
Flink的keyBy不生效,怎么搞?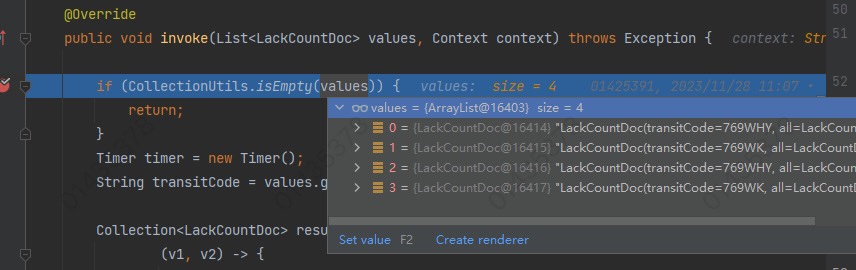
根据transitCode来keyby的,但是两组混在一起了。
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
楼主你好,看了你的描述,在使用Flink的keyBy操作时,确保以下几点:
确认输入流的数据类型是否正确。keyBy操作是基于数据流的字段进行分组,确保你选择的字段是正确的。
确认是否正确使用了keyBy操作符。keyBy操作应该在数据流中的转换操作之前进行,比如在map、filter等操作之前。
确认是否正确指定了KeySelector函数。keyBy操作需要传入一个实现了KeySelector接口的函数来指定分组字段,确保你的KeySelector函数是正确实现的,并返回正确的分组键值。
下面举一个示例,展示如何使用keyBy操作将数据流按照transitCode字段进行分组: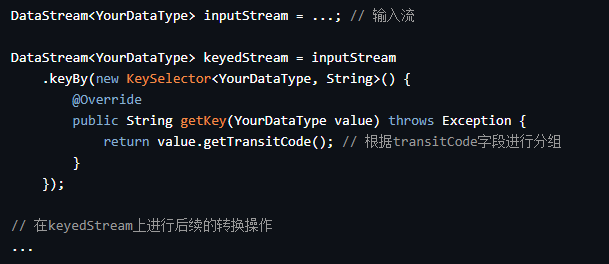
DataStream<YourDataType> inputStream = ...; // 输入流
DataStream<YourDataType> keyedStream = inputStream
.keyBy(new KeySelector<YourDataType, String>() {
@Override
public String getKey(YourDataType value) throws Exception {
return value.getTransitCode(); // 根据transitCode字段进行分组
}
});
// 在keyedStream上进行后续的转换操作
...
注意:以上示例是基于Java API的示例,如果你使用的是Scala或Python API,上面示例就不适用,还要根据你的实际情况进行调整。
如果修改了order by相关的属性,比如排序字段或方向,就会导致不兼容修改。检查一下SQL语句中是否有这样的修改,可以尝试恢复原来的排序字段和方向,相关介绍文档如下:https://help.aliyun.com/zh/flink/user-guide/deduplication#title-qri-1vj-02u_2
Flink中的KeyBy算子是一种根据指定Key将数据流分区的算子。在使用KeyBy算子时,需要指定一个或多个Key,Flink会根据这些Key将数据流分成不同的分区,以便并行处理。
KeyBy算子通常用于实现基于Key的聚合操作,如求和、平均值等。它可以将具有相同Key的数据分配到同一个分区中,并在该分区上执行聚合操作。
此外,KeyBy算子还可以用于流数据的状态管理,如将具有相同Key的数据存储在同一个状态中进行管理。 KeyBy算子的使用非常简单,只需要在代码中调用DataStream的keyBy方法,并指定一个或多个Key即可,例如:
DataStream<Tuple2<String, Integer>> dataStream = ...;
// 使用KeyBy算子将数据流分区
DataStream<Tuple2<String, Integer>> keyedStream = dataStream.keyBy(0); // 根据第一个元素作为Key
在上述代码中,我们使用KeyBy算子将数据流按照第一个元素作为Key进行分区,并返回一个新的DataStream对象。在实际应用中,我们可以根据不同的需求指定不同的Key,以达到最优的分区效果。 需要注意的是,KeyBy算子只能将数据流按照指定的Key进行分区,而无法对分区进行任何修改。如果需要对分区进行修改或者调整,可以使用其他分区算子,例如Shuffle、Rebalance等。
——参考链接。
Flink的keyBy不生效可能有多种原因,以下是一些常见的排查方法:
检查数据源是否正确:确保数据源中的数据按照指定的key进行分组。
