
请问下,有Alink和Spark-ML对比的demo吗?想复现、测试一下~~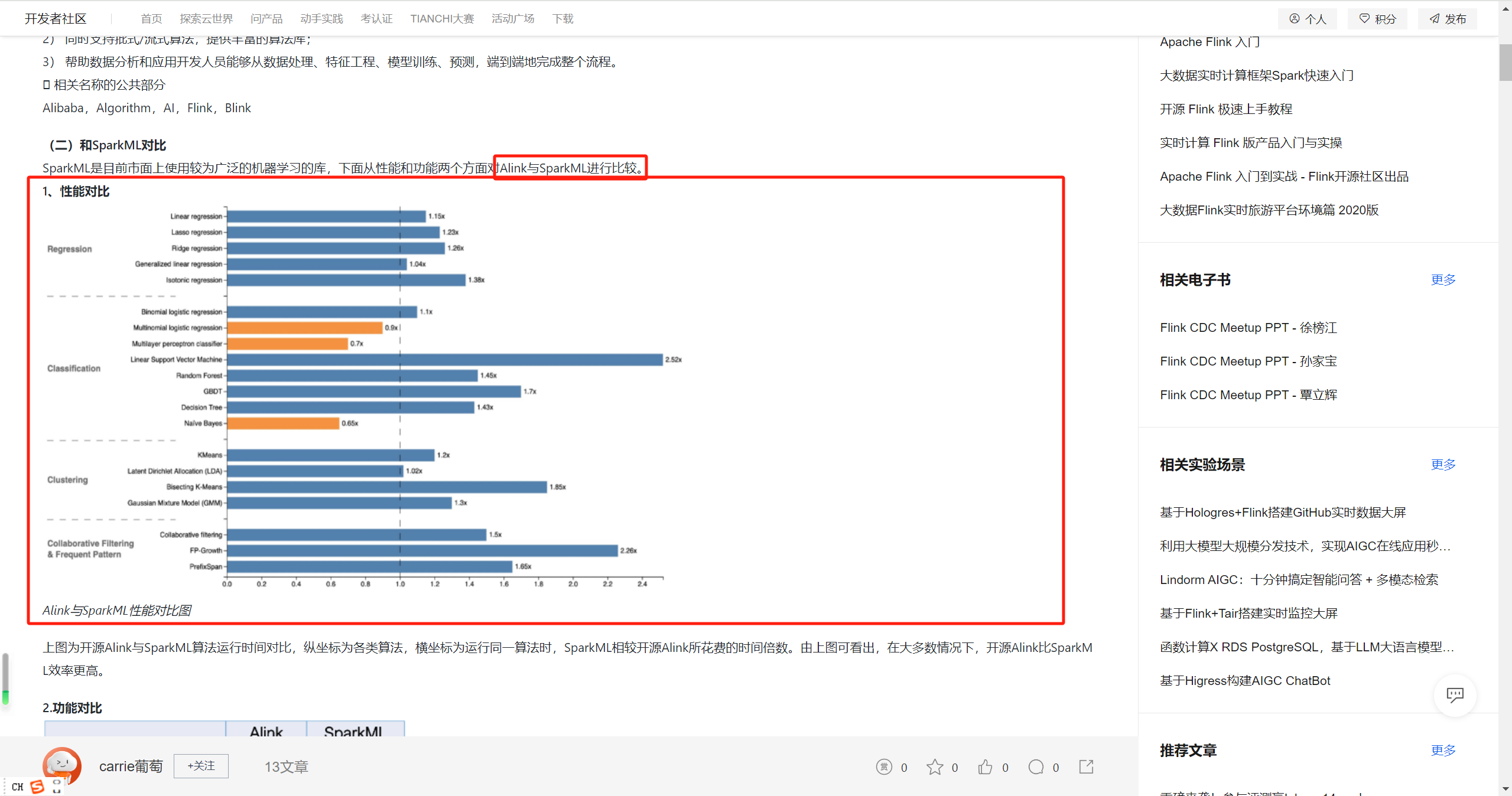
请问下有这样的benchmark对比测试吗?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
根据您提供的知识库资料,目前并没有直接提到关于 Alink 和 Spark-ML 的对比测试或相关 demo 的内容。不过,我可以为您提供一个结构化的解答,帮助您理解如何进行两者的对比测试,并指导您复现和测试。
两者在功能上有一些重叠,但在底层实现、性能优化和适用场景上存在差异。因此,通过 benchmark 对比测试可以帮助您更好地选择适合的工具。
为了复现和测试 Alink 和 Spark-ML 的性能,您可以按照以下步骤设计实验:
adult 数据集(UCI Machine Learning Repository)。housing 数据集。以下是基于 TPC-H 数据集的对比测试示例:
<dependency>
<groupId>com.alibaba.alink</groupId>
<artifactId>alink_core_flink-1.14_2.11</artifactId>
<version>1.6.0</version>
</dependency>
BatchOperator.setParallelism(4);
BatchOperator data = CsvSourceBatchOp()
.setFilePath("oss://your-bucket/tpch-data/")
.setSchemaStr("col1 string, col2 double, col3 int");
LogisticRegression train = new LogisticRegression()
.setFeatureCols("col2", "col3")
.setLabelCol("label")
.setPredictionCol("pred");
train.fit(data).transform(data).collect();
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_2.12</artifactId>
<version>3.2.1</version>
</dependency>
val spark = SparkSession.builder().appName("Spark-ML Test").getOrCreate()
val data = spark.read.format("parquet").load("oss://your-bucket/tpch-data/")
val lr = new LogisticRegression()
.setFeaturesCol("features")
.setLabelCol("label")
val model = lr.fit(data)
model.transform(data).show()
虽然当前知识库中没有直接提供 Alink 和 Spark-ML 的对比测试案例,但通过上述方法,您可以自行设计并复现测试。如果您需要更详细的代码示例或具体配置指导,请进一步说明您的需求,我将为您提供更深入的支持。
人工智能平台 PAI(Platform for AI,原机器学习平台PAI)是面向开发者和企业的机器学习/深度学习工程平台,提供包含数据标注、模型构建、模型训练、模型部署、推理优化在内的AI开发全链路服务,内置140+种优化算法,具备丰富的行业场景插件,为用户提供低门槛、高性能的云原生AI工程化能力。

