
请问一下大数据计算MaxCompute,这个pyodps write_table 支持的records数据类型是什么? odps.dataframe ,array , list 好像试了都有问题,是我姿势错了么?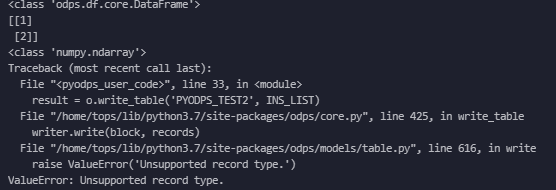
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在大数据计算MaxCompute的PyODPS中,write_table 函数支持的数据类型包括:
write_table时遇到了问题,可能是因为数据类型不匹配或者转换过程中出现了错误。请确保您的数据类型与目标表的结构一致,并且数据格式正确。如果问题依旧存在,建议查阅最新的PyODPS开发文档或联系技术支持获取帮助。在大数据计算MaxCompute中,使用PyODPS的write_table方法时,通常支持的数据类型包括字典(dict)、Pandas DataFrame以及NumPy数组等。如果您在使用这些数据类型时遇到问题,可能是因为数据格式不符合预期或者编程方式有误。
为了确保write_table方法能够正确执行,您可以尝试以下步骤:
write_table方法的具体用法和参数要求。需要注意的是,由于MaxCompute和PyODPS的版本更新可能会导致API的变化,因此请确保您使用的SDK版本与官方文档相匹配。
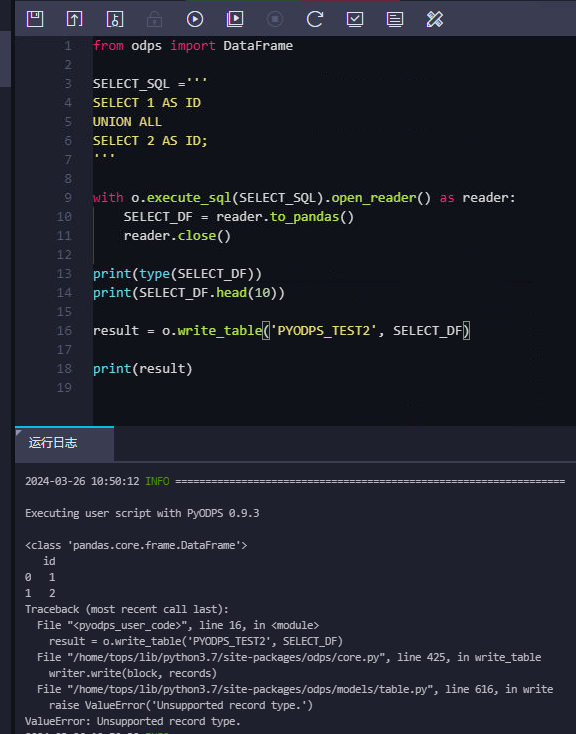
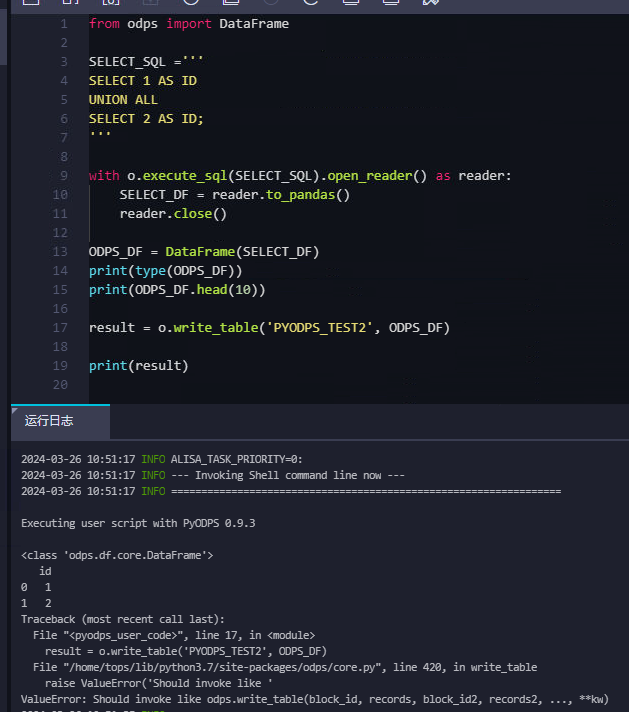
write_table仅支持 list和arrow 格式,你这个pyodps df肯定不行https://help.aliyun.com/zh/maxcompute/user-guide/tables?spm=a2c4g.11186623.0.0.5f2c6aderJd5h6#section-djb-brl-cfb ,此回答整理自钉群“MaxCompute开发者社区2群”
在 MaxCompute (ODPS) 的 pyodps SDK 中,write_table 方法用于将数据写入到 MaxCompute 的表中。这个方法支持多种数据类型作为输入,但具体支持的数据类型取决于你要写入的 MaxCompute 表的结构。
一般来说,write_table 方法接受以下类型的数据作为输入:
import pandas as pd
from odps import ODPS
odps = ODPS('<access_id>', '<access_key>', '<project>', endpoint='<endpoint>')
table = odps.get_table('<table_name>')
# 创建一个 Pandas DataFrame
df = pd.DataFrame({
'col1': [1, 2, 3],
'col2': ['a', 'b', 'c']
})
# 将 DataFrame 写入到 MaxCompute 表中
with table.open_writer(partition_spec='<partition_value>', blocks=1) as writer:
writer.write(df)
data = [
[1, 'a'],
[2, 'b'],
[3, 'c']
]
with table.open_writer(partition_spec='<partition_value>', blocks=1) as writer:
writer.write(data)
data = [
(1, 'a'),
(2, 'b'),
(3, 'c')
]
with table.open_writer(partition_spec='<partition_value>', blocks=1) as writer:
writer.write(data)
data = [
{'col1': 1, 'col2': 'a'},
