
文字识别OCR这里面调用为什么失败?
文字识别OCR这里面调用为什么失败?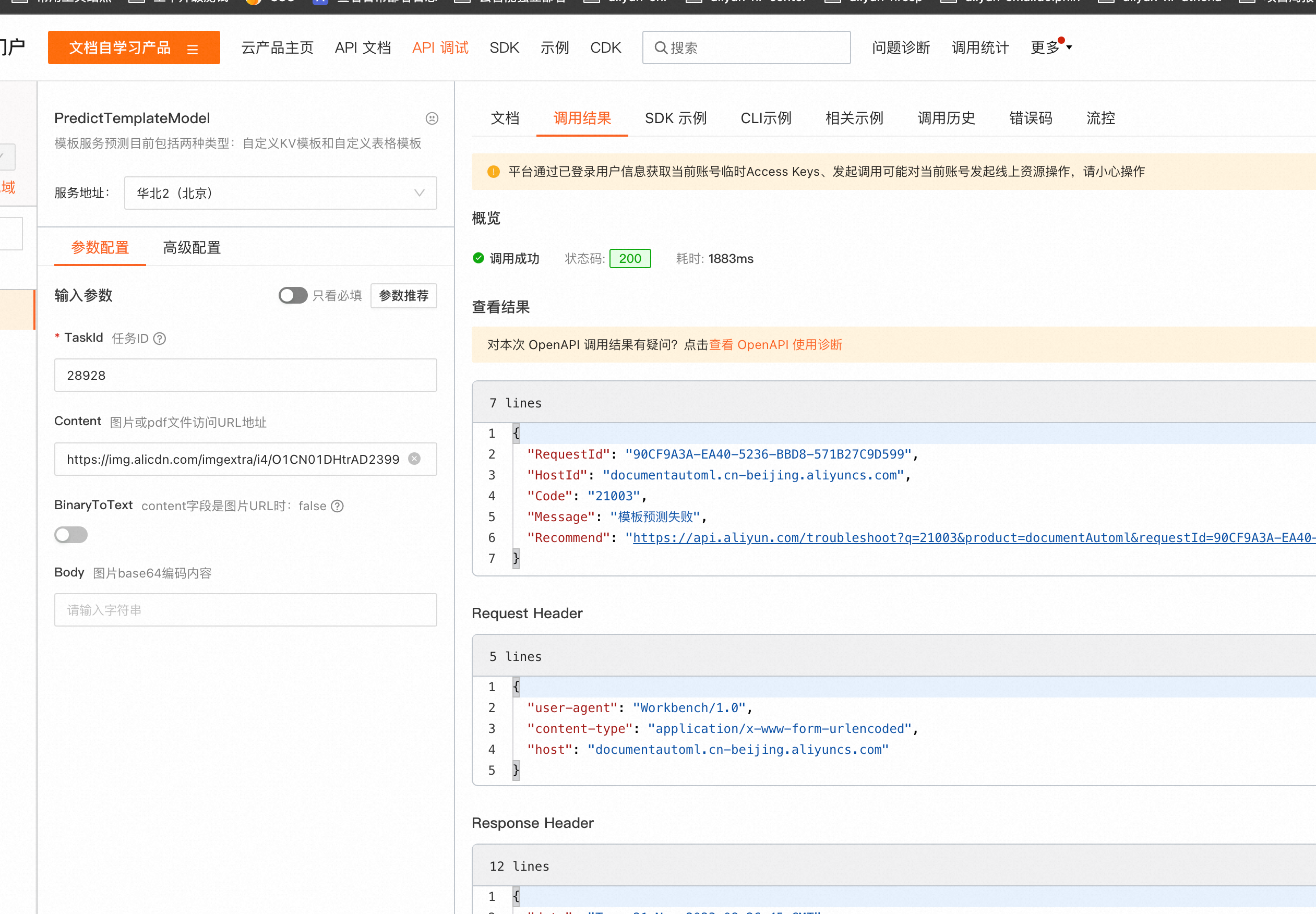
这个taskid 来源 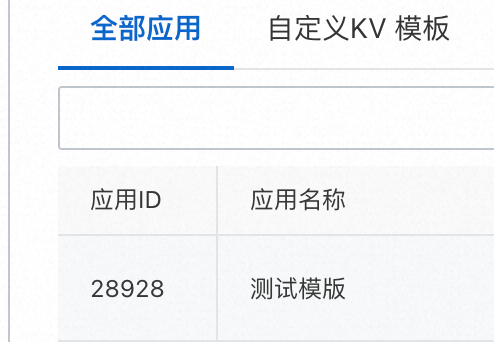 {
{
"RequestId": "90CF9A3A-EA40-5236-BBD8-571B27C9D599",
"HostId": "documentautoml.cn-beijing.aliyuncs.com",
"Code": "21003",
"Message": "模板预测失败",
"Recommend": "https://api.aliyun.com/troubleshoot?q=21003&product=documentAutoml&requestId=90CF9A3A-EA40-5236-BBD8-571B27C9D599"
}
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
-
面对过去,不要迷离;面对未来,不必彷徨;活在今天,你只要把自己完全展示给别人看。
文字识别OCR调用失败可能有多种原因,以下是一些常见的情况:
网络连接问题:请确保您的设备正常连接到互联网,并且网络连接稳定。如果网络连接不稳定或中断,可能导致OCR调用失败。
访问权限限制:某些OCR服务可能需要授权或提供有效的API密钥才能进行调用。请确保您已正确配置和提供所需的身份验证信息,如应用ID、密钥等。
请求参数错误:检查您发送的请求是否符合OCR服务的要求。确保您提供了正确的图像数据、请求头、URL等,并按照API文档中的要求进行格式化。
图像质量问题:OCR对于模糊、低分辨率或过曝/欠曝的图像可能无法准确识别。请确保您的图像质量良好,尽量使用清晰、高分辨率和适当曝光的图像。
服务器问题:OCR服务的服务器可能出现故障、维护或性能问题。这可能导致调用失败或响应时间延迟。您可以检查该服务的状态页面或与服务提供商联系以获取更多信息。
