
在视觉智能平台中我需要一个图像识别的能力同时可以把这些物体的标签和坐标返回给我,如何解决?
在视觉智能平台中我需要一个图像识别的能力:
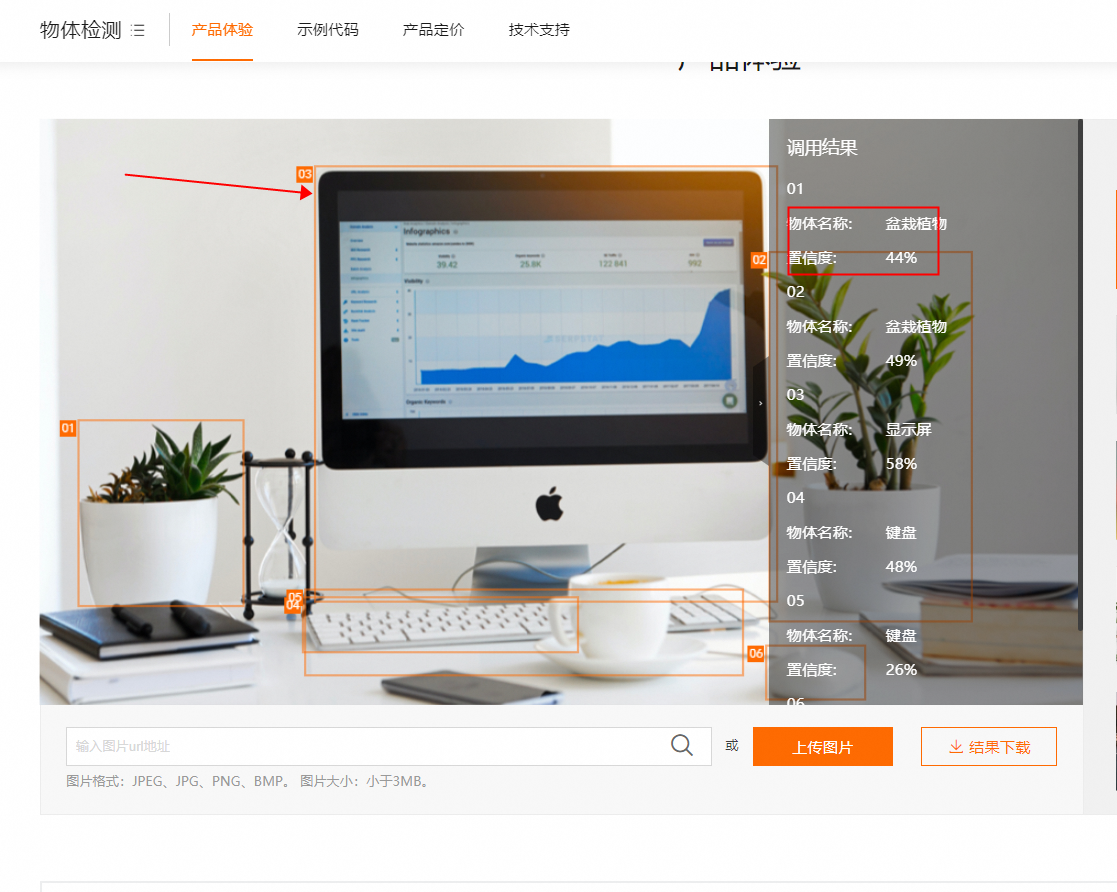
可以识别图片中多个动物物体,包括猫、狗、人、鱼等,同时可以把这些物体的标签和坐标返回给我,如何解决?
-

在视觉智能平台中,要实现图像识别并返回多个动物物体的标签和坐标,通常需要使用计算机视觉技术和深度学习模型。以下是解决此问题的一种可能方法:
1.选择适当的计算机视觉库:首先,选择一个适合您需求的计算机视觉库。一些流行的选择包括OpenCV、TensorFlow和PyTorch。这些库提供了各种工具和函数,可用于图像处理、特征提取和物体检测。
2.收集和标注数据:为了训练模型,您需要一个包含多种动物物体的标注数据集。这些数据集应包含各种动物物体的图像,并标注有物体的标签和边界框坐标。您可以使用公开的数据集(如ImageNet、COCO等),或自行收集和标注数据。
3.训练物体检测模型:使用标注的数据集来训练一个物体检测模型。您可以选择预训练的模型(如Faster R-CNN、YOLO、SSD等)作为起点,然后使用您的数据集进行微调,使其能够识别特定的动物物体。
4.模型推理与物体检测:使用训练好的模型进行推理,对输入的图像进行物体检测。模型将分析图像内容,并返回识别出的动物物体的标签和边界框坐标。
5.后处理与结果提取:根据模型的输出,您可能需要执行一些后处理操作,以提取所需的标签和坐标信息。这可能包括解析模型的输出、对坐标进行修正或过滤等步骤。
6.集成与应用:将整个流程集成到您的视觉智能平台中,使其能够实时处理图像,并返回多个动物物体的标签和坐标。确保您的平台具备良好的扩展性和性能,以适应不同输入图像的大小和复杂性。2024-01-24 16:24:50赞同 展开评论 打赏 -
 2024-01-24 13:27:54赞同 展开评论 打赏
2024-01-24 13:27:54赞同 展开评论 打赏 -
参考链接:
https://vision.aliyun.com/experience/detail?spm=a2cvz.27726026.J_7524944390.22.771850b5Yh9B9h&tagName=objectdet&children=DetectObject 。此回答整理来自钉群“阿里云视觉智能开放平台咨询1群”2024-01-24 12:09:34赞同 展开评论 打赏

版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。


