
在ModelScope中,cv领域模型报错,帮忙看下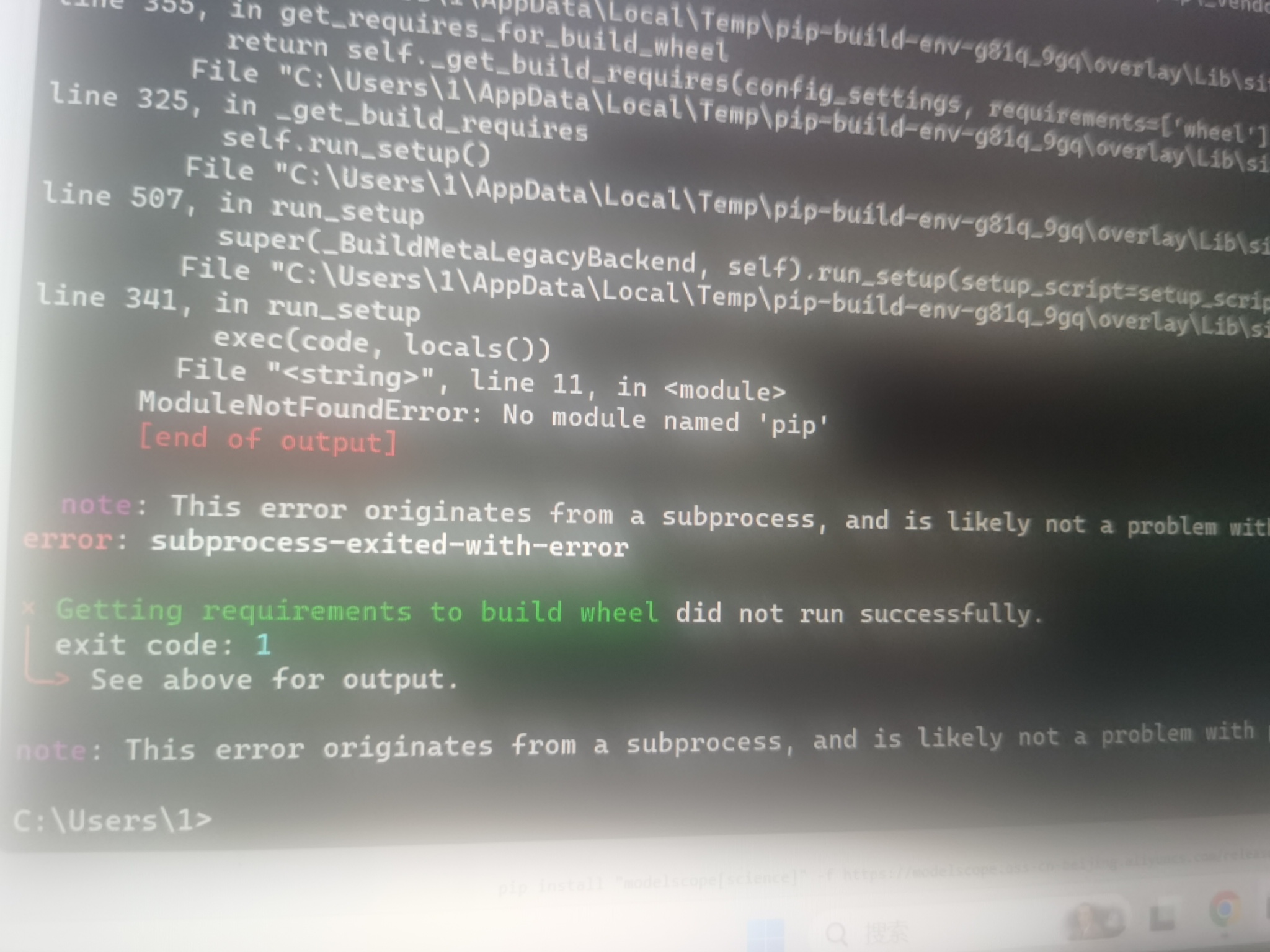
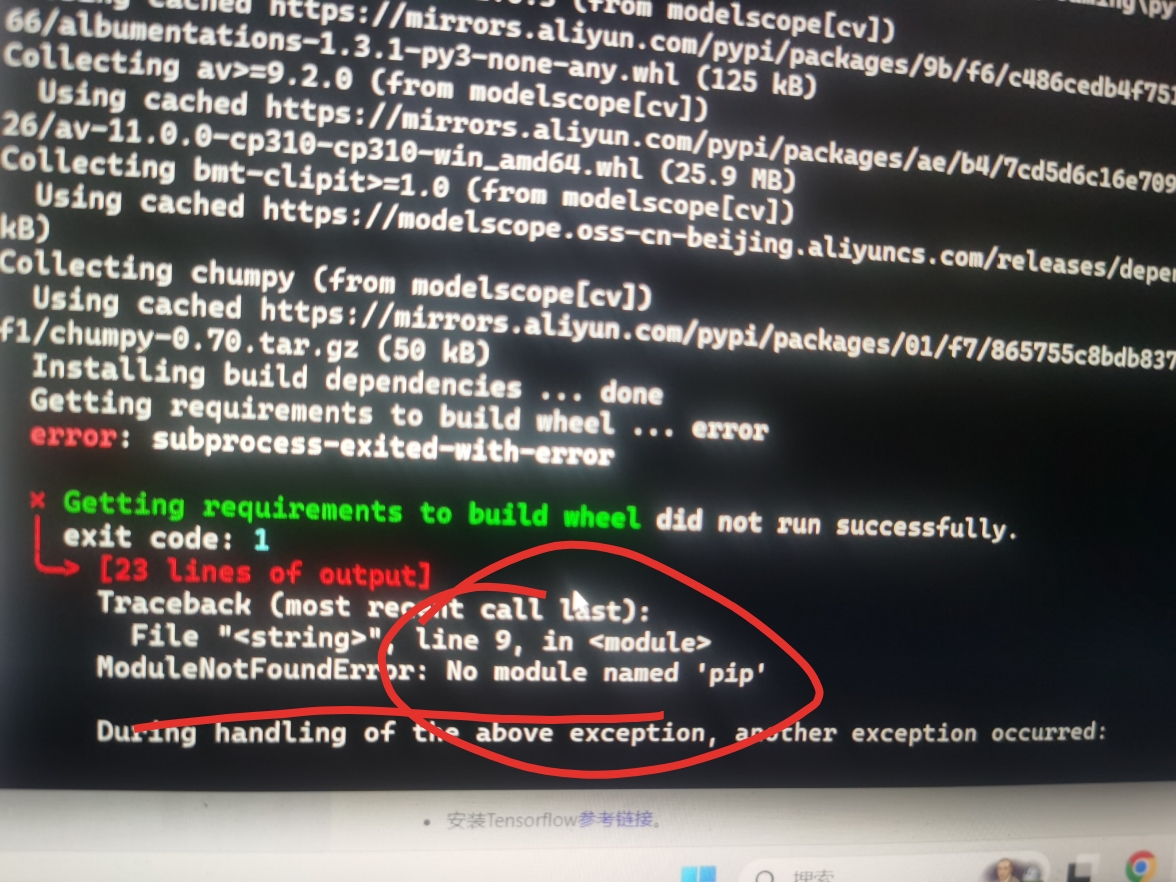
在ModelScope中遇到CV(计算机视觉)领域模型报错时,可以按照以下步骤进行排查和解决:
确保输入数据的格式符合模型的要求。对于图像类模型,通常需要传入图片的Base64编码或图片的URL地址。如果选择使用URL地址作为输入,需要确保部署的服务具有公网访问权限,并正确配置了白名单。
import requests
import json
import base64
service_url = 'YOUR_SERVICE_URL'
token = 'YOUR_SERVICE_TOKEN'
# 下载图片并转换为Base64编码
with requests.get('https://modelscope.oss-cn-beijing.aliyuncs.com/test/images/retina_face_detection.jpg') as img_url:
img = img_url.content
img_base64encoded = base64.b64encode(img)
# 构造请求数据
request = {"input": {"image": img_base64encoded.decode()}}
request_data = json.dumps(request)
# 发送请求
resp = requests.post(service_url, headers={"Authorization": token}, data=request_data)
print(resp.text) # 输出为模型的输出结果
确认服务是否正确配置,包括服务的访问地址和服务Token。如果服务部署在私有网络中,确保网络连接正常并且服务具有公网访问权限。
查看服务的日志信息,定位具体的错误原因。常见的错误包括输入数据格式不正确、服务配置错误、网络连接问题等。
根据知识库中的常见异常及解决方法,您可以参考以下内容进行排查:
出错原因:每一个 SDK 对象创建时都会申请一个连接。如果没有使用对象池,每一次任务结束后对象都被析构,导致连接在61秒内不可复用。
