
Flink CDC 里遇到这种情况怎么调优?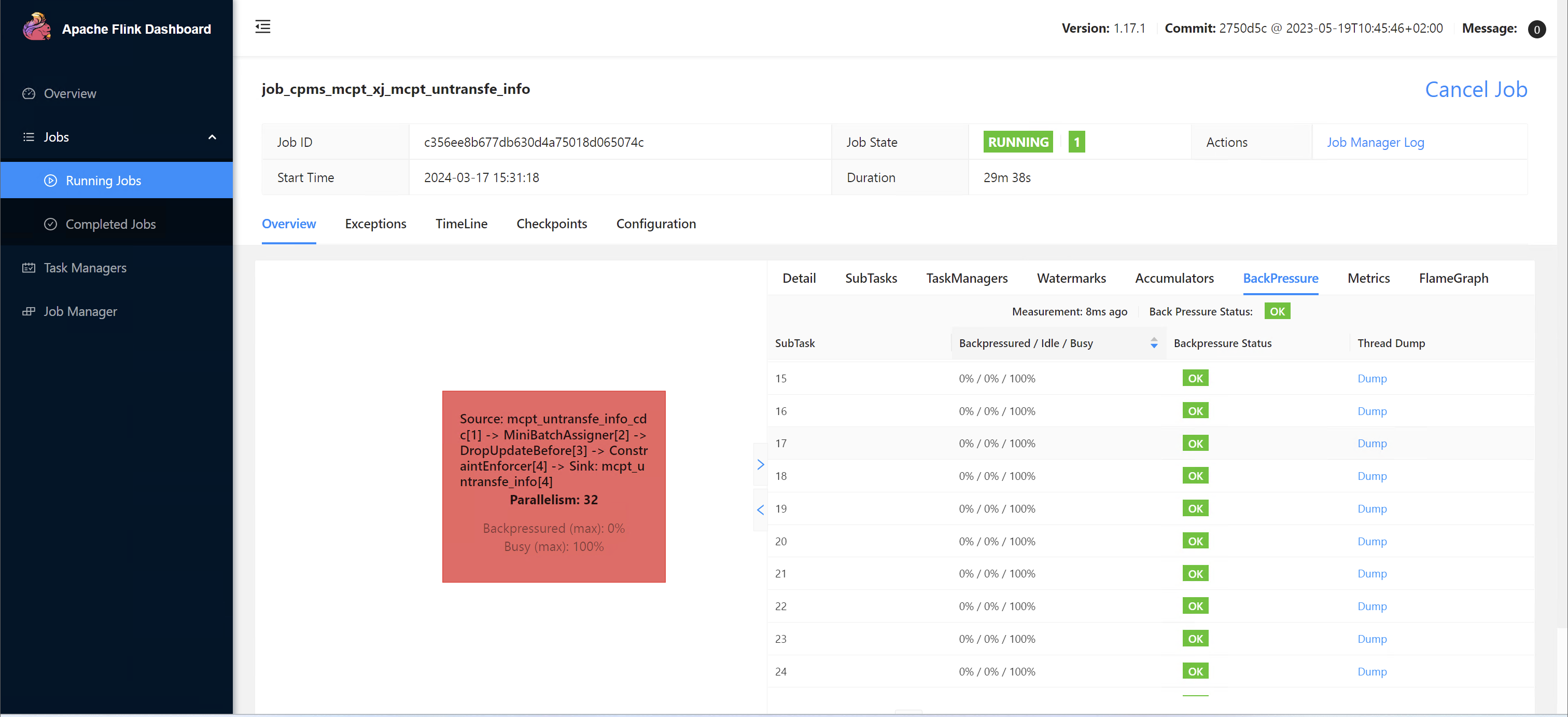 busy 100%32个线程.
busy 100%32个线程.
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在Flink CDC作业中遇到busy 1002个线程的情况,通常表明作业的并发度或资源分配存在问题,导致线程数过高,可能引发性能瓶颈或资源浪费。以下是针对该问题的调优方法和建议:
高线程数通常与作业的并发度设置密切相关。以下是一些关键点和调优方法:
全局并行度调整
全局并行度决定了作业中任务的最大并行执行数量。如果并行度过高,可能导致线程数激增。建议根据数据规模和资源情况合理设置全局并行度。
execution.batch.adaptive.auto-parallelism.max-parallelism=128
execution.batch.adaptive.auto-parallelism.avg-data-volume-per-task=16MiB
这些参数可以帮助系统动态调整并行度,避免资源浪费。
Source和Sink并发度调整
对于CDC场景,Source和Sink的并发度对线程数影响较大。可以通过SQL Hints调整并发度:
/*+ OPTIONS('scan.parallelism'='8') */
SELECT * FROM source_table;
或者调整Sink并发度:
/*+ OPTIONS('sink.parallelism'='8') */
INSERT INTO sink_table SELECT * FROM source_table;
Flink CDC作业中,状态算子的生成和管理会显著影响线程数和资源消耗。以下是相关优化建议:
避免不必要的状态算子
Flink SQL优化器可能会自动生成一些状态算子(如ChangelogNormalize、SinkUpsertMaterializer等)。如果确认这些算子并非必要,可以通过配置项禁用它们。例如:
table.exec.sink.upsert-materialize=none
这可以减少状态算子的生成,从而降低线程数。
状态清理机制优化
确保状态算子的状态清理机制正常工作。例如,对于基于TTL的状态算子(如Deduplicate),需要正确配置TTL参数以避免状态无限增长。
资源配置不合理可能导致线程数过高或资源争用。以下是具体优化建议:
TaskManager资源配置
每个TaskManager的Slot数量和资源分配直接影响线程数。建议根据作业规模合理配置:
最大Slot数量限制
配置Flink作业允许分配的最大Slot数量,避免资源过度占用:
taskmanager.numberOfTaskSlots=4
如果手动调优复杂且耗时,可以启用Flink的智能调优功能,让系统自动调整资源配置和并发度:
智能调优模式
在Source无延迟、无反压的情况下,如果发现CPU和内存使用率较低,可以启用智能调优模式。系统会根据资源使用率动态调整资源配置,避免资源浪费。
定时调优模式
如果作业负载具有明显的高峰和低谷特征,可以使用定时调优功能。例如:
在CDC场景中,数据倾斜和小文件问题可能导致部分节点线程数过高:
检查数据倾斜
如果数据分布不均,可能导致部分节点线程数过高。可以通过调整sink.parallelism参数引入数据重分布(Shuffle),解决数据倾斜问题。
优化小文件处理
小文件过多会增加归并过程的代价,导致线程数激增。可以通过以下方式优化:
最后,建议通过监控工具(如Flink Web UI)分析作业运行情况,定位线程数过高的具体原因:
通过以上方法,您可以有效降低Flink CDC作业中的线程数,提升作业性能和资源利用率。
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。

