
在使用ofa的ocr模型识别手写体文字时,怎么增加vocab.txt中没有的字,因为模型自带的只有5000+文字,我想增加到近20000字,我使用的add_tokens方法,但推理时报如下错误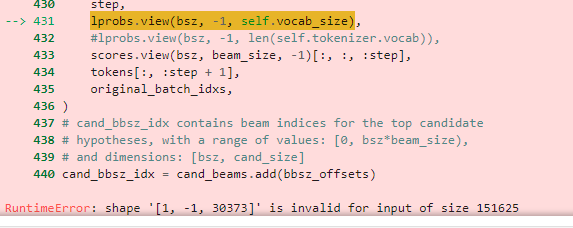
不知如何处理。感谢各位大神
解决这个问题,你可以尝试以下步骤:
确保你已经正确地将新字符添加到了词汇表文件(vocab.txt)。请检查文件中的字符顺序和数量是否与你期望的一致。
更新模型配置文件(config.yaml),确保词汇表大小与vocab.txt中的字符数量匹配。例如,如果你的vocab.txt中有近20000个字符,则需要将配置文件中的vocab_size设置为20000。
使用更新后的配置文件重新加载模型。这将确保模型知道新的词汇表大小,并能够正确处理输入。
检查输入数据的形状是否与模型的预期输入形状匹配。根据你提供的错误信息,输入形状 [1, -1, 30373] 不符合模型的预期。请确保输入数据的形状正确无误。

