
modelscope-funasr音频没有结束,但提前发送结束标志的情况,怎么解决?
modelscope-funasr音频没有结束,但提前发送结束标志的情况,怎么解决?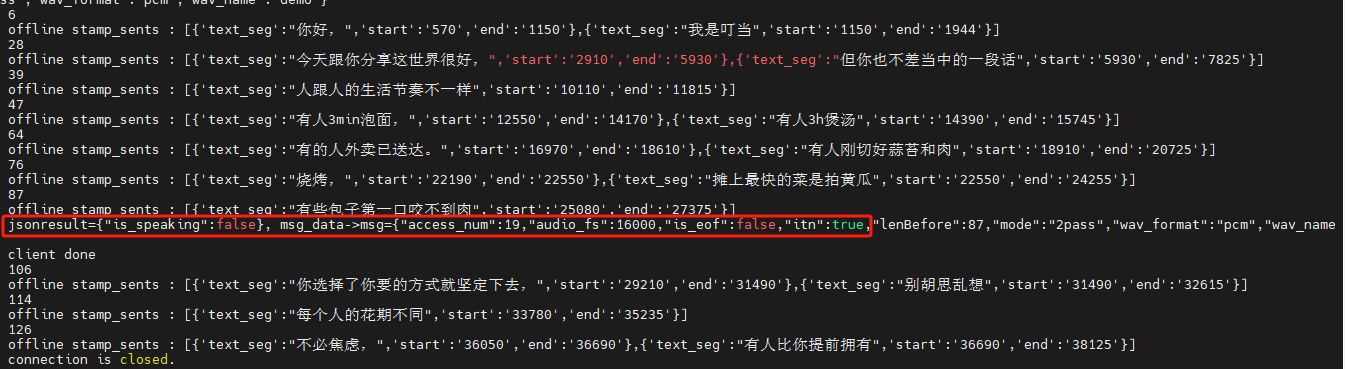
-
面对过去,不要迷离;面对未来,不必彷徨;活在今天,你只要把自己完全展示给别人看。
如果在使用modelscope-funasr时,音频没有播放完毕却提前发送了结束标志,你可以尝试调整模型参数。具体来说,你可以修改"max_single_segment_time"参数的值。这个参数代表VAD(语音活动检测)最大切割音频的时长,以毫秒为单位。例如,如果你将此值增大,那么在遇到长音频时,模型会有更大的容忍度去处理那些长度超过阈值的音频段,可能有助于解决你所遇到的问题。但请注意,这只是一个可能的解决方案,具体是否适用还需要根据实际情况进行尝试和评估。
2024-01-13 13:38:10赞同 展开评论 -
如果在使用modelscope-funasr时,音频没有结束但提前发送了结束标志,可能会导致识别结果不准确或无法识别。为了解决这个问题,您可以尝试以下方法:
增加音频长度:如果可能的话,尝试增加音频的长度,以确保模型有足够的时间来处理完整的语音信号。这可以通过在录音时延长录音时间或使用更长的音频文件来实现。
调整模型参数:您可以尝试调整FunASR模型中的一些参数,例如帧长、帧移等,以适应您的音频数据。这些参数可以根据您的具体需求进行调整,以提高模型对未结束音频的处理能力。
使用其他模型:如果您发现FunASR模型无法有效处理未结束的音频,您可以考虑尝试其他语音识别模型,如DeepSpeech、ESPnet等。这些模型可能具有更好的适应性和性能,能够更好地处理未结束的音频。
预处理音频数据:在将音频数据发送给模型之前,您可以进行一些预处理操作,例如去除静音段、降噪等。这可以帮助提高模型对未结束音频的识别准确性。
请注意,以上方法可能需要根据您的具体情况进行调整和优化。建议您根据实际情况进行尝试,并根据实际效果进行适当的调整。
2024-01-12 09:59:44赞同 展开评论

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!欢迎加入技术交流群:微信公众号:魔搭ModelScope社区,钉钉群号:44837352