发生变化,也不会导致乱序问题。
水位线:在 Event Time 处理模式下,水位线(Watermark)对于保证事件的时间顺序至关重要。只要水位线正确生成并且能够反映事件的真实时间顺序,键的变化通常不会导致乱序。
并行度和重分区:如果数据在不同的分区之间移动(例如通过 keyBy 操作符重新分区),那么即使键不变也可能出现乱序,因为不同分区的数据可能会以不同的速率到达。
下面是一个简单的示例来说明这些概念: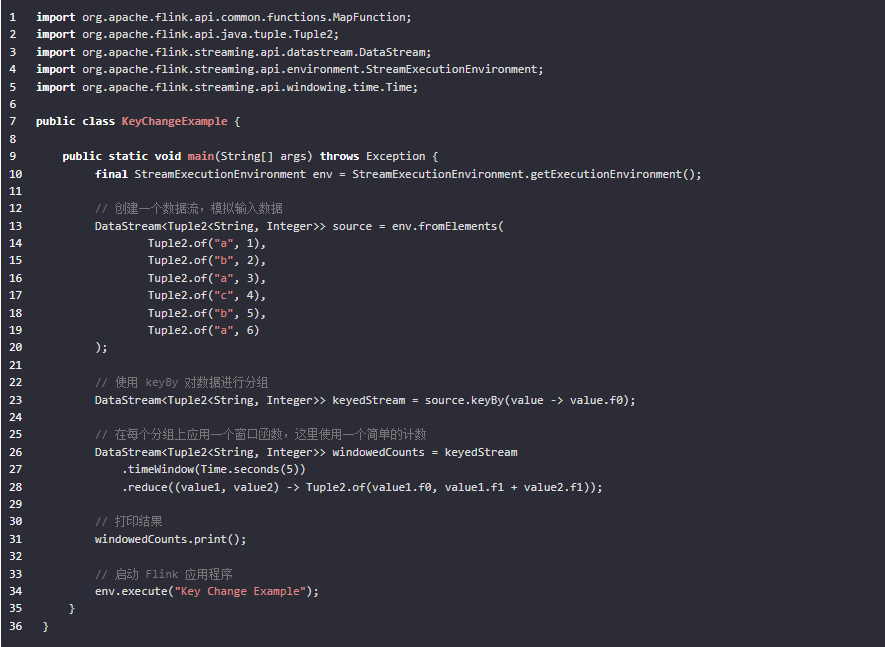
在这个例子中,我们创建了一个包含不同键的简单数据流。我们使用 keyBy 将数据按键分组,并对每个键使用一个 5 秒的时间窗口来计算该键出现的次数。由于我们使用了事件时间窗口,并且数据本身是有序的,所以即使键发生了变化,输出仍然会保持正确的顺序。
请注意,在实际部署时,为了确保事件时间的正确处理,你可能需要配置水位线策略。此外,如果你的应用涉及多个分区,还需要注意数据的重分区可能导致的潜在乱序问题。
在Flink处理数据时,如果数据在同一个partition内且基于相同的分组键进行处理,理论上不应出现因分组键变化而导致的乱序问题。这是因为Flink在处理具有相同分组键的数据时,会保证这些数据在同一个task中顺序处理,
然而,当涉及到shuffle操作,即数据在不同的task之间重新分布时,如果分组键(或者说upsert键)的唯一排序属性被破坏,就可能在下游引发处理上的复杂度,需要通过特定的算法或机制(如SinkUpsertMaterializer)来处理乱序事件,以确保结果的一致性和正确性
可以参考一下阿里云的这个文章

网络延迟、资源分配、作业配置、集群负载 都会影响。
检查作业提交流程是否有可以优化的地方,比如减少启动脚本的复杂性。
分组键发生变化,Flink 仍然会根据当前的键进行分区,但新的键可能意味着数据被发送到不同的分区,这可能会导致乱序。