解决方法:使用对象池复用对象。
出错原因:同“异常 1”,连接池已经达到最大连接限制,新的任务需要等待无引用状态的连接61秒触发超时后才可以获得连接。
解决方法:使用对象池复用对象。
出错原因:在高并发调用时,同一个对象会复用同一个WebSocket连接,因此WebSocket连接只会在服务启动时创建。任务启动阶段如果立刻开始较高并发调用,同时创建过多的WebSocket连接会导致阻塞。
解决方法:启动服务后逐步提升并发量,或增加预热任务。
Invalid action('run-task')! Please follow the protocol!出错原因:客户端报错后,服务端不知道客户端出错,连接处于任务中状态。此时连接和对象被复用并开启下一个任务,导致流程错误,下一个任务失败。
解决方法:在抛出异常后主动关闭 WebSocket 连接后归还对象池。
出错原因:同时创建过多 WebSocket 连接导致阻塞,但业务流量持续打进来,导致任务短时间积压,并且在阻塞后所有积压任务立刻调用。
解决方法: 1. 检查网络情况。 2. 排查尖刺前是否出现大量其他服务端报错。 3. 提高账号并发限制。 4. 调小对象池和连接池大小,通过对象池上限限制最大并发数。 5. 提升服务器配置或扩充机器数。
解决方法: 1. 检查是否已经达到网络带宽上限。 2. 检查实际并发数是否已经过高。
如果问题依然存在,可以尝试更新模型配置。通过API更新阿里云AIWorkSpace中的模型配置信息,具体步骤如下:
PUT /api/v1/models/{ModelId} HTTP/1.1
{
"ModelName": "情感分析",
"ModelDescription": "情感分析。",
"Accessibility": "PUBLIC",
"Origin": "ModelScope",
"Domain": "nlp",
"Task": "text-classification"
}
如果以上方法都无法解决问题,建议联系技术支持团队。可以通过钉钉用户群(钉钉群号:64970014484)与函数计算工程师即时沟通。
希望以上信息能帮助您解决问题!如果还有其他疑问,请随时联系。您可以复制页面截图提供更多信息,我可以进一步帮您分析问题原因。
