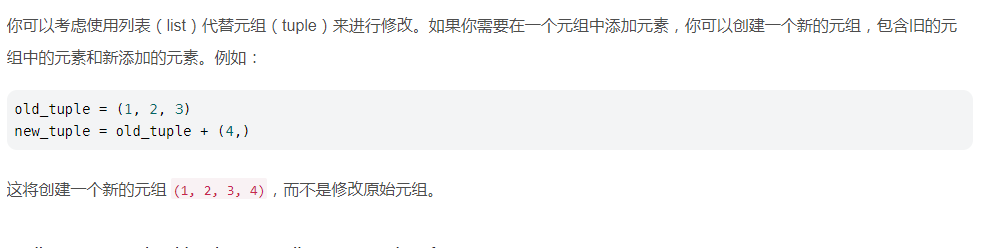
在大数据计算MaxCompute中,请问这个报错如何解决? 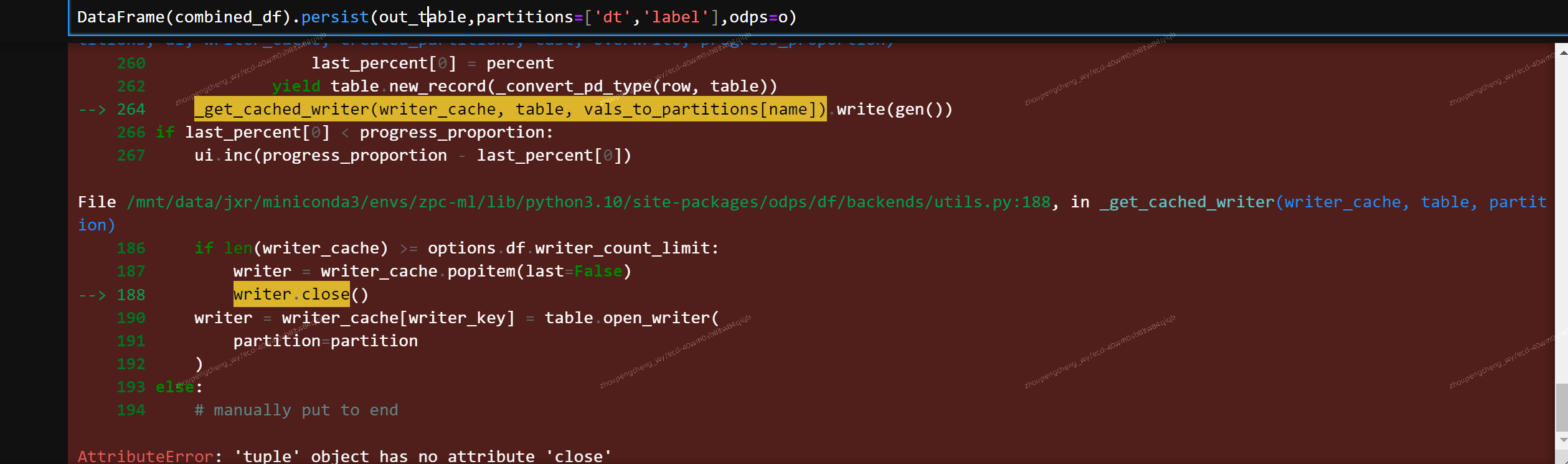
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
写入器对象可能没有被正确初始化。
writer_cache 字典中可能错误地存储了元组而不是写入器对象。
代码中可能存在类型错误或逻辑错误,导致写入器对象被错误地处理为元组
确保 writer_cache 中存储的是写入器对象,而不是其他类型的对象,如元组。
在关闭写入器之前添加日志记录,打印出 writer_cache 的内容和类型,以便于调试。
在大数据计算服务MaxCompute中遇到问题时,根据具体情况有不同的解决方案。以下是针对几种典型错误的解决办法:
Expression not in GROUP BY keyExpression not in GROUP BY key。GROUP BY子句中。例如,如果报错的表达式为coalesce( sum(column), 0 ),则应调整为GROUP BY coalesce( sum(column), 0 )。CAST函数进行显式类型转换,或者关闭新数据类型开关(odps.sql.type.system.odps2=false)来避免精度损失或错误。
相关链接
https://help.aliyun.com/zh/maxcompute/user-guide/faq-about-built-in-functions
以下是一些常见的MaxCompute错误及其可能的解决方案:
Syntax error: expected EOF but got identifier "xxx"Access denied for user 'xxx' to database 'yyy'GRANT语句来授权。Exceeds the resource limit: CPU/ Memory/ Task numberData type mismatchTable/Column not found这个错误提示表明在Python代码执行过程中遇到了一个AttributeError,具体原因是尝试对一个'tuple'对象调用'close'方法,而'tuple'类型并没有提供该方法。为了解决这个问题,我们需要找到并修复导致此错误的代码行。在这个例子中,出错的代码行是第188行(File '/mnt/data/...)。从上下文可以推测,在某些情况下,writer_cache.popitem(last=False) 可能返回了一个'tuple'而不是预期的可关闭的对象。为了修正它,可以在调用writer.close()之前添加一个条件判断,确保获取到的是一个可关闭的对象:
这样就可以避免尝试对'tuple'对象调用'close'方法了
确保源表和目标表的表结构一致,包括字段名、字段类型、字段顺序等。
检查数据类型是否匹配,例如,确保源表中的整型字段在目标表中也是整型,而不是字符串或其他类型。
验证SQL语句:
检查SQL语句的语法是否正确,包括SELECT、INSERT、UPDATE等语句的使用。
确保SQL语句中的表名、字段名没有拼写错误。
如果SQL语句包含复杂的逻辑或子查询,尝试简化它以排除潜在的错误源。
检查权限和网络:
确保你有足够的权限访问和操作相关的表和字段。
检查网络连接是否稳定,特别是当涉及到跨网络的数据传输时。
查看资源使用情况:
检查MaxCompute集群的资源使用情况,包括内存、CPU和磁盘空间。
如果资源不足,考虑增加资源或优化查询语句以减少资源消耗。
查阅文档和社区:
查阅MaxCompute的官方文档,了解关于报错信息的详细解释和解决方案。
搜索相关的技术论坛和社区,看看是否有其他用户遇到过类似的问题并找到了解决方案。
由于您没有提供具体的报错信息,我无法为您提供针对性的解决方案。但是,我可以给您一些建议来解决MaxCompute中的常见错误:
检查您的SQL语句是否正确。确保语法、表名和列名都是正确的。您可以在MaxCompute控制台的“开发与作业”页面中测试SQL语句。
确保您的数据表已经创建并且包含了所需的列。您可以使用DESCRIBE命令查看表的结构。
检查您的数据类型是否匹配。例如,如果您尝试将字符串类型的数据与数字类型的数据进行比较,可能会导致错误。确保您的数据类型是正确的。