检查keyBy操作的位置:keyBy操作应该放在reduce之前,否则会导致数据丢失。
检查key的类型是否正确:keyBy操作需要指定一个正确的key类型,如果key类型不正确,可能会导致keyBy不生效。
检查程序逻辑是否正确:如果程序逻辑有误,也可能导致keyBy不生效。可以查看日志或者调试程序来定位问题。
检查网络连接是否正常:如果Flink集群中的节点之间的网络连接出现问题,也可能导致keyBy不生效。可以检查网络连接状态或者重新部署Flink集群。
如果在Flink中使用了keyBy操作,但是没有达到预期的效果,可能存在以下几种可能的原因和解决方案:
错误的字段选择:keyBy操作需要根据某个字段进行分组操作。确保选择的字段正确,并确保该字段与实际数据匹配。
数据类型不匹配:Flink中的keyBy操作默认根据数据的哈希值进行分组。确保选择的字段具有正确的数据类型,以避免哈希值计算错误。
并行度设置不当:keyBy操作会根据选择的字段值进行分组,如果并行度设置得不当,可能导致分组效果不如预期。尝试调整作业的并行度,以平衡数据分布和计算负载。
数据倾斜:如果选择的字段存在数据倾斜,即某些值出现频率较高,可能会导致分组不均匀。可以尝试使用Flink的rebalance操作来平衡数据分布,或者使用更精细的分组方法,如keyBy和reduce组合来解决数据倾斜问题。
数据顺序问题:在Flink中,数据的处理顺序可能会影响分组的结果。确保数据的顺序与预期的一致,并了解Flink的时间语义和事件时间处理的机制,以避免出现顺序问题。
预聚合操作:在一些场景下,Flink会进行预聚合操作来提高性能。预聚合操作可能会影响到keyBy操作的效果。如果需要确保精确的分组操作,可以考虑关闭预聚合功能,或者使用其他算子来进行分组操作,如ProcessFunction。
确认执行计划:在Flink中,可以通过打印执行计划来查看作业的逻辑和数据流动方式。执行计划可以帮助检查keyBy操作是否被正确地应用。可以使用ExecutionEnvironment的explain()方法或DataStream的print()方法来打印执行计划和数据流。
如果尝试了上述解决方案仍然无效,可以查看Flink的日志和错误信息,以获取更多的调试信息,或者在Flink社区中寻求帮助。
values.size() 返回集合 values 中的对象数量。这个方法用于检查列表是否为空(即没有元素)。在这种情况下,if (CollectionUtils.isEmpty(values)) 这个条件分支表示如果传入的 values 集合为空,就立即返回。
然而,在实际运行过程中,即使 values 非空,也可能出现 keyby 失效的现象。这表明在分桶阶段,两个不同 transitCode 的文档被错误地聚集在同一组内。这可能是以下几种原因之一:
原因一:键值生成方式
当前的实现使用 values.get(transitCode) 来提取每个文档对应的 transitCode 并用作键。请确认传递给 invoke 函数的 values 是否已经按照正确的键进行了排序和聚合。如果没有按正确的键进行排序和聚合,那么在分桶阶段就会将具有相同 transitCode 的记录放在一起。
原因二:并发问题
在多线程环境中,可能存在并发修改同一份数据的风险。请确保在调用 values.get(transitCode) 时不会引发竞态条件。可以采用同步手段如 synchronized 关键字保证线程安全。
原因三:缓存问题
如果 values 是从缓存中获取的,那么缓存的设计可能存在问题。请检查缓存设计是否满足高并发场景下的需求,包括但不限于缓存容量限制、更新失效时间等。
原因四:数据质量问题
如果 values 存在一个或多处重复的 transitCode ,并且这些 transitCode 在同一个 bucket 内部,那么也会导致 keyby 失败。此时需要排查数据质量方面的问题,消除重复的 transitCode。