2023-11-30 21:08:28赞同 展开评论 -
网站:http://ixiancheng.cn/ 微信订阅号:小马哥学JAVA
模块预测失败,大概率是图片不清晰导致的;可以考虑以下的手段进行解决:
当OCR识别结果返回"预测失败"时,表示OCR系统无法成功识别您提供的图像或文本。这种情况可能由以下一些因素引起:图像质量问题:OCR系统对文字识别非常依赖图像的质量。如果图像模糊、光线不足、倾斜等,会导致识别结果不准确甚至无法识别。您可以尝试改善图像质量,如调整光线、纠正图像倾斜等,以提高OCR的成功率。
文字特征问题:OCR系统可能对某些字体、手写体、特殊符号或其他复杂的文本特征识别能力有限。如果您的文本包含这些特殊情况,可能会导致预测失败。在这种情况下,您可以尝试使用具有更强大识别能力的OCR工具,例如专门针对手写体或特定文本特征进行优化的OCR引擎。
缺少训练样本:OCR系统通常是基于机器学习和深度学习技术进行训练的。如果您提供的文本样本在训练数据中较少或没有涵盖到,则OCR系统可能无法准确预测。在这种情况下,可能需要重新训练OCR模型,并增加包含您感兴趣的文本样本。
如果您遇到预测失败的情况,可以尝试以下方法来处理:
改善图像质量:优化图像质量,确保清晰、高对比度且光线充足。可以进行图像预处理操作,如去噪、增强对比度等,以提高OCR识别的准确性。
使用不同的OCR引擎或算法:尝试使用其他OCR服务或工具,可能有不同的识别算法或训练数据,能够更好地适应您的特定需求。
提供更多训练样本:如果您有大量的自定义文本样本,您可以将这些样本添加到训练数据中,重新训练OCR模型以提高识别准确性。
人工干预:在某些特殊情况下,手动校正OCR识别结果可能是一种解决方法。您可以通过人工审查并纠正预测失败的部分,以获得更准确的结果。
最后,建议尝试使用官方提供的demo以及图片或者文件的内容进行调试一下目前接口服务是否存在问题;如果官方的demo不存在问题,大概率是自己提供的内存还没有办法进行识别。希望早日解决
2023-11-30 18:05:05赞同 展开评论