检查您的权限设置。确保您有足够的权限来访问和操作数据表。
如果问题仍然存在,请查看MaxCompute的错误日志以获取更多详细信息。这将帮助您更好地了解问题所在并找到解决方案。
如果您能提供更多关于错误的详细信息,我将更乐意为您提供帮助。
在大数据计算MaxCompute中,遇到报错时,可以通过以下步骤进行解决:
识别错误类型:根据错误码格式判断出现错误的模块、错误等级及产生原因。例如,ODPS-0010000表示系统内部错误,ODPS-0130071则与SQL作业相关。
查阅文档:查看MaxCompute的错误码列表及其触发条件和解决方法,这有助于快速定位问题所在。
检查配置:确认输入的IP地址是否正确,确保是公网可访问的IP地址。如果IP地址正确但仍有问题,尝试更换新的IP地址或联系网络管理员获取正确的IP地址。
调整代码:如果是由于表不存在导致的错误(如ODPS-0130131),可以尝试自建缺失的表。如果是列数或类型不匹配的问题(如ODPS-0130071),需要检查源表字段,增加相应字段或调整目标表结构。
使用Logview:如果错误原因复杂,可以通过Logview定位错误位置,查看作业运行信息以帮助解决问题。
权限设置:确保RAM用户有足够的权限访问MaxCompute资源。如果权限不足,需要进行相应的授权操作。
时间同步:如果使用MaxCompute客户端连接服务时报错(如ODPS-0410031),可能是因为设备本地时间与服务器时间不一致。此时需要调整设备时间后重新启动客户端。
分区操作:对于并发添加分区导致的错误(如ODPS-0110061),应避免同时对同一个分区进行多次操作,或者使用IF NOT EXISTS来避免冲突。
编码问题:如果数据存储后变成乱码,考虑更改字符编码为UTF-8。
版本兼容性:检查使用的SDK或客户端版本是否与MaxCompute服务兼容,有时更新到最新版本可以解决已知的问题。
总的来说,通过上述步骤,可以有效地诊断和解决MaxCompute中的报错问题。如果问题依旧无法解决,建议联系阿里云技术支持获取进一步帮助。
这个错误信息表明您正在尝试调用一个对象的close()方法,但是该对象实际上是一个元组(tuple),而元组没有close()方法。
根据您提供的代码片段,问题可能出现在以下行
在这个例子中,_get_cached_writer函数返回了一个元组,而不是预期的可以关闭的对象。
为了解决这个问题,您可以检查_get_cached_writer函数的实现,并确保它返回的是一个具有close()方法的适当对象,而不是一个元组。如果_get_cached_writer函数应该返回单个值而非元组,则应修改其内部逻辑以正确地返回所需类型的对象。
如果您确定_get_cached_writer函数应该返回多个值,那么请使用适当的变量来接收这些值,而不是将它们作为元组传递给writer变量。例如:
这样每个返回值都会被分配到单独的变量,从而避免了试图对元组调用close()方法的问题。
应该意味着代码尝试对一个元组对象执行它不支持的操作。在您提供的错误信息中,问题出现在尝试关闭一个元组对象,而元组并没有close方法
你可以检查对象类型--》确保您操作的对象是DataFrame而不是元组。您可以通过添加类型检查来避免对元组执行不支持的操作
另外在PyODPS中,确保您使用正确的API来处理DataFrame。例如,如果您需要写入数据,使用DataFrame的persist方法,而不是尝试对元组执行操作

要解决MaxCompute中的报错,首先需要明确具体的错误信息。MaxCompute(原名ODPS)是阿里云提供的一种大数据处理平台,常用于大规模数据的存储和分析。报错可能来自多种原因,包括但不限于SQL语法错误、资源限制、权限问题等。
由于你没有提供具体的错误信息或代码示例,我将提供一些常见的错误类型及其可能的解决方案,并给出一个简单的代码示例和可能遇到的错误及其解决方法。
常见错误类型及解决方案
SQL语法错误
确保SQL语句符合MaxCompute的语法规则。
检查是否有拼写错误、遗漏的关键字或错误的函数名。
权限问题
确认执行SQL的用户是否有足够的权限访问指定的表或执行相应的操作。
如果需要,向管理员申请相应的权限。
资源限制
检查是否达到了MaxCompute的资源使用限制,如单个作业的最大运行时间、最大数据量等。
优化查询,减少资源消耗,或考虑分批处理数据。
数据类型不匹配
确保在比较或计算中使用的数据类型是兼容的。
