
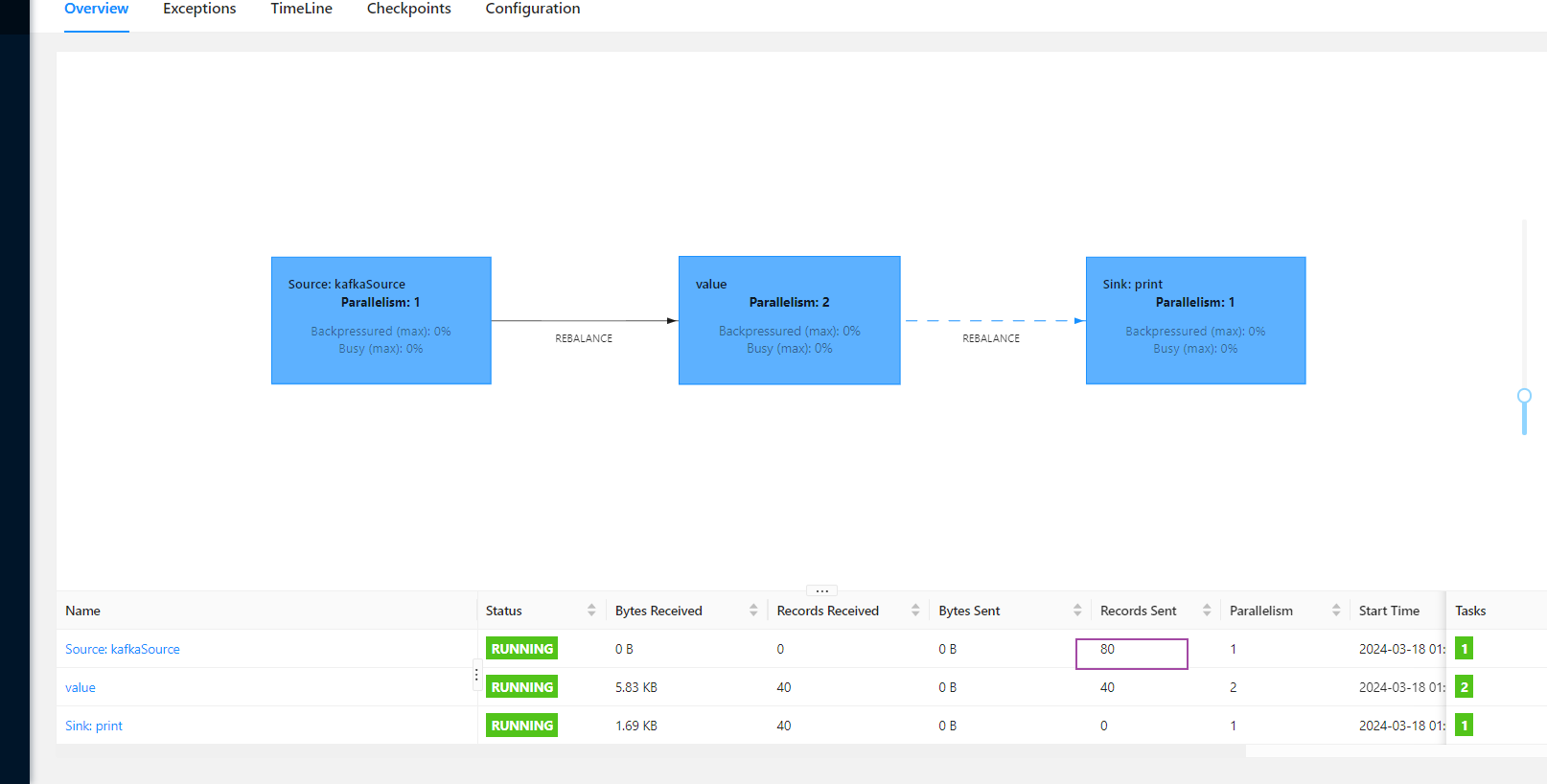
如图我的kafka里只有40条数据,但是webUi中显示Records Sent 80,求解为什么?
