
谁有flink+prometheus对于每个flink job失败或异常进行告警的rule配置?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
要实现Flink job失败或异常的告警,首先需要确保已经安装和配置了Prometheus。然后在Flink的配置文件中启用Prometheus监控,具体操作为找到flink-conf.yaml文件,并添加以下配置:
metrics.reporters: prom
metrics.reporter.prom.class: org.apache.flink.metrics.prometheus.PrometheusReporter
同时,还需要在Flink的配置文件中指定Prometheus PushGateway的地址,例如:
metrics.reporter.promgateway.class: org.apache.flink.metrics.prometheus.PrometheusPushGatewayReporter
metrics.reporter.promgateway.jobName: myJob
这样,当Flink作业失败或异常时,Prometheus就可以捕获到相关指标并进行告警。具体的告警规则配置需要在Prometheus的配置文件中进行,如下所示:
groups:
- name: flink_job_failure_alert
rules:
- alert: FlinkJobFailure
expr: flink_job_failure_total{status="failed"} > 0
for: 1m
labels:
severity: critical
annotations:
summary: "Flink Job failed"
description: "{{$labels.instance}} of job {{$labels.job_name}} has failed."
以下是一个基本的Prometheus规则配置示例,用于监控Flink作业的状态并触发告警。这个例子假设你已经设置好了Flink的Metrics报告到Prometheus,并且Flink的指标已经被正确地暴露出来。
groups:
- name: flink_job_alerts
rules:
- alert: FlinkJobFailed
expr: flink_job_status{status="FAILED"} == 1
for: 1m
labels:
severity: critical
annotations:
summary: Flink Job {{ $labels.job_name }} has failed
description: Flink job {{ $labels.job_name }} has entered a FAILED state.
- alert: FlinkJobRestarted
expr: flink_job_status{status="RESTARTED"} == 1
for: 1m
labels:
severity: warning
annotations:
summary: Flink Job {{ $labels.job_name }} has restarted
description: Flink job {{ $labels.job_name }} has been restarted due to an error or failure.
- alert: FlinkJobCancelled
expr: flink_job_status{status="CANCELLED"} == 1
for: 1m
labels:
severity: warning
annotations:
summary: Flink Job {{ $labels.job_name }} has been cancelled
description: Flink job {{ $labels.job_name }} has been manually cancelled or terminated unexpectedly.
- alert: FlinkJobInExceptionState
expr: flink_job_exception_count > 0
for: 1m
labels:
severity: critical
annotations:
summary: Flink Job {{ $labels.job_name }} is in exception state
description: Flink job {{ $labels.job_name }} has encountered exceptions during execution.
这个配置包括了四个告警规则:
FlinkJobFailed:当Flink作业状态为"FAILED"时触发告警。FlinkJobRestarted:当Flink作业状态为"RESTARTED"时触发告警。FlinkJobCancelled:当Flink作业状态为"CANCELLED"时触发告警。FlinkJobInExceptionState:当Flink作业出现异常计数大于0时触发告警。这些规则假设你已经在Flink中设置了相应的指标(如flink_job_status和flink_job_exception_count),并且这些指标已经被正确地暴露给Prometheus。实际的指标名称和标签可能会根据你的Flink版本和配置有所不同。
在配置好这些规则后,你需要将它们添加到Prometheus的规则文件(通常是prometheus.yml)中,然后重启Prometheus服务以应用新的规则。同时,你也需要配置一个Alertmanager来处理这些告警并进行通知。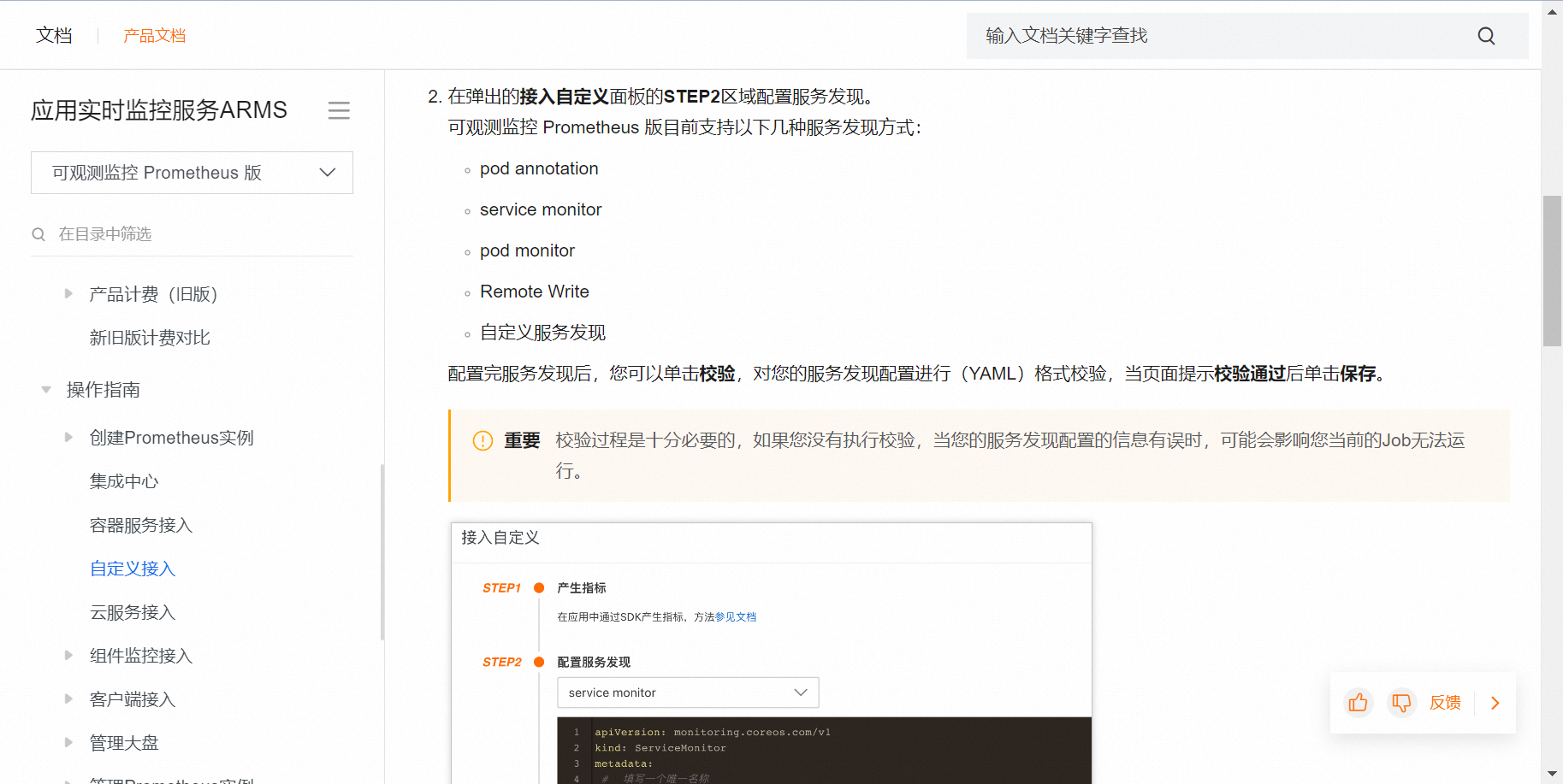
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。


