
DataWorks自依赖不能直接添加在依赖项里面吗?如何正确添加自依赖?
DataWorks自依赖不能直接添加在依赖项里面吗?如何正确添加自依赖?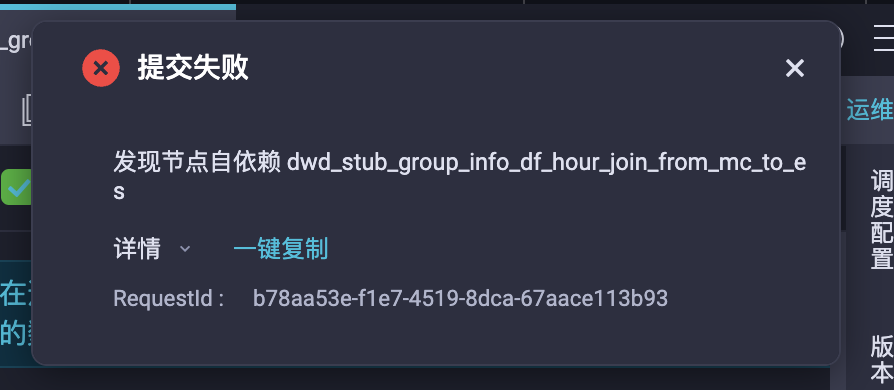

展开
收起
2
条回答
 写回答
写回答
-
 2023-11-30 19:39:27赞同 展开评论 打赏
2023-11-30 19:39:27赞同 展开评论 打赏 -
 面对过去,不要迷离;面对未来,不必彷徨;活在今天,你只要把自己完全展示给别人看。
面对过去,不要迷离;面对未来,不必彷徨;活在今天,你只要把自己完全展示给别人看。在阿里云DataWorks中,自依赖是指一个节点的调度依赖于自身上一次执行的结果。要正确添加自依赖,你需要按照以下步骤操作:
登录DataWorks控制台:
- 使用你的阿里云账号登录到DataWorks控制台。
选择工作空间:
- 在控制台首页,找到并点击你想要修改任务的工作空间。
进入数据开发页面:
- 在左侧导航栏,单击“工作空间列表”,然后选择工作空间所在地域后,单击相应工作空间后的“进入数据开发”。
打开节点属性:
- 在数据开发页面,找到你想要添加自依赖的任务节点,双击它以打开其详情页。
设置依赖关系:
- 在节点详情页,通常会有一个“依赖”或“调度配置”区域。
- 在这里,你可以看到已经存在的上游和下游依赖关系。
- 如果没有自依赖选项,可能需要先取消当前的所有依赖关系。
添加自依赖:
- 有些版本的DataWorks支持直接在依赖项里面勾选自依赖,如果没有这个选项,可以参考以下方法:
- 创建一个新的虚拟节点(例如,名称为
self_dependence_node),不执行任何实际的操作。 - 将这个新的虚拟节点设置为原始节点的上游依赖,并且让原始节点依赖于这个虚拟节点。
- 这样,在每次运行时,原始节点都会等待虚拟节点完成,而虚拟节点实际上什么也不做,这相当于实现了自依赖的效果。
- 创建一个新的虚拟节点(例如,名称为
- 有些版本的DataWorks支持直接在依赖项里面勾选自依赖,如果没有这个选项,可以参考以下方法:
保存更改:
- 完成依赖关系的设置后,记得保存更改,并将改动发布到生产环境,以便新设置能够影响实际的任务执行。
2023-11-30 18:08:58赞同 展开评论 打赏

版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
相关问答

DataWorks基于MaxCompute/Hologres/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。
热门讨论
热门文章
数据来源:com.alibaba.fastjson.JSONException: syntax er
6226
DataWorks我该如何访问A项目安装了项目的package资源?
2519
dataworks里面的stg层、ods层、dwd层、dws层、是怎么分层的呢?
3119
Dataphin和 Dataworks 有啥区别呢?
2136
DataWorks failed: ODPS-0121145:Data overflow - 0 ?
1215
DataWorks中odps SQL 参数 如何获取前一天的yyyymm?
1050
DataWorks set tblproperties("transactional"="true?
1269
请教一下DataWorks,doris和starRocks 选型,选哪个?
1738
DataWorks Parse exception - invalid token '+'?
1693
写了几百万的数据 后就会 broken pipe(write failed),es集群有问题吗?
551
展开全部
DataWorks智能交互式数据开发与分析之旅
1254
DataWorks操作报错合集之配置项目连通oss数据源 , 报The request signature we calculated does not match the signature you provided.如何解决
1086
限时优惠体验!DataWorks数据治理中心全新升级为数据资产治理
532
DataWorks售前咨询
9924
数据分析经典案例重现:使用DataWorks Notebook 实现Kaggle竞赛之房价预测,成为数据分析大神!
224
DataWorks:新一代 Data+AI 数据开发与数据治理平台演进
594
2万字揭秘阿里巴巴数据治理平台DataWorks建设实践
28216
DataWorks产品体验测评
117
大数据&AI的16种可能,2020阿里云客户最佳实践合集下载
73076
DataWorks产品使用合集之怎么将数据导入或写入到 Hologres
138
展开全部


相关文章
相关电子书
更多

