
modelscope-funasr参考的这段代码,设置total_chunk_num-5 后报错了,怎么解决?https://github.com/alibaba-damo-academy/FunASR/blob/main/examples/industrial_data_pretraining/paraformer_streaming/demo.py 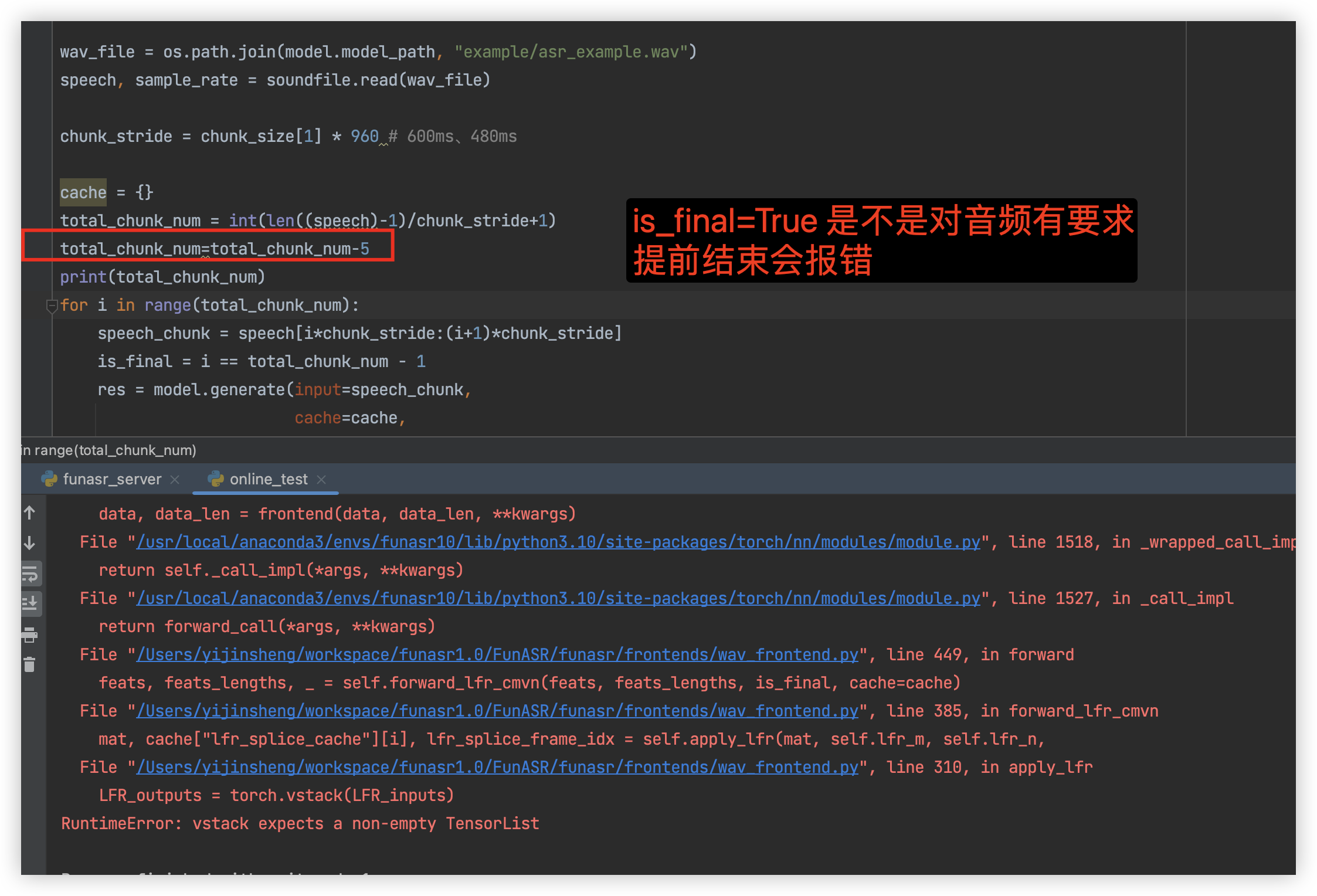
在使用 modelscope-funasr 的代码时,如果设置了 total_chunk_num=5 后报错,可能是由于以下原因导致的。以下是详细的分析和解决方法:
total_chunk_num 参数通常用于控制音频分块的数量,尤其是在流式语音识别任务中。设置该参数后报错,可能的原因包括: - 参数值不匹配:total_chunk_num 的值可能与模型或数据预处理逻辑不兼容。 - 依赖版本问题:某些依赖库(如 funasr 或 torch)的版本可能不支持当前参数配置。 - 输入数据格式错误:音频数据的分块逻辑可能未正确实现,导致分块数量与预期不符。
根据知识库中的信息,FunASR 是一个基于 PyTorch 的工具包,其安装和运行需要满足特定的环境要求。因此,问题可能与环境配置或代码逻辑有关。
确保 total_chunk_num 的值符合模型的要求。可以通过以下方式验证: - 查看 demo.py 文件中对 total_chunk_num 的定义和使用逻辑。 - 确保音频数据的总长度能够被正确分割为指定的块数。例如,如果音频长度不足以分成 5 块,可能会导致错误。
确保所有依赖库的版本是最新的,并与 FunASR 兼容。可以按照以下步骤操作: 1. 更新 funasr 和相关依赖:
pip install --upgrade funasr[clip]
python -c "import torch; print(torch.__version__)"
如果问题仍然存在,可以通过以下方式调试代码: 1. 在 demo.py 中添加日志,打印 total_chunk_num 和音频分块的相关信息:
print(f"Total chunk number: {total_chunk_num}")
print(f"Audio chunks: {audio_chunks}")
根据知识库中的信息,FunASR 的运行需要 Python 3.7 或更高版本,并且需要安装 PyTorch 和其他依赖包。请确保您的环境满足以下要求: - Python 版本:python --version - PyTorch 安装:pip show torch
如果上述方法无法解决问题,建议参考 FunASR 的官方文档或示例代码,确认 total_chunk_num 的正确用法。您可以在本地克隆代码仓库并查看相关示例:
git clone https://github.com/alibaba-damo-academy/FunASR.git
cd FunASR/examples/industrial_data_pretraining/paraformer_streaming
total_chunk_num 的值应根据音频长度和模型要求合理设置,避免超出范围。通过以上步骤,您应该能够解决 total_chunk_num=5 设置后报错的问题。如果问题仍未解决,请提供具体的错误信息或日志,以便进一步分析。您可以复制页面截图提供更多信息,我可以进一步帮您分析问题原因。