这是我flink消费kafka的代码
package com.xiaziyang.source;
import com.alibaba.fastjson.JSONObject;
import com.xiaziyang.deserializer.MyKafkaDeserializationSchema;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.serialization.DeserializationSchema;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.common.serialization.TypeInformationSerializationSchema;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
import org.apache.flink.connector.kafka.source.reader.deserializer.KafkaRecordDeserializationSchema;
import org.apache.flink.shaded.jackson2.com.fasterxml.jackson.databind.node.ObjectNode;
import org.apache.flink.streaming.api.datastream.DataStreamSink;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.KafkaDeserializationSchema;
import org.apache.flink.streaming.util.serialization.JSONKeyValueDeserializationSchema;
import org.apache.flink.types.Row;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import java.io.IOException;
import java.lang.reflect.Type;
public class MyKafkaSource {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.createRemoteEnvironment("hadoop103", 8081,"C:\\JavaStudy\\flink-1.17\\target\\original-flink-1.17-1.0-SNAPSHOT.jar");
KafkaSource<ConsumerRecord<String, String>> kafkaSource = KafkaSource.<ConsumerRecord<String, String>>builder().setBootstrapServers("hadoop102:9092")
.setTopics("flink_1")
.setGroupId("xiaziyang1")
.setStartingOffsets(OffsetsInitializer.latest())
.setDeserializer(KafkaRecordDeserializationSchema.of(new MyKafkaDeserializationSchema()))
.build();
SingleOutputStreamOperator<ConsumerRecord<String, String>> source = env.fromSource(kafkaSource, WatermarkStrategy.noWatermarks(),"kafkaSource")
.name("kafkaSource").setParallelism(1);
SingleOutputStreamOperator<String> map = source.map(new MapFunction<ConsumerRecord<String, String>, String>() {
@Override
public String map(ConsumerRecord<String, String> value) throws Exception {
return value.value().toString();
}
}).name("value").setParallelism(2);
DataStreamSink<String> sink = map.print().name("print").setParallelism(1);
env.execute();
}
}
这个是自定义的kafka反序列器(应该和这个没关系,我用simpleString那个也会有webUI显示数据量翻倍的问题)
package com.xiaziyang.deserializer;
import org.apache.flink.api.common.serialization.DeserializationSchema;
import org.apache.flink.api.common.typeinfo.TypeHint;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.streaming.connectors.kafka.KafkaDeserializationSchema;
import org.apache.flink.util.Collector;
import org.apache.kafka.clients.consumer.ConsumerRecord;
public class MyKafkaDeserializationSchema implements KafkaDeserializationSchema<ConsumerRecord<String, String>> {
@Override
public boolean isEndOfStream(ConsumerRecord<String, String> nextElement) {
return false;
}
@Override
public ConsumerRecord<String, String> deserialize(ConsumerRecord<byte[], byte[]> record) throws Exception {
// System.out.println(record.topic()+" "+record.offset()+" "+ record.key()+ " "+record.value()+" "+record.headers());
ConsumerRecord consumerRecord = new ConsumerRecord(record.topic(),
record.partition(),
record.offset(),
new String(record.key(), "UTF-8"),
new String(record.value(), "UTF-8"));
return consumerRecord;
}
@Override
public TypeInformation<ConsumerRecord<String, String>> getProducedType() {
return TypeInformation.of(new TypeHint<ConsumerRecord<String, String>>(){});
}
}
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
出现这种情况的原因可能在于你的Flink作业设置和数据处理逻辑。
并行度设置:在您的代码中,source和map操作的并行度分别为1和2。这意味着每个source分区的数据可能会被map算子处理两次(如果topic中有两个分区,则完全匹配这个情况)。每次map操作都会产生一个输出记录,因此原始的40条记录会被映射为80条记录。请注意,只有当source与map之间存在非一对一的数据传输时才会发生这种情况。
检查消费行为:请确保没有其他因素导致每条消息被消费两次。例如,检查Flink任务配置、Kafka消费者组状态以及是否有重复订阅的情况。
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。