建议方案:
使用 Map> buckets 替代原始实现,其中键是 transitCode,值是一个 LackCountDoc 的列表。这样可以确保每个 transitCode 都对应唯一的键,减少潜在的并发问题。
尽管不是最佳实践,但在某些情况下,可以通过临时禁用 Flink 的并发特性来测试是否存在并发相关的问题。为此,可以尝试关闭 Flink 的 parallelism 设置,使其仅支持单线程模式。
可以参考以下步骤进行排查:
stream.keyBy(x -> x.transitCode);
Flink KeyBy 不生效的情况有很多种可能,下面是一些常见的解决方案供参考:
关键字类型转换,确认传入 keyBy 方法的参数列表是否符合要求。values.get(transitCode) 返回的结果必须是可以直接比较大小的类型,否则可能导致排序结果不符合预期。请确保 transitCode 是 String 类型,或者已经经过适当类型的转换。
数据清洗,检查 values 集合是否有无效元素。有些时候,集合中可能存在null值或者非法字符等情况,会导致KeyBy不起作用。可以通过过滤或者校验等方式清理数据集。
List<LackCountDoc> cleanValues = CollectionUtils.filter(values,
LackCountDoc::isInvalid);
context.commit();
检查join操作,如果在 KeyBy 同时伴随着 Join 操作,应确保 join 条件满足一对一关系。若实际业务需求并非如此,需调整 KeyBy 和 Join 结构。
检查聚合函数,如果 KeyBy 后面跟着聚合函数(如 sum()),请确保每个 groupby 组都有至少一条记录。否则,聚合结果将会为空。
检查并发性,如果 KeyBy 后面跟随着 parallelism 参数,表示开启并行化处理。然而,如果 KeyBy 的结果不是唯一的,可能会导致乱序现象。这时可以关闭并行化处理,或者优化 KeyBy 结果保证唯一性。
检查键的类型:确保你正在使用的键的类型是正确的。在Flink中,键必须是可序列化的,并且通常应该是不可变的。
检查键的选择器:确保你使用了正确的键选择器来提取键。例如,如果你正在使用transitCode作为键,确保你在keyBy操作中使用了正确的字段名。
查看数据:检查输入数据,确保它们确实具有不同的键值。你可以使用Flink的打印操作或其他工具来查看流中的数据。
版本和依赖:确保你使用的Flink版本与你的代码和依赖库兼容。有时,库的新版本可能会引入不兼容的更改。
日志和错误信息:查看Flink的日志和错误信息,看是否有任何关于键不匹配或数据格式问题的提示。
重新运行:尝试清理并重新启动你的Flink应用程序,并确保你的数据源也是最新的。
调试:如果上述步骤都没有解决问题,你可能需要深入调试你的代码。使用Flink提供的调试工具和日志记录来跟踪数据流经Flink作业的过程。
确保KeyBy操作正确使用:在使用KeyBy操作时,需要确保传递给该操作的字段是唯一的,并且能够作为键来区分不同的数据流元素。如果传递给KeyBy操作的字段不满足这些条件,可能会导致KeyBy操作不生效。
检查数据流元素:在Flink中,数据流元素可以是任何可序列化的对象。如果数据流元素不是可序列化的对象,可能会导致KeyBy操作不生效。确保数据流元素是可序列化的,并使用正确的类型进行KeyBy操作。
调整并行度:在Flink中,通过调整并行度可以影响数据在计算过程中的分布方式。如果并行度设置不当,可能会导致数据分布不均匀,从而影响KeyBy操作的性能。根据实际情况调整并行度,以确保数据分布均匀。
检查Flink版本:如果你使用的是较旧的Flink版本,可能会存在已知的bug或者不兼容问题。尝试更新Flink到最新版本,看看问题是否得到解决。
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。


