Flink解析json到表,有没有强大的插件?复杂json
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
楼主你好,当需要解析复杂的JSON数据并将其加载到表中时,可以考虑使用阿里云Flink的Json Table Format插件,该插件提供了强大的功能来处理复杂的JSON数据结构。
以下是使用Json Table Format插件解析复杂JSON数据的步骤:
1、添加依赖:在Flink项目中添加Json Table Format插件的依赖。可以在Flink官方网站上找到相应的依赖信息。
2、定义表结构:在DDL中使用Json Table Format来定义表结构,并指定JSON字段的路径和类型,可以使用点号('.')和方括号('[]')来指定嵌套字段的路径。
以下是一个DDL示例,定义了一个名为MyTable的表,并指定了JSON字段的路径和类型: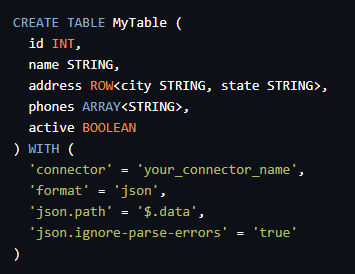
CREATE TABLE MyTable (
id INT,
name STRING,
address ROW<city STRING, state STRING>,
phones ARRAY<STRING>,
active BOOLEAN
) WITH (
'connector' = 'your_connector_name',
'format' = 'json',
'json.path' = '$.data',
'json.ignore-parse-errors' = 'true'
)
3、处理复杂JSON数据:根据定义的表结构,Flink将自动将复杂的JSON数据加载到表中,你可以使用Flink的SQL或Table API来查询和处理这些表数据。
1.插件和库推荐:
* **Json4s**:这是一个灵活的、高效的、纯Scala实现的JSON处理库。
* **Play JSON**:这是一个用于Play框架的JSON库,也适用于Java和Scala项目。
* **Json-Smart**:这是一个快速且灵活的JSON解析和生成库。
2.使用第三方库:
在Flink中解析JSON到表,可以使用Flink自带的JSON库或一些第三方库。对于复杂JSON的处理,一些强大的插件或库可以帮助简化这个过程。以下是一些常用的插件和库:
1.使用Flink自带的JSON库:
Flink自带了一个JSON库,可以用来解析JSON字符串到POJO对象。首先,你需要定义一个与JSON结构匹配的POJO类,然后使用JsonRowDeserializationSchema或JsonRowDeserializationSchemaWithBoundedContext来定义反序列化逻辑。
2.使用第三方库:
* **Jackson**:Jackson是一个常用的Java库,用于处理JSON。你可以使用Jackson的ObjectMapper类来将JSON字符串转换为Java对象。
* **Gson**:Gson是另一个Java库,提供了将JSON字符串转换为Java对象的功能。
* **JSON-java (org.json)**:这是一个纯Java实现的JSON解析库。
Jackson的git地址:https://github.com/FasterXML/jackson
flink 在解析json的时候,可以自己通过 schema(支持复杂的嵌套json),如果不提供 schema,默认使用 table schema 自动派生 json 的 schema。
CREATE TABLE MyUserTable (
...
) WITH (
'format.type' = 'json', -- required: specify the format type
'format.fail-on-missing-field' = 'true' -- optional: flag whether to fail if a field is missing or not, false by default
'format.fields.0.name' = 'lon', -- optional: define the schema explicitly using type information.
'format.fields.0.data-type' = 'FLOAT', -- This overrides default behavior that uses table's schema as format schema.
'format.fields.1.name' = 'rideTime',
'format.fields.1.data-type' = 'TIMESTAMP(3)',
'format.json-schema' = -- or by using a JSON schema which parses to DECIMAL and TIMESTAMP.
'{ -- This also overrides the default behavior.
