
你好 我这边使用了一个ZhipuAI/ChatGLM-6B-int8,运行官方的cli-demo 会报CUDA out of memory,这个一般怎么处理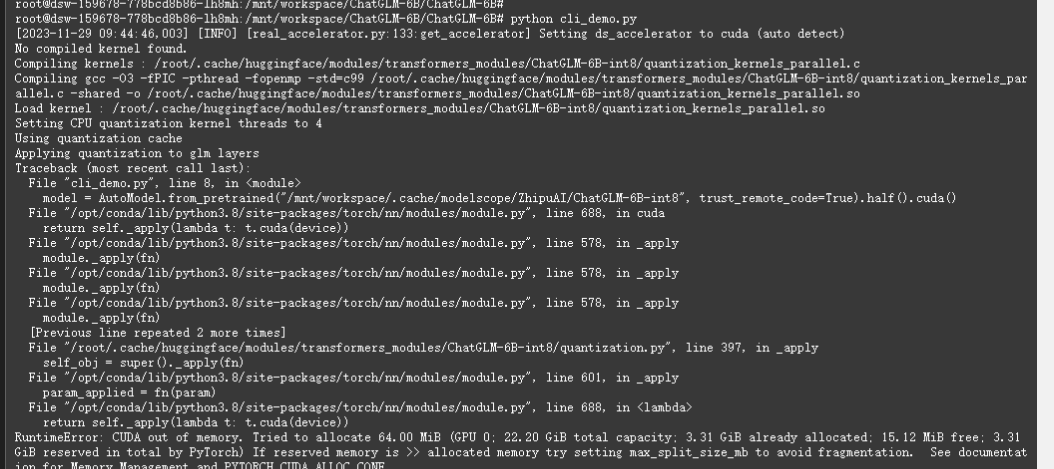
没看到其他再跑 这个现实没有是不是代表没用到gpu
根据您的描述,您在使用ZhipuAI/ChatGLM-6B-int8模型时遇到了CUDA out of memory的问题。这可能是因为您的GPU内存不足导致的。您可以尝试以下方法来解决这个问题:
减小批量大小(batch size):尝试将批量大小从默认值减小到较小的值,例如32或64,以减少每次迭代所需的GPU内存。
使用CPU运行:如果您的GPU内存不足以支持较大的批量大小,您可以考虑使用CPU运行模型。在运行命令时,添加--device cpu参数,如下所示:
python cli-demo.py --model_name_or_path "ZhipuAI/ChatGLM-6B-int8" --device cpu
释放其他占用GPU内存的程序:确保在运行模型之前关闭其他占用大量GPU内存的程序,以便为模型腾出足够的内存空间。
升级硬件:如果可能的话,考虑升级您的GPU内存,以便能够处理更大的批量大小。
在ModelScope中,如果遇到CUDA out of memory的问题,可以尝试以下方法解决:
减小批量大小(batch size):将模型的批量大小从默认值减小到适合你的GPU内存的大小。例如,如果你的GPU内存为8GB,可以将批量大小设置为4或2。
使用梯度累积(gradient accumulation):梯度累积是一种技术,可以在不增加显存占用的情况下,通过多次更新模型参数来累积梯度。你可以尝试将批量大小设置为更大的值,然后使用梯度累积来减少实际的迭代次数。
使用混合精度训练(mixed precision training):混合精度训练是一种技术,可以在不牺牲性能的情况下,减少显存占用。你可以尝试使用PyTorch或其他深度学习框架提供的混合精度训练功能。
检查是否有其他程序占用了GPU资源:确保没有其他程序正在使用你的GPU资源。如果有,请关闭这些程序,以便给模型训练腾出足够的显存空间。
如果以上方法都无法解决问题,可以考虑使用CPU进行训练。虽然这会降低训练速度,但可以避免CUDA out of memory的问题。
还有其他的在跑吗?gpu显存貌似被占用了。前面如果用了notebook的话,您重启内核试试。。此回答整理自钉钉群:魔搭ModelScope开发者联盟群 ①

