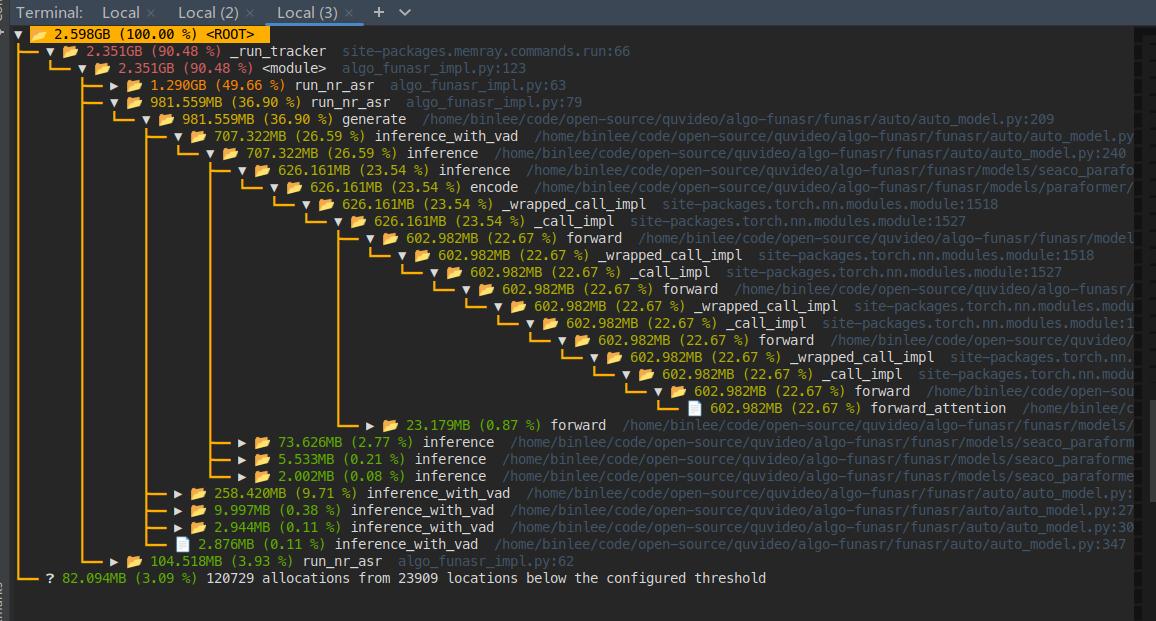
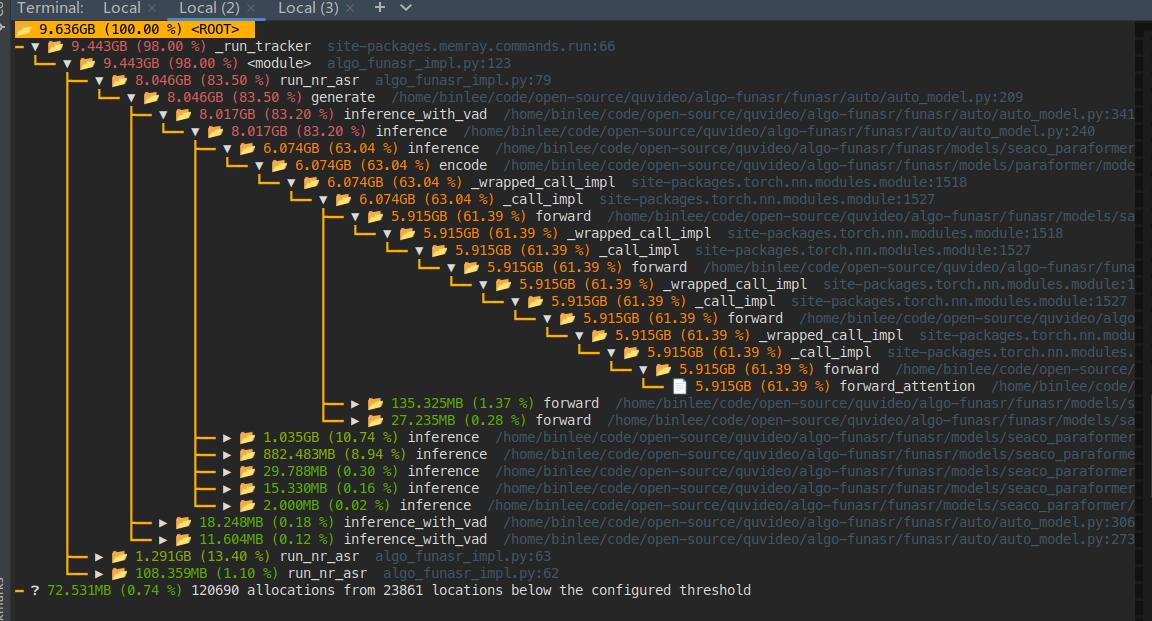
要解决在使用ModelScope-FunASR处理5分钟音频时需要10 GB内存的问题,可以从以下几个方面进行优化和调整:
1. 优化模型推理的内存占用
- 检查模型版本:确保您使用的FunASR模型是经过量化或优化的版本。例如,某些模型可能提供FP16(半精度浮点数)或INT8(整数量化)版本,这些版本通常会显著降低内存需求。
- 调整推理参数:
- 减少
batch_size:如果推理过程中使用了较大的批量大小,尝试将其设置为1或更小值,以减少内存占用。
- 调整
max_length:限制输入音频的最大长度,避免一次性加载过长的音频数据。
2. 扩展实例资源
- 增加实例规格:如果当前实例的内存不足以支持推理任务,可以考虑升级实例规格。例如,选择具有更高内存配置的GPU云服务器或ACK集群节点。
- 挂载OSS存储:将模型文件存储在阿里云对象存储(OSS)中,并通过挂载方式访问模型文件,从而减少本地内存的占用。
3. 分片处理音频文件
4. 优化JVM内存配置(如果适用)
- 如果您的推理服务运行在Java虚拟机(JVM)环境中,可以通过以下方式优化内存配置:
- 调整堆内存大小:适当减小JVM堆内存大小,为系统组件预留更多内存。例如:
-Xms4g -Xmx4g
- 设置MaxRAMPercentage:确保
-XX:MaxRAMPercentage参数值为浮点数(如70.0),以避免JDK 8的Bug导致启动失败。
5. 使用高性能部署方案
- 如果您使用的是阿里云EAS(弹性推理服务),可以选择高性能部署模式,并挂载自定义模型。这种方式能够更好地利用硬件资源,提升推理效率并降低内存占用。
- 操作步骤:
- 将优化后的模型文件上传至OSS。
- 在EAS控制台中选择高性能部署,并指定OSS路径中的模型文件。
6. 监控与调试
- 监控内存使用情况:使用阿里云提供的监控工具(如ARMS或CloudMonitor)实时查看内存使用情况,定位内存瓶颈。
- 启用日志记录:开启详细的日志记录功能,分析推理过程中的内存分配和释放行为,进一步优化代码逻辑。
总结建议
通过上述方法,您可以从模型优化、资源扩展、音频分片处理以及JVM配置等多个角度解决内存不足的问题。如果问题仍然存在,建议联系阿里云技术支持团队,获取更专业的帮助。