"type": "object",
"properties": {
"lon": {
"type": "number"
},
"rideTime": {
"type": "string",
"format": "date-time"
}
}
}'
)
——参考链接。
Flink JSON Parser可以将 JSON 数据转换为 Java 对象。支持多种 JSON 格式Flink SQL API 进行查询。
Flink 是一个流处理和批处理的开源框架,它可以处理大规模数据并支持高性能计算。对于从 JSON 解析到表的操作,Flink 本身提供了强大的 JSON 解析器,可以将 JSON 数据转换为 Flink 的 Table API 或 SQL API 的表。
但是,如果你需要更高级的 JSON 解析功能,例如对 JSON 数据的复杂结构和嵌套字段的支持、JSON 数据的自动映射和类型推断等,可以考虑使用一些第三方插件或库来增强 Flink 的 JSON 解析能力。
以下是一些可能对你有帮助的第三方插件和库:
Flink JSON Parser:这是一个基于 Java 的 JSON 解析器,可以在 Flink 中用于将 JSON 数据转换为 Java 对象或使用 Flink SQL API 进行查询。它支持多种 JSON 格式,并提供了灵活的配置选项。
Jackson:Jackson 是一个流行的 Java JSON 处理库,可以用于将 JSON 数据映射到 Java 对象或从 Java 对象生成 JSON 数据。Flink 原生支持 Jackson,因此你可以在 Flink 中使用 Jackson 来解析 JSON 数据。
Gson:Gson 是另一个流行的 Java JSON 处理库,与 Jackson 类似,它可以将 JSON 数据映射到 Java 对象或从 Java 对象生成 JSON 数据。Flink 也支持使用 Gson 来解析 JSON 数据。
JSON Schema Filer:这是一个基于 Flink 的插件,用于在流处理和批处理过程中验证和过滤 JSON 数据。它基于 JSON Schema,可以自动推断 JSON 数据的结构并支持多种过滤和转换操作。
这些插件和库可以帮助你增强 Flink 的 JSON 解析能力,以满足你的具体需求。你可以根据你的项目需求选择适合的插件或库,并查阅它们的文档以了解更多详细信息和用法示例。
Apache Flink 本身没有直接解析 JSON 并将其转换为表的强大插件。但是,你可以使用一些库和工具来实现这个功能。以下是一些可能有助于处理复杂 JSON 并将其转换为表的工具和库:
使用 Flink 提供的 JSON 序列化和反序列化器:
Flink 提供了 org.apache.flink.api.common.serialization.SimpleStringSchema 和 org.apache.flink.api.common.serialization.SimpleStringSchema 类,可以用于将 JSON 字符串序列化和反序列化为字符串。
你可以使用这些类来处理简单的 JSON 数据,但对于复杂的 JSON 数据,可能需要更高级的库。
使用第三方库:
Jackson:Jackson 是一个流行的 Java 库,用于处理 JSON 数据。你可以使用 Jackson 的数据绑定功能将 JSON 转换为 Java 对象,然后使用 Flink 的 Table API 或 SQL API 将这些对象插入到表中。
Gson:Gson 是另一个流行的 Java 库,用于处理 JSON 数据。它提供了简单的方法来将 JSON 字符串转换为 Java 对象。
自定义 UDFs(用户自定义函数):
Flink 支持用户自定义函数,你可以编写自己的 UDF 来解析 JSON 数据并将其转换为表中的行。这需要一些编程知识,特别是关于如何编写 UDFs 和如何在 Flink 中使用它们的知识。
外部工具和系统集成:
一些外部工具和系统(如 Apache Kafka、Apache Kafka Connect 或 Debezium)可以与 Flink 集成,以处理 JSON 数据并将其转换为表。这些工具通常提供了转换器或连接器,可以处理 JSON 数据并将其转换为 Flink 可以处理的格式。
根据你的具体需求和环境,可以选择最适合你的工具或库来解析 JSON 并将其转换为 Flink 表。如果你需要处理复杂的 JSON 数据,可能需要编写自定义代码或使用第三方库来解析和处理这些数据。
Apache Flink 是一个流处理和批处理的开源框架,它提供了强大的数据流处理功能。对于解析 JSON 数据并将其转换为表(通常是数据库表或类似结构),Flink 本身提供了相关的 API 和操作符。
