
pipeline,循环发出同一个请求,会出现显存溢出的问题 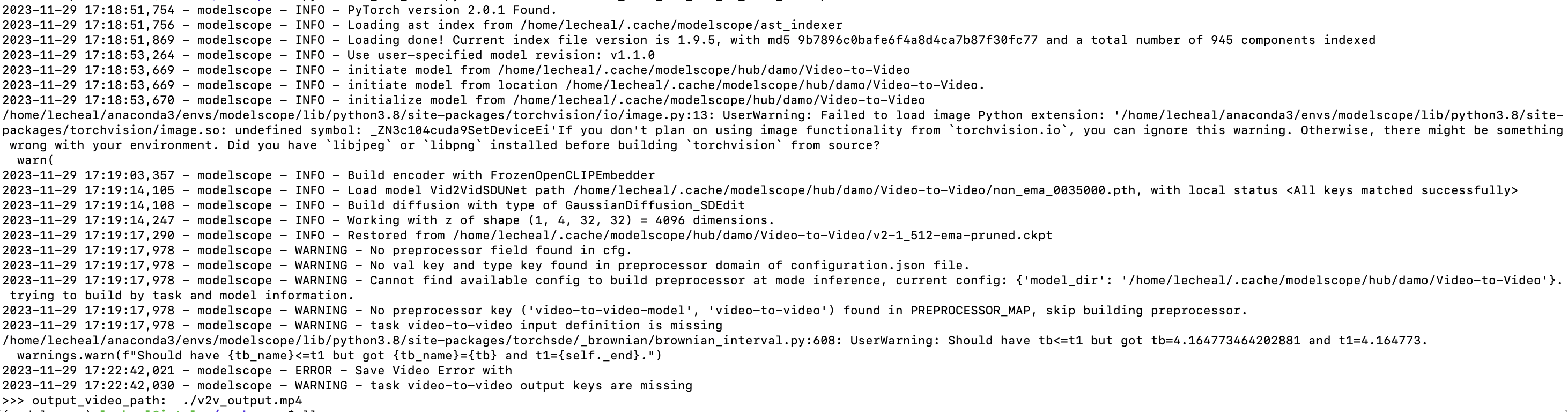
而且我想改推理batch,不知道怎么改?
在ModelScope中,循环发出同一个请求可能会导致显存溢出的问题。为了解决这个问题,可以考虑以下几个方面:
在ModelScope中,循环发出同一个请求可能会导致显存溢出。为了解决这个问题,你可以尝试以下方法:
减小批量大小(batch size):将模型的批量大小从默认值减小到适合你的GPU内存的大小。例如,如果你的GPU内存为8GB,可以将批量大小设置为4或2。
使用梯度累积(gradient accumulation):梯度累积是一种技术,可以在不增加显存占用的情况下,通过多次更新模型参数来累积梯度。你可以尝试将批量大小设置为更大的值,然后使用梯度累积来减少实际的迭代次数。
使用混合精度训练(mixed precision training):混合精度训练是一种技术,可以在不牺牲性能的情况下,减少显存占用。你可以尝试使用PyTorch或其他深度学习框架提供的混合精度训练功能。
检查是否有其他程序占用了GPU资源:确保没有其他程序正在使用你的GPU资源。如果有,请关闭这些程序,以便给模型训练腾出足够的显存空间。
关于修改推理batch的问题,你可以在调用模型进行推理时,设置batch_size参数。具体操作如下:
from modelscope.pipelines import pipeline
# 创建一个推理管道
inference_pipeline = pipeline('text-generation', model='your_model_id')
# 设置推理batch大小
inference_pipeline.model.config.update({'batch_size': your_desired_batch_size})
# 进行推理
result = inference_pipeline(input='your_input_text')
将your_model_id替换为你的模型ID,将your_desired_batch_size替换为你想要设置的推理batch大小,将your_input_text替换为你要进行推理的输入文本。
一般pipeline输入只有一个input时,input处理成list,推理直接设置batch_size=4这种就行,但这个v2v还有其他参数。。此回答整理自钉钉群:魔搭ModelScope开发者联盟群 ①

