
请教一个大数据计算MaxCompute问题,为什么通过pyodps进行数据写入datetime类型数据,在数据入库后会增加8个小时的时差呢?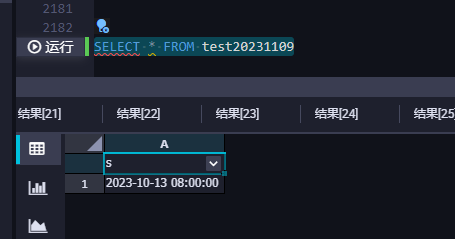
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
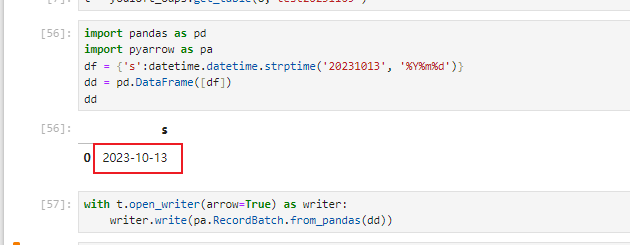
这个问题可能是由于MaxCompute的时区设置和你Python程序的时区设置不一致导致的。MaxCompute默认的时区是UTC,而Python的默认时区是本地时区。如果你的Python程序是在中国运行的,那么本地时区就是东八区,比UTC快8个小时。
为了解决这个问题,你可以在使用PyODPS进行数据写入时,明确指定时区。例如,你可以使用pandas的to_datetime函数,并指定tz参数为'UTC',以确保数据是以UTC时区存储的。
例如:
import pandas as pd
import odps
# 连接到MaxCompute
conn = odps.connect(...)
# 创建一个DataFrame
df = pd.DataFrame({
'date': ['2022-01-01', '2022-01-02'],
'time': ['12:00:00', '12:00:00']
})
# 将日期和时间转换为UTC时区的DateTime类型
df['datetime'] = pd.to_datetime(df['date'] + ' ' + df['time'], format='%Y-%m-%d %H:%M:%S', tz='UTC')
# 将数据写入MaxCompute
conn.write_table('your_table', df, overwrite=True)
这样,你就可以确保数据是以UTC时区存储的,避免了时区差异导致的误差。
由于时区(timezone)设置不同造成的。
配置时区
MaxCompute Project时区默认是中国的东八区,DATETIME、TIMESTAMP、DATE类型字段以及相关时间内置函数按照东八区进行计算。
使用限制及注意事项
SQL内置日期函数、UDF、UDT、UDJ、SELECT TRANSFORM支持获取Project Timezone属性来配置时区。
时区支持的格式类型为Asia/Shanghai(存在夏令时跳变),不支持GMT+9格式。
当SDK时区与Project时区不同时,DATETIME类型转化为STRING类型的操作需设置GMT时区。
时区配置后,通过DataWorks执行相关SQL时,某些时间段的日期显示会存在差异。例如,1900~1928年的日期时间差异为5分52秒,1900年之前的日期时间差异为9秒。
为了保证MaxCompute在多个时区DATETIME类型数据的正确性,MaxCompute服务、Java SDK以及客户端将会进行版本更新(-oversea后缀的Java SDK或客户端版本),更新后可能影响MaxCompute中已经存储的早于1928年的DATETIME类型数据的显示。
对于非中国东八区的区域,建议您同步更新Java SDK或客户端版本,以保证在1900-01-01之后的SQL计算结果及Tunnel传输数据的准确性和一致性。对于早于1900-01-01的DATETIME数据,SQL的计算显示结果和Tunnel传输数据仍然可能存在343秒的差异。对于新版本SDK或客户端,之前已经上传的早于1928-01-01的DATETIME数据,在新版本中日期时间会减少352秒。
如果继续使用不带有-oversea后缀的SDK或客户端,SQL计算结果和Tunnel传输数据将存在差异。早于1900-01-01的数据差异为9秒,1900-01-01~1928-01-01的数据差异为352秒。
说明
Java SDK或客户端版本更新配置时区不影响DataWorks的时区配置,因此时区会存在差异,需要您对DataWorks中定时任务调度的影响进行计算评估。DataWorks服务器在日本区域的时区是GMT+9,在新加坡Region的时区是GMT+8。
通过JDBC连接的第三方客户端需要在客户端设置时区,保证与服务端时区设置的一致性。
MaxCompute(原ODPS)是一项面向分析的大数据计算服务,它以Serverless架构提供快速、全托管的在线数据仓库服务,消除传统数据平台在资源扩展性和弹性方面的限制,最小化用户运维投入,使您经济并高效的分析处理海量数据。


