
DataWorks这个逻辑是 表行数,1天差值的逻辑, 表行数, 上周期差值 的逻辑不应该是 取bizdate最近的一条作为历史样本吗?看这个也是 表行数,上周期差值, 样本值是最新的一条, 基准值是上一条的值, 您说的 ' 基准值可以理解为是昨天最后的那条' 是 表行数,1天差值的逻辑吧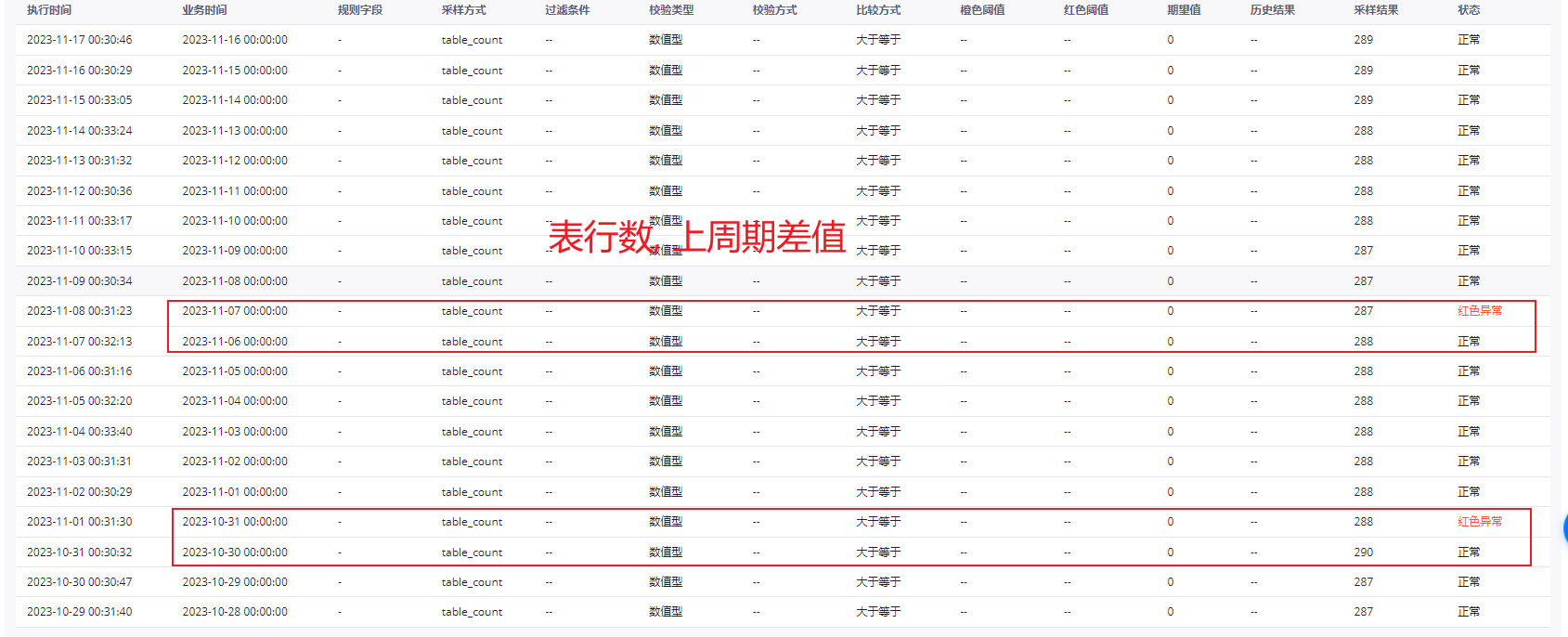
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
老的逻辑实现规则有点复杂 样本值是最新的那条 基准值可以理解为是昨天最后的那天 也就是23112-23158是否>=0,对的 这两个告警也是符合上述规则的,此回答整理自钉群“DataWorks交流群(答疑@机器人)”
在DataWorks中,对于表行数的1天差值逻辑和表行数、上周期差值逻辑,的确有所区别。对于表行数的1天差值逻辑,样本是当天分区的表行数,而基准值是前一天分区产生的表行数。这种方式可以帮助我们监测到表行数一天内的变化情况,从而及时发现可能存在的数据问题。
而对于表行数、上周期差值的逻辑,基准值则是上一周期产生的分区的表行数,用来对比当天采集的表行数,计算出相差的数值。通过比较不同周期内的表行数,我们可以观察到表行数在一个周期内的变化情况,进而发现可能的周期性数据问题。
在具体的实现上,DataWorks平台会在运维中心中,当表关联的调度节点运行完成后,触发数据质量校验。根据所设定的规则,比如上述的两种逻辑,DataWorks会进行相应的数据质量检查,如果发现问题,任务可能会因质量规则校验失败而退出,阻止下游节点执行,防止脏数据影响范围进一步扩大。
总的来说,这两种逻辑分别关注了不同的时间范围和数据波动情况,为数据质量管理提供了全面的视角,能够更好地帮助我们保障数据的质量和准确性。
DataWorks基于MaxCompute/Hologres/EMR/CDP等大数据引擎,为数据仓库/数据湖/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。