对于复杂的 JSON 数据,你可能需要自定义一些解析逻辑。Flink 的 DataStream 和 DataSet API 都提供了强大的转换功能,你可以利用这些功能来解析 JSON 数据。
例如,你可以使用 Flink 的 JSON 解析库(如 org.apache.flink.api.common.serialization.SimpleStringSchema)来解析 JSON 字符串,然后将其转换为 Flink 的 Row 类型或自定义的数据类型。如果你需要更高级的 JSON 解析功能,可以考虑使用 Flink 的附加库或第三方库,例如:
Json4s: 一个流行的 Scala JSON 库,可以与 Flink 集成。
jackson-module-scala: 另一个 Scala JSON 库,可以与 Flink 集成。
对于复杂 JSON 的解析,你可能需要结合 Flink 的数据流处理逻辑和这些库的功能来实现。
如果你想要一个“插件”或集成方式来简化这个过程,你可能需要查看是否有第三方提供了与 Flink 集成的工具或库,或者是否有社区项目在解决这个问题。但到目前为止,我所了解的信息中并没有专门为 Flink 提供的强大 JSON 到表的转换插件。
Apache Flink 提供了对 JSON 数据的支持,尤其是从 Flink 1.10 版本开始,它引入了内置的 JSON 表格式(JsonRowFormat),允许用户直接将 JSON 数据解析成行格式的表结构。然而,对于非常复杂、嵌套层次深的 JSON 数据,内置的 JSON 支持可能不足以处理所有情况。为了处理复杂的 JSON 结构,可以考虑以下方法:
JSON Schema 和 ROW_DATA 类型:
使用 Flink SQL 中的 CREATE TABLE 语句,并提供详细的 JSON schema 定义,可以解析具有嵌套结构的 JSON。但是请注意,原生支持可能有限,对于某些复杂的嵌套逻辑可能需要额外转换。
自定义序列化器/反序列化器:
创建自定义的 DeserializationSchema 或 TypeInformation,用于解析复杂的 JSON 格式。这允许你根据具体需求实现更灵活和强大的 JSON 解析逻辑。
UDF (User Defined Function):
编写自定义函数来处理特定的 JSON 字段或结构。例如,你可以创建一个 UDF 来处理嵌套 JSON 字符串并提取所需字段。
UDTF (User Defined Table Function):
对于多行映射的场景,可以编写一个 User Defined Table Function,它可以从一个复杂的 JSON 对象中生成多行记录。
社区扩展和第三方库:
社区中可能存在增强 JSON 处理能力的插件或扩展,比如针对 Apache Flink 的开源项目,这些项目可能会提供更强大且易用的 JSON 解析功能。
在面对复杂 JSON 数据时,根据实际情况综合运用以上策略,或者查找是否有针对性的社区解决方案,以满足解析需求。随着 Flink 版本的更新,其对 JSON 的支持也会不断完善和增强。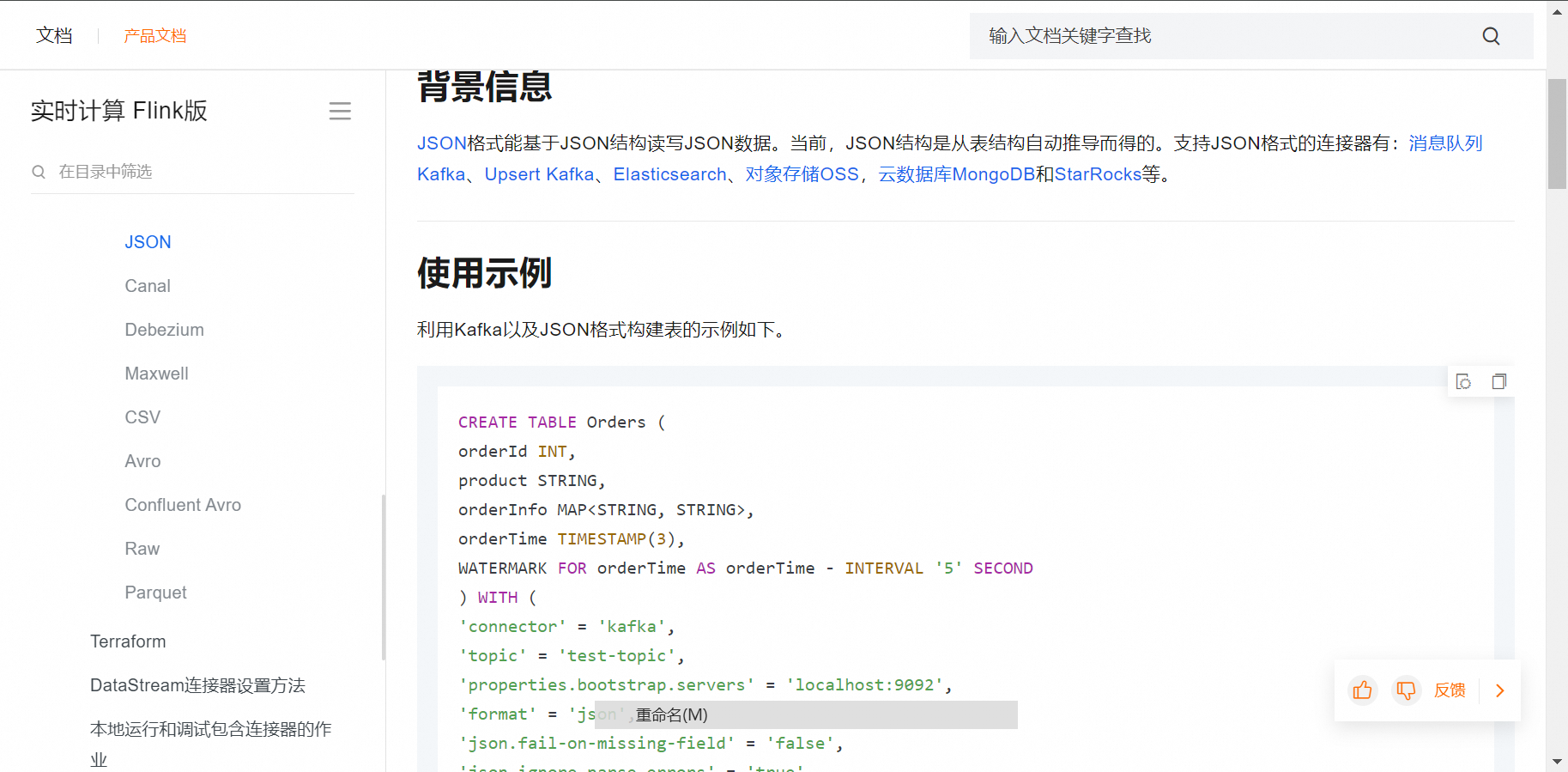
Apache Flink 提供了一个叫做 JsonSerde 的插件,它可以用来解析 JSON 格式的文本数据。这个插件基于 Jackson 库实现了 JSON 到 Avro 和 Avro 到 JSON 的相互转化。
如果你想把复杂的 JSON 对象解析成 Flink 表格,你可以遵循以下步骤:
安装 JsonSerde 插件:在你的 Flink 作业中引用这个插件。例如,如果你的应用依赖的是 Maven,你可以在 pom.xml 文件中添加如下依赖:
<dependency>
<groupId>org.apache.flink.formats.json</groupId>
<artifactId>format-json_2.11</artifactId>
<version>xxx.yyy.zzz</version>
</dependency>
注意:你需要将 xxx.yyy.zzz 替换为你想要的 Flink 版本。
创建 SerDe 注册表:在你的 Flink 作业中注册 SerDeser 接口。例如:
import json
from org.apache.flink.api.common.serialization import GenericRecordSerializer;
from org.apache.flink.api.common.typeinfo.TypeInformation;
def register_json_serdes():
