
modelscope-funasr这个长音频版本,汇合了 VAD 和 ASR,但是我生成的还是没有标点 ,为什么?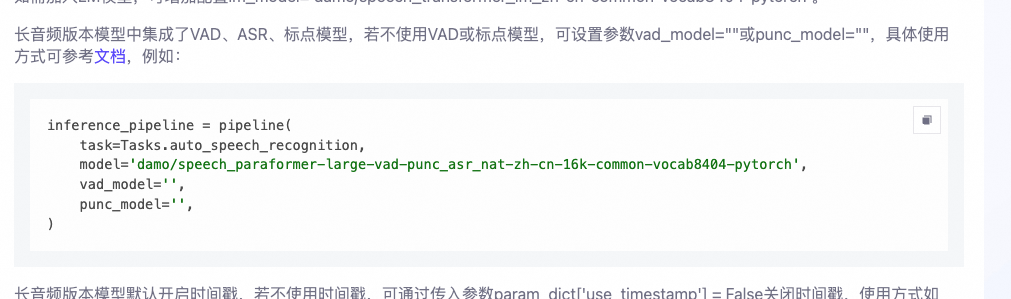
https://www.modelscope.cn/models/iic/speech_paraformer-large-vad-punc_asr_nat-zh-cn-16k-common-vocab8404-pytorch/summary 
from funasr import AutoModel
model = AutoModel(
model="/mnt/merchant/hub_models/modelscope/speech_paraformer-large-vad-punc_asr_nat-zh-cn-16k-common-vocab8404-pytorch", model_revision="v2.0.2"
)
res = model.generate(input='test.wav', batch_size_s=1)
print(res)
根据您提供的代码和描述,您使用的是 speech_paraformer-large-vad-punc_asr_nat-zh-cn-16k-common-vocab8404-pytorch 模型,并且希望生成的语音识别结果包含标点符号。然而,实际输出中没有标点符号。以下是可能的原因及解决方案:
该模型支持 VAD(语音活动检测)、ASR(自动语音识别)和标点恢复(Punctuation Recovery)。但这些功能需要在调用时显式启用。
在调用 AutoModel.generate 方法时,确保传递了正确的参数以启用标点功能。例如,您可以尝试以下代码:
res = model.generate(
input='test.wav',
batch_size_s=1,
param_dict={"use_punc": True} # 显式启用标点功能
)
print(res)
注意:param_dict 参数用于控制模型的功能开关,其中 "use_punc": True 表示启用标点恢复功能。
如果输入音频的采样率或格式不符合模型要求,可能会导致标点功能无法正常工作。
ffmpeg -i input.wav -ar 16000 -ac 1 output.wav
您使用的模型版本为 v2.0.2,需要确认该版本是否完全支持标点恢复功能。
v2.0.2 是否包含标点恢复功能。model = AutoModel(
model="/mnt/merchant/hub_models/modelscope/speech_paraformer-large-vad-punc_asr_nat-zh-cn-16k-common-vocab8404-pytorch",
model_revision="master" # 使用最新版本
)
标点恢复功能可能依赖于额外的模块或库。如果相关依赖未正确安装,可能导致功能失效。
funasr 的标点功能可能依赖于 transformers 或其他 NLP 库。可以通过以下命令安装:
pip install -r requirements.txt
funasr 包:
pip install --upgrade funasr
如果上述方法均无效,建议通过调试和日志分析进一步排查问题。
generate 方法时,启用调试模式以查看详细日志:
res = model.generate(
input='test.wav',
batch_size_s=1,
param_dict={"use_punc": True, "debug": True}
)
print(res)
通过以上步骤,您可以逐步排查并解决标点功能失效的问题。重点在于: 1. 显式启用标点功能(通过 param_dict 参数)。 2. 确保音频格式符合要求(16kHz、16bit、单声道)。 3. 验证模型版本和依赖配置。
如果问题仍未解决,请提供更多上下文信息(如完整日志或音频样本),以便进一步分析。
