
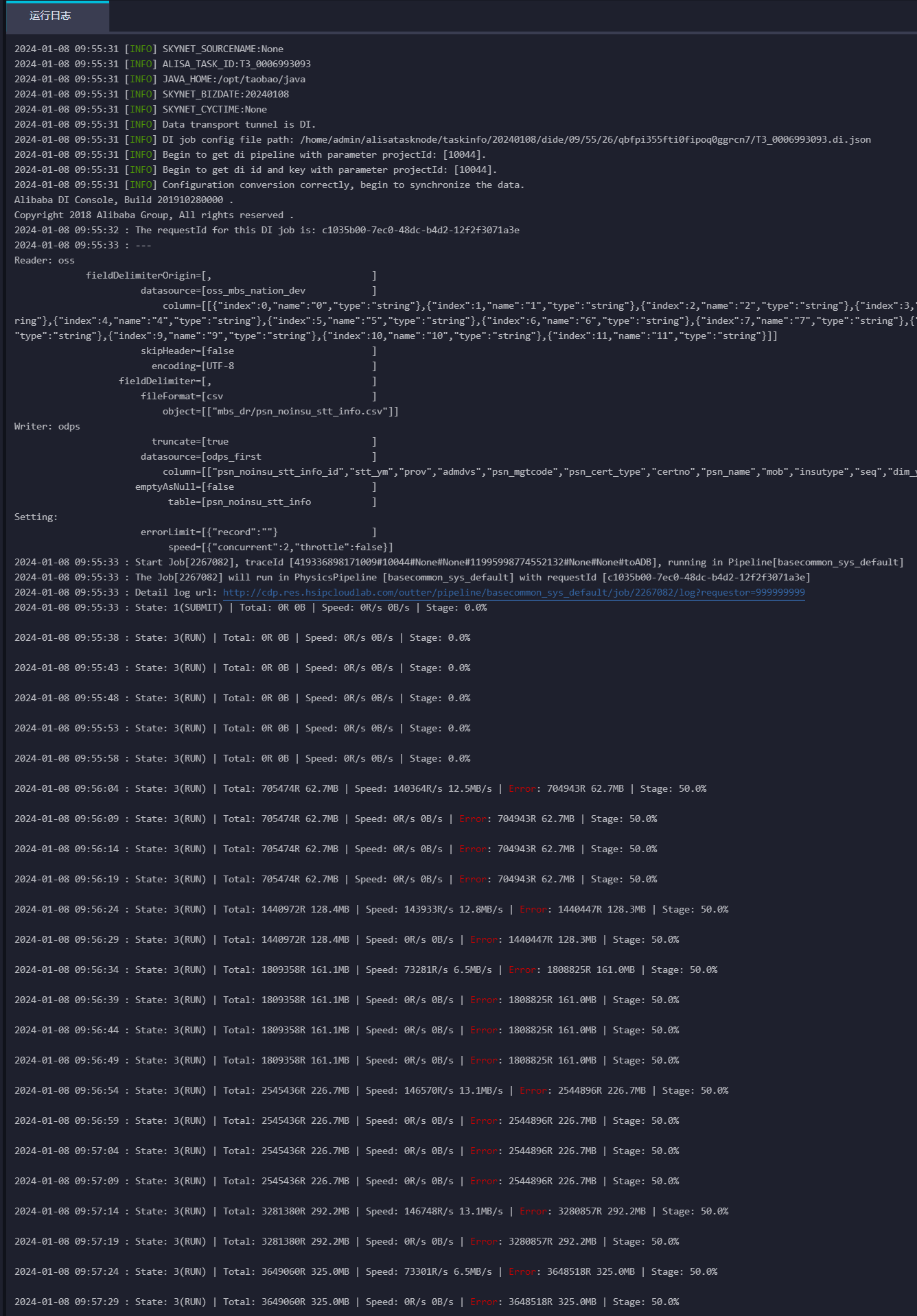
从日志上看确认不是网络问题,和oss是通的 。但是这个报错日志看不出是啥问题?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
根据你提供的日志信息,这个错误可能是由于读取CSV文件到ODPS的过程中出现了一些问题。以下是一些可能的解决方案:
检查CSV文件格式:确保CSV文件的格式是正确的,每一行都应该有相同的字段数,并且字段之间用逗号或其他分隔符分隔。如果有任何空行或格式不正确的行,可能会导致错误。
检查OSS权限:确保你有足够的权限读取CSV文件。你可以检查你的OSS控制台,确保你有读取文件的权限。
检查ODPS表结构:确保ODPS表的字段数量和类型与CSV文件的字段相匹配。如果有任何不匹配的地方,可能会导致错误。
检查网络连接:确保你的网络连接是正常的,没有中断或延迟。这可能会导致读取文件的速度变慢,甚至失败。
检查DataWorks配置:确保DataWorks的配置是正确的,特别是与OSS和ODPS相关的配置。如果有任何错误,可能会导致读取文件失败。
重启任务:如果以上方法都无法解决问题,你可以尝试重启DataWorks的任务。有时候,重启任务可以解决一些临时性的问题。
在DataWorks中从OSS读取CSV文件并同步至ODPS(MaxCompute)时,如果日志中没有明确的错误信息提示,分析问题可能需要更多具体日志内容或错误截图(报错.jpg)。不过,基于以往的经验,这类问题可能由以下几个常见原因引起:
CSV格式问题:
编码问题:
数据类型不兼容:
特殊字符或长行处理:
权限问题:
任务配置错误:
为了进一步排查,请提供详细的错误日志片段或截图,这样可以更准确地定位问题所在。同时,您可以检查以下几点来帮助解决问题:
根据日志信息,报错的原因是"编码方式不匹配。请检查数据源的fileEncoding和dataFormat属性是否一致"。
解决这个问题的方法是在代码或者配置文件中设置正确的编码格式。确保在读取CSV文件时使用的编码与写入到ODPS表中的编码相同。
例如,在Python中可以这样处理:
import pandas as pd
# 加载 CSV 文件(假设文件名为 'input.csv')
df = pd.read_csv('input.csv', encoding='utf-8')
# 将 DataFrame 写入 ODPS 表格
df.to_sql(name='output_table_name', con=engine, if_exists='replace')
在这个例子中,我们首先加载了带有 UTF-8 编码的 CSV 文件,并将其转换为 Pandas 数据帧 (DataFrame)。然后我们将这个 DataFrame 导出到一个具有正确编码的 ODPS 表格中。
DataWorks基于MaxCompute/Hologres/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。