# 创建 serdes 注册表
serde_registry = {
'json': TypeInformation.fromJsonType(json.dumps({
'type': 'map',
'key-type': {'name': 'string', 'namespace': None},
'value-type': {'name': 'record', 'namespace': None}
})),
'avro': TypeInformation.fromSchema('{"type": "record", "name": "MyAvro"}')
}
创建 TableSource:使用 JsonSerde 来创建 TableSource。例如:
# 创建 table source
table_source = env.j棣(
new flink.jdbc.JdbcTableEnvironment(),
new flink.jdbc.JdbcConfiguration("jdbc:mysql://localhost/test"),
new flink.jdbc.JdbcConnectionProperties()
).withSqlDialect(new flink.jdbc.PostgreSQLSqlDialect())
.with_schema_name("public")
.with_table_name("my_table")
.with_format(JsonSerde.Json(), serde_registry)
.as_json();
这只是一个基本示例,实际使用时可能需要根据实际情况做出相应调整。此外,如果你的 JSON 文档比较复杂,可能需要自定义 SerDe 实现来适配不同的需求。
Flink 本身并没有针对 JSON 解析到表的特定插件,但可以使用 Flink 的 Table API 和 JSON Format 来实现这个功能。Flink 的 Table API 提供了流处理和批处理的 SQL 风格,而 JSON Format 则可以方便地读写 JSON 格式的数据。
这里提供一个简单的示例,演示如何使用 Flink Table API 和 JSON Format 将 JSON 数据解析到表中:
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.TableResult;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import java.util.Properties;
public class FlinkJsonToTable {
public static void main(String[] args) throws Exception {
// 创建 Flink 执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 设置 Flink 环境参数
EnvironmentSettings settings = EnvironmentSettings.newInstance().useBlinkPlanner().inBatchMode().build();
// 创建 Table 执行环境
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env, settings);
// 读取 Kafka 主题中的 JSON 数据
DataStream jsonData = env.readTextFile("your_kafka_topic");
// 创建表
Table table = tableEnv.fromDataStream(jsonData, YourJsonSchema.class);
// 使用 SQL 查询将 JSON 数据解析到表中
TableResult result = tableEnv.sqlQuery("SELECT * FROM your_table_name WHERE your_condition");
// 输出结果
result.print();
// 执行 Flink 程序
env.execute("Flink JSON to Table");
}
}
在这个示例中,你需要根据实际的 JSON 数据和表结构来定义一个 YourJsonSchema 类,该类应该包含 JSON 数据中的字段和对应的 Java 类型。
json-simple:一个轻量级的Json解析库,可以方便地将Json数据转换为Java对象
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。