同一个partition下的数据,如果分组键变化,是有可能引发乱序的**。这是因为分组操作(如GroupBy)可能会在内部执行shuffle,以确保相同分组键的数据汇聚到同一任务实例处理。这一过程破坏了原始数据进入partition时的顺序,尤其是当分组键频繁变化,或者在分组后直接进行join、窗口聚合等操作时,数据的时序性可能无法保持。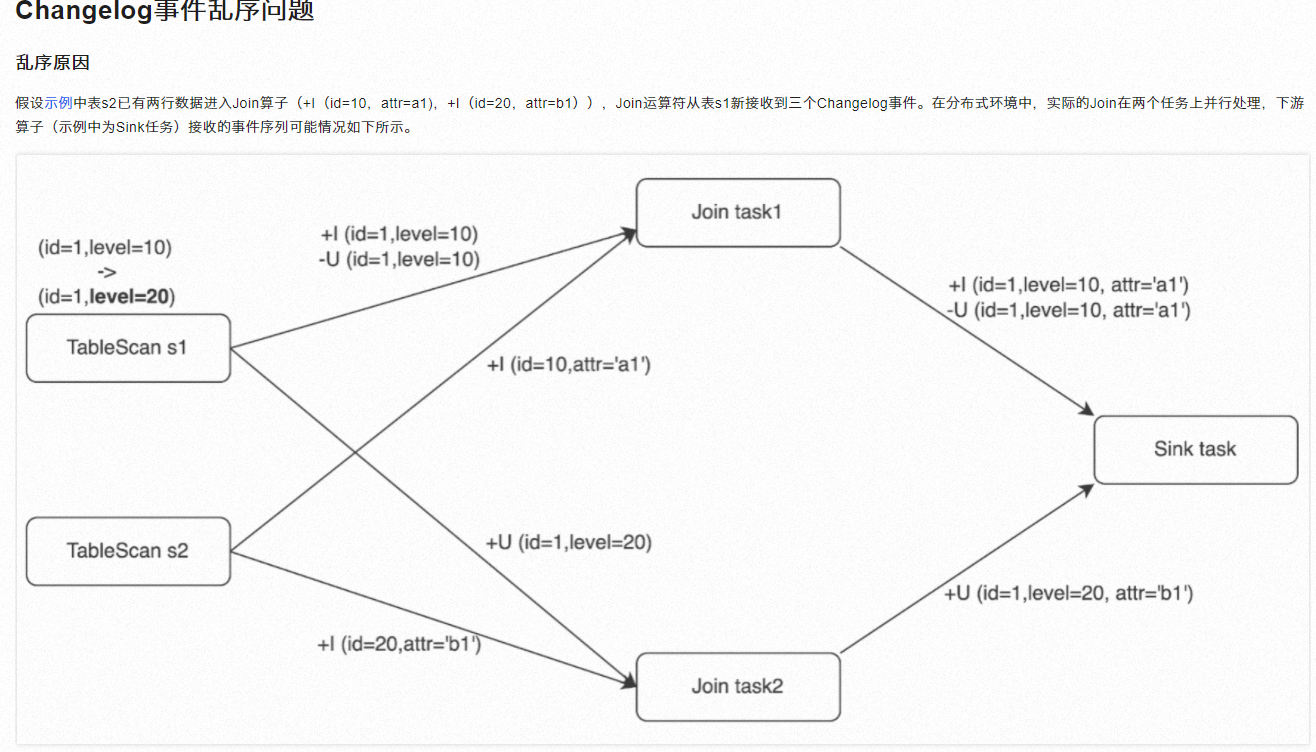
相关链接
https://help.aliyun.com/zh/flink/use-cases/processing-changelog-events-out-of-orderness-in-flink-sql
Flink SQL 中的 DEDUPLICATE 算子主要用于处理流数据中的重复记录,基于定义的分组键(GROUP BY)和事件时间窗口(或Processing Time窗口)来实现去重。当处理同一个partition下的数据时,如果分组键(grouping keys)发生变化,确实可能影响数据处理的顺序,但这不是由于DEDUPLICATE算子直接引起的乱序,而是因为分组键的变化改变了数据如何被分组和处理的逻辑。
具体来说:
分组键变化的影响:分组键定义了数据如何被划分到不同的组中进行处理。如果分组键变化,原本属于同一组的数据现在可能被分到了不同的组中,这意味着它们将在不同的分区或窗口中被独立处理。这种变化不会直接导致内部处理的乱序,因为Flink在内部保证了每个key的事件是有序处理的(基于事件时间或处理时间),但不同key之间的事件处理顺序则不保证。
窗口与去重:DEDUPLICATE算子在窗口上下文中工作时,会根据定义的窗口大小(如滚动窗口、滑动窗口)对数据进行分组。如果分组键改变,窗口内的数据集合也会随之变化,这可能间接影响到去重的结果。例如,原来在同一窗口内的两条重复记录,现在可能因为分组键的不同而落入了不同的窗口,从而影响去重效果。
