
modelscope-funasr跑offline模式,发现上一句的标点总在下一句的开头。怎么解决?
modelscope-funasr跑offline模式,发现结果里上一句的标点总在下一句的开头。怎么解决?环境:cpu-online-0.1.5, 执行的是run_server_2pass.sh使用的punc_model: "damo/punc_ct-transformer_zh-cn-common-vad_realtime-vocab272727-onnx"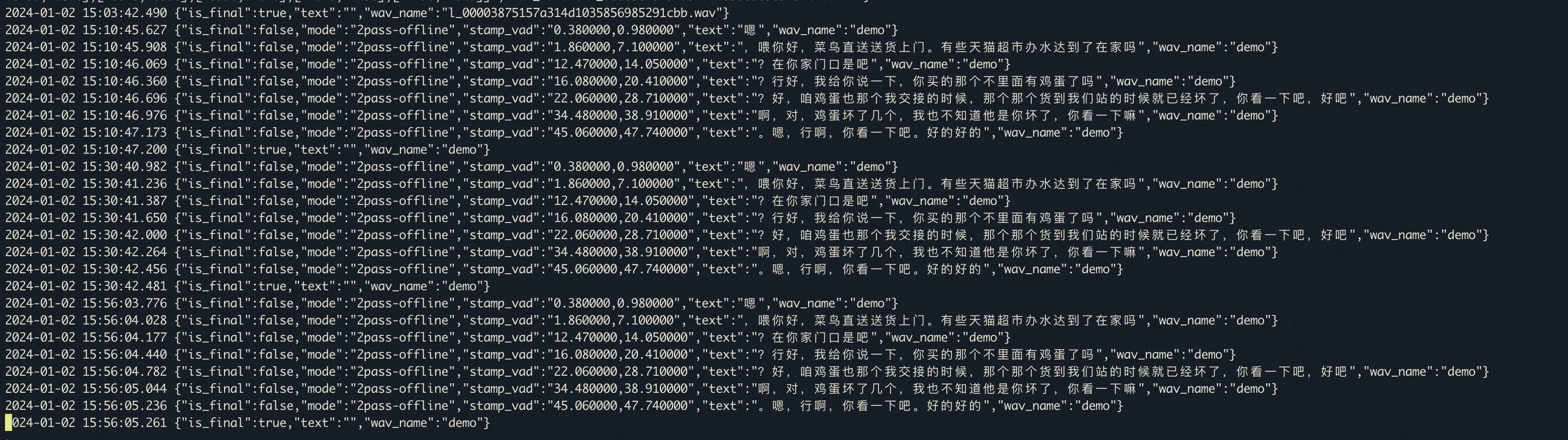
-
-
面对过去,不要迷离;面对未来,不必彷徨;活在今天,你只要把自己完全展示给别人看。
这个问题可能是由于模型在预测时,上一句的标点符号被错误地识别为下一句的开头。为了解决这个问题,你可以尝试以下方法:
检查模型是否适用于离线模式。确保你的模型支持离线推理,并且已经正确加载了权重文件。
调整模型的阈值。有时候,模型可能会将一些非常小的概率误判为标点符号。你可以尝试调整模型的阈值,以便更准确地识别标点符号。
使用其他标点符号识别模型。如果上述方法都无法解决问题,你可以尝试使用其他标点符号识别模型,看看是否能获得更好的结果。
检查数据预处理。确保你在预测之前正确地对音频进行了预处理,例如降噪、特征提取等。这些步骤可能会影响到模型的预测结果。
更新模型和环境。确保你使用的是最新版本的模型和环境,以避免因版本不兼容导致的问题。
2024-01-13 14:38:02赞同 展开评论 -
根据你的描述,你的问题可能是由于标点模型的输出位置不正确导致的。在offline模式下,标点模型应该在每一句话的结尾添加标点,而不是下一句话的开头。这可能是因为标点模型没有正确地识别出句子的边界。
为了解决这个问题,你可以尝试以下几种方法:
调整标点模型:你可以尝试使用其他的标点模型,或者调整现有模型的参数,以提高其识别句子的准确性。
使用更好的预训练模型:如果你的标点模型是在较少的训练数据上训练的,那么它可能无法很好地识别句子的边界。你可以尝试使用在大量数据上预训练的模型,以提高其性能。
增加训练数据:如果你的标点模型是在较少的训练数据上训练的,那么你可以尝试增加训练数据,以提高其性能。
使用更复杂的模型:如果你的标点模型是一个简单的模型,那么它可能无法很好地识别句子的边界。你可以尝试使用更复杂的模型,例如深度神经网络,以提高其性能。
使用更复杂的预处理和后处理步骤:你可以尝试使用更复杂的预处理和后处理步骤,以提高标点模型的性能。例如,你可以尝试使用语言模型来纠正标点模型的错误。
希望以上建议能帮助你解决这个问题。如果你仍然遇到任何问题,建议你查阅模型的文档或者联系模型的维护者以获取更多的帮助。
2024-01-12 11:47:35赞同 展开评论 -

ModelScope旨在打造下一代开源的模型即服务共享平台,为泛AI开发者提供灵活、易用、低成本的一站式模型服务产品,让模型应用更简单!欢迎加入技术交流群:微信公众号:魔搭ModelScope社区,钉钉群号:44837352