{'col1': 2, 'col2': 'b'},
{'col1': 3, 'col2': 'c'}
]
with table.open_writer(partition_spec='<partition_value>', blocks=1) as writer:
writer.write(data)
请注意,在使用 write_table 方法时,你需要确保输入数据的结构与 MaxCompute 表的结构相匹配,包括字段名和数据类型。如果数据类型不匹配,你可能会遇到错误。
如果你尝试使用 odps.dataframe、普通的数组(array)或列表作为输入,并且遇到了问题,那么很可能是因为这些数据类型与 MaxCompute 表的结构不匹配。确保你使用的数据类型与表结构兼容,并检查是否有任何字段名或数据类型不匹配的情况。
MaxCompute支持的records数据类型包括1.0数据类型、2.0数据类型以及Hive兼容数据类型。
在大数据计算中,MaxCompute作为一种服务,提供了丰富的数据类型来满足不同的数据处理需求。具体到records数据类型,它通常用于表示结构化数据,其中每个record由一系列字段组成,每个字段都有自己的数据类型。
对于您提到的pyodps write_table方法支持的records数据类型,这通常涉及到DataFrame的写入操作。在MaxCompute中,DataFrame是一种二维数据结构,类似于数据库中的表,它可以包含多种数据类型的列。因此,当使用write_table方法时,您应该确保您的数据结构与MaxCompute支持的数据类型兼容。如果您在使用odps.dataframe、array或list时遇到问题,可能是因为这些数据结构与MaxCompute期望的数据格式不匹配,或者需要在写入之前进行一些转换。
此外,为了确保数据能够成功写入,建议您检查以下几点:
综上所述,如果问题依旧存在,建议查阅官方文档或联系技术支持以获取更详细的指导。
在大数据计算MaxCompute中,pyodps的write_table函数支持的records数据类型是MaxCompute表的Record对象列表。
在使用`write_table您需要创建一个Record对象列表,每个Record对象包含要写入表格的数据。具体步骤如下:
get_table方法获取一个表对象。2. 创建Record对象:然后,您可以使用表对象的new_record方法创建Record对象并将数据作为列表传递给它。open_writ打开表的写入器,并使用write方法将Record对象列表写入表中。例如,如果您有一个名为'test_table'的表,并且想要写入一些数据,您可以这样做:
from odps import ODPS
o = ODPS(...) # 使用您的Access Key ID和Secret Access Key创建ODPS对象
t = o.get_table('test_table')
with t.open_writer(partition='pt1=test1,pt2=test2') as writer:
records = [
t.new_record([111, 'aaa', True]),
t.new_record([222, 'bbb', False]),
t.new_record([333, 'ccc', True]),
t.new_record([444, '中文', False])
]
writer.write(records)
请注意,Record对象中的数据顺序和类型应与表的列顺序和类型相匹配。如果遇到问题,请检查您的数据是否与表的结构一致,以及是否正确使用了new_record方法来创建Record对象。
MaxCompute(原ODPS)是一项面向分析的大数据计算服务,它以Serverless架构提供快速、全托管的在线数据仓库服务,消除传统数据平台在资源扩展性和弹性方面的限制,最小化用户运维投入,使您经济并高效的分析处理海量数据。