顺序与乱序:Flink的乱序通常指的是事件时间乱序,即实际处理事件的时间顺序与事件本身携带的时间戳顺序不一致。DEDUPLICATE算子本身处理的是去重逻辑,不会直接造成事件处理的乱序。但如果上游数据源本身就是乱序的,或是因为网络延迟等原因导致数据到达Flink时已经乱序,那么这可能会间接影响去重的准确性,尤其是在结合事件时间窗口使用时。
总结而言,分组键的变化会影响数据如何被分组和在哪些窗口中进行去重处理,但这不直接导致数据处理的内部乱序。为了确保正确的去重逻辑和预期的处理顺序,需要合理设计分组键和窗口策略,并考虑数据流的特性(如是否包含乱序事件)。
在 Apache Flink SQL 中使用 DEDUP 算子时,它会在每个分区内根据定义的分组键去重。DEDUP 算子要求输入数据在时间戳上是有序的,并且这种有序性需要在每个分组键内部保持一致。当数据在一个 partition 内,且分组键发生变化时,DEDUP 算子会为每个分组键独立地进行去重操作。这意味着,当分组键变化时,只要新分组键的数据仍然遵循时间戳的有序性,DEDUP 操作本身不会引发乱序。但是如果数据流中的分组键变化没有正确地按时间戳排序,或者有迟到的数据,这可能会导致 DEDUP 算子误判,因为迟到的数据可能被误认为是重复数据而被丢弃。下面是一个简化的示例场景,说明了数据流如何在 DEDUP 运算符中处理分组键的变化: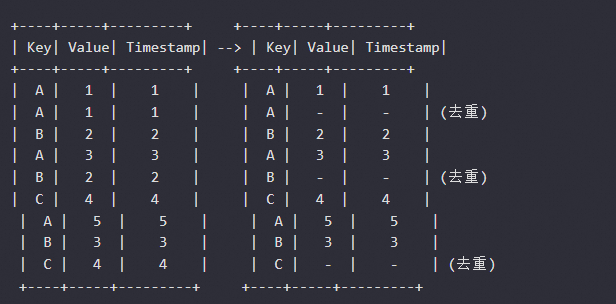
在这个例子中,Key 字段用作分组键,Timestamp 字段用于排序。可以看到,当 Key 从 A 变化到 B,再变化到 C 时,DEDUP 操作在每个 Key 下独立进行。当 Key 变化时,假设数据是按时间戳有序的,DEDUP 不会引入乱序。然而在实际情况中,如果数据流中的事件不是严格有序的,或者有迟到的事件,DEDUP 可能会导致数据丢失或不正确的去重。因此为了确保 DEDUP 的正确行为,数据流必须是有序的,并且任何迟到的事件都应通过水位线机制适当地处理。
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。