
文字识别OCR的提单识别,是能够正确识别空格,但是有些东西识别不出来,没有进行提取,怎么回事?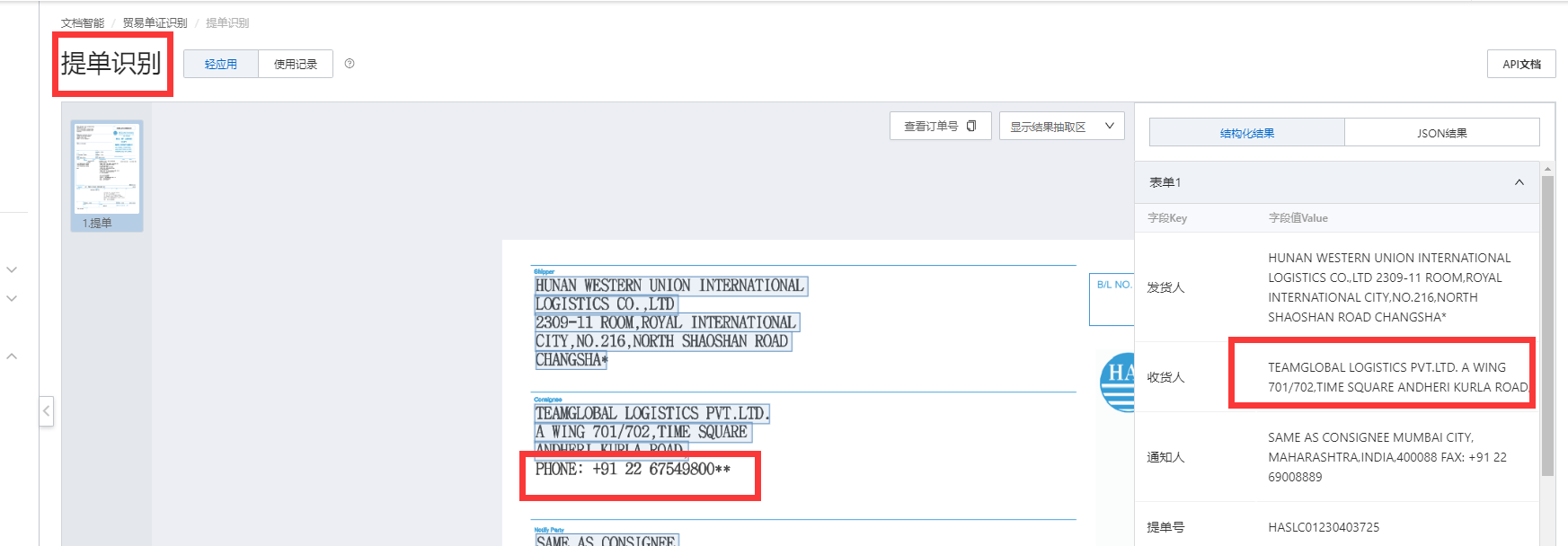
如果kv里面,能够把空格识别出来,就能使用了
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
文字识别OCR在提单识别过程中,虽然能够正确识别空格,但部分信息未能提取出来,可能与以下几个因素有关。以下是详细分析及解决方案:
图片的清晰度、分辨率或光照条件不佳可能导致OCR无法准确识别内容。
- 建议操作:
- 确保上传的图片清晰、无模糊、无遮挡,并且文字区域完整可见。
- 如果图片存在倾斜或变形,可以尝试使用图像预处理工具(如旋转、裁剪、增强对比度)优化图片质量。
如果使用的是自定义KV模板,可能由于字段框选不准确或未覆盖所有可能的文字区域,导致部分内容未被提取。
- 建议操作:
- 在配置识别字段时,确保框选范围尽量覆盖字段可能出现的最大范围,避免遗漏。
- 检查是否遗漏了某些关键字段的框选,尤其是多行或多列的内容。
OCR识别结果的准确性与字段类型的配置密切相关。如果字段类型选择错误,可能导致识别结果不符合预期。
- 建议操作:
- 根据实际需求选择合适的字段类型(如常规、日期、金额等),并利用高级配置中的正则表达式对识别结果进行后处理。
- 例如,若需要保留空格,可以在正则表达式中明确指定保留规则。
对于固定版式的提单,如果模板未正确适配,可能导致部分字段无法被识别。
- 建议操作:
- 确保模板图片与待识别图片的版式完全一致。如果版式有变化,需重新配置模板。
- 如果版式相似但不完全一致,可以尝试跳过框选参照字段步骤,让底层算法自行分析,但需注意版式差异可能影响识别效果。
OCR默认可能忽略某些特殊字符(如空格、标点符号等),或者在输出时进行了格式化处理。
- 建议操作:
- 在高级配置中,通过正则表达式明确保留空格或其他特殊字符。例如,使用正则表达式\s+匹配空格,并确保其在输出中不被移除。
- 如果需要更复杂的格式处理,可以通过API接口调用时传递自定义参数,调整输出格式。
对于非标准字体、手写体或复杂背景的图片,OCR模型可能存在一定的识别局限性。
- 建议操作:
- 如果涉及特殊字体或复杂背景,建议使用自定义训练功能,基于小样本数据对模型进行微调,提升识别精度。
- 对于长尾票证或非标准提单,可以尝试使用通用票证抽取功能,无需额外训练即可支持多种复杂场景。
如果调用的接口与图片内容不匹配(如调用手写体接口处理印刷体图片),可能导致识别结果为空或不完整。
- 建议操作:
- 确保调用了正确的OCR接口。例如,针对提单类文档,建议优先使用通用文字识别或自定义KV模板接口。
- 如果不确定接口适用性,可以通过阿里云OCR体验馆测试不同接口的效果。
根据上述分析,您可以按照以下步骤排查和解决问题:
1. 检查图片质量,确保清晰无遮挡。
2. 优化字段框选范围,确保覆盖所有可能的文字区域。
3. 调整字段类型和高级配置,明确保留空格等特殊字符。
4. 确保模板适配正确,必要时重新配置模板。
5. 针对复杂场景,考虑使用自定义训练或通用票证抽取功能。
如果问题仍未解决,建议联系阿里云OCR技术支持团队(钉钉答疑群:26560014923),提供具体图片和识别结果以便进一步分析。

