
Flink CDC 里这种错误怎么配置?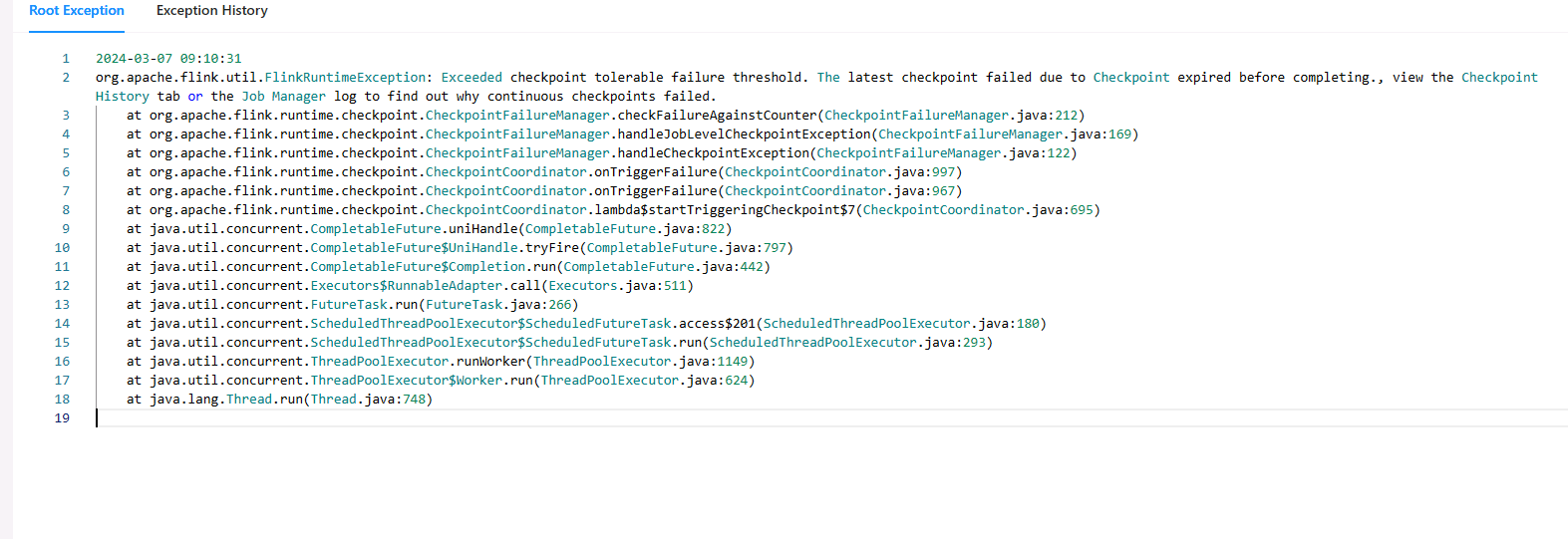
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在使用 Flink CDC 时,可能会遇到各种错误。根据您提供的知识库资料,以下是一些常见错误及其配置解决方案的详细说明:
问题原因:
Postgres CDC 连接器在运行过程中创建了 Replication Slot,但作业停止后未正确释放该 Slot,导致其仍然处于活动状态。
解决方案:
- 手动释放 Slot:
执行以下 SQL 命令删除指定的 Replication Slot:
SELECT pg_drop_replication_slot('rep_slot');
'debezium.slot.drop.on.stop' = 'true'
问题原因:
MySQL 的 Binlog 格式为 Mixed 或 Statement,而 Flink CDC 要求 Binlog 格式为 ROW。
解决方案:
将 MySQL 的 Binlog 格式设置为 ROW:
SHOW VARIABLES LIKE "binlog_format";
SET GLOBAL binlog_format=ROW;
问题原因:
连接器无法识别某些表的 Schema,可能是因为数据库用户权限不足或未正确初始化快照。
解决方案:
1. 确保使用的数据库用户具有对应作业中所有数据库的相应权限。 2. 避免使用 'debezium.snapshot.mode'='never' 参数,改为以下配置以避免报错:
'debezium.inconsistent.schema.handling.mode' = 'warn'
io.debezium.connector.mysql.MySqlSchema WARN 的相关信息,并根据提示处理无法解析的变更事件。问题原因:
MySQL 服务器上的 Binlog 文件过期时间太短,或者 Flink CDC 处理 Binlog 的速度过慢,导致需要读取的 Binlog 已被清理。
解决方案:
1. 增加 Binlog 的保留时间(例如设置为保留 7 天):
SHOW VARIABLES LIKE 'expire_logs_days';
SET GLOBAL expire_logs_days=7;
问题原因:
在非正常情况下(如故障发生),CDC 工具(如 Canal、Debezium、Maxwell)只能保证 at-least-once 的投递语义,可能导致重复的变更事件被投递到 Kafka 中。
解决方案:
在 Flink 作业中启用去重机制: 1. 设置作业参数以启用去重功能:
table.exec.source.cdc-events-duplicate=true
问题原因:
MongoDB 用户凭证是在特定数据库下创建的,而 Flink CDC 默认尝试在其他数据库下进行身份验证。
解决方案:
在 MongoDB CDC 的 WITH 参数中添加以下配置,指定正确的认证数据库:
'connection.options' = 'authSource=用户所在的DB'
问题原因:
Resume Token 对应的记录在 oplog.rs 中已不存在,可能是由于 oplog.rs 的保留时间过短。
解决方案:
1. 增加 oplog.rs 的集合大小,确保其保留时间足够长。 2. 参考 MongoDB 官方文档调整 oplog.rs 的大小。
问题原因:
- 使用的是 RDS MySQL 5.6 备库或只读实例,这些实例未向日志文件写入数据。 - 全量阶段读取时间过长,导致最后一个分片数据量过大,出现 OOM 问题。 - Checkpoint 间隔时间设置过大,导致作业卡住。
解决方案:
1. 使用可写实例或升级 RDS MySQL 至更高版本。 2. 增加 MySQL Source 端的并发,加快全量读取速度。 3. 根据业务情况设置合理的 Checkpoint 间隔时间。
问题原因:
CDC 作业中配置的 server-time-zone 参数与 MySQL 服务器时区不一致。
解决方案:
在 DataStream 中使用自定义序列化器时,确保 serverTimeZone 参数正确配置时区信息。
以上是针对 Flink CDC 常见错误的配置解决方案。如果您的问题未包含在上述内容中,请提供更多具体错误信息以便进一步分析和解决。
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。