使用CAST函数转换数据类型。
示例代码及可能错误
假设我们有一个表sales,包含字段date(日期)和amount(销售额)。我们想查询销售额最大的那一天。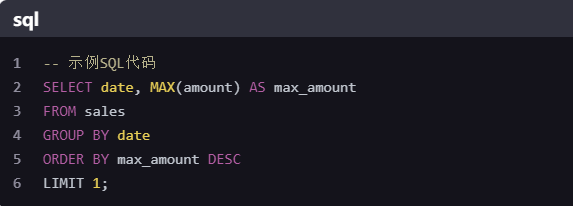
可能遇到的错误及解决方案
错误:表或字段不存在
错误信息:[ODPS-0123456]:Table or column not found
解决方案:确认表名和字段名是否正确,包括大小写和拼写。
错误:数据类型不匹配
错误信息:[ODPS-0123457]:Function not support this data type
解决方案:检查amount字段的数据类型是否为数值类型。如果不是,使用CAST(amount AS BIGINT)等转换函数。
错误:资源限制
错误信息:[ODPS-0123458]:Exceed resource limits
解决方案:优化查询,比如减少GROUP BY的字段数量,或使用更高效的算法。
错误:权限不足
错误信息:[ODPS-0123459]:No privilege to access this table
解决方案:向项目管理员申请访问该表的权限。
从你提供的错误信息来看,问题似乎发生在使用 MaxCompute(原名ODPS)进行数据处理时,特别是在尝试写入数据到表的过程中。错误信息中提到了 _get_cached_writer 函数,这表明在获取或关闭 writer 时出现了问题。以下是一些可能的原因和解决方法:
Writer 缓存限制:
options.df.writer_count_limit,这意味着你的 writer 缓存数量达到了上限,导致新的 writer 创建失败。Writer 关闭异常:
writer.close(0) 这一行可能是试图关闭一个 writer,但如果这个 writer 已经被关闭或者不存在,可能会抛出异常。分区键不匹配:
Python 版本或库版本不兼容:
其他编程错误:
options.df.writer_count_limit 的设置是否合理。如果需要频繁地打开和关闭 writer,可以适当增加这个限制。from odps import options
options.df.writer_count_limit = 100 # 根据实际情况调整
try...finally 块来确保即使发生异常也会关闭 writer。try:
writer = table.open_writer(partition=partition)
# 写入数据
finally:
if writer is not None:
writer.close()
pip install pyodps==<version>
这里是一个示例代码片段,展示了如何安全地处理 writer 并确保它被正确关闭:
from odps import ODPS, options
from odps.df import DataFrame
# 初始化 ODPS 客户端
odps = ODPS('<your-access-id>', '<your-access-key>', '<your-project-name>', endpoint='<your-endpoint>')
# 设置 writer 缓存限制
options.df.writer_count_limit = 100
# 获取表对象
table = odps.get_table('<your-table-name>')
# 分区键
partition = 'dt=20230101'
# 数据
data = [{'col1': 'value1', 'col2': 123}]
# 写入数据
try:
with table.open_writer(partition=partition) as writer:
for row in data:
record = table.new_record()
for col_name, value in row.items():
setattr(record, col_name, value)
writer.write(record)
except Exception as e:
print(f"Error occurred: {e}")
通过以上步骤,你应该能够找到并解决这个问题。如果问题仍然存在,请提供更详细的代码和错误日志,以便进一步诊断。
成功解决AttributeError: ‘Tuple’对象没有属性‘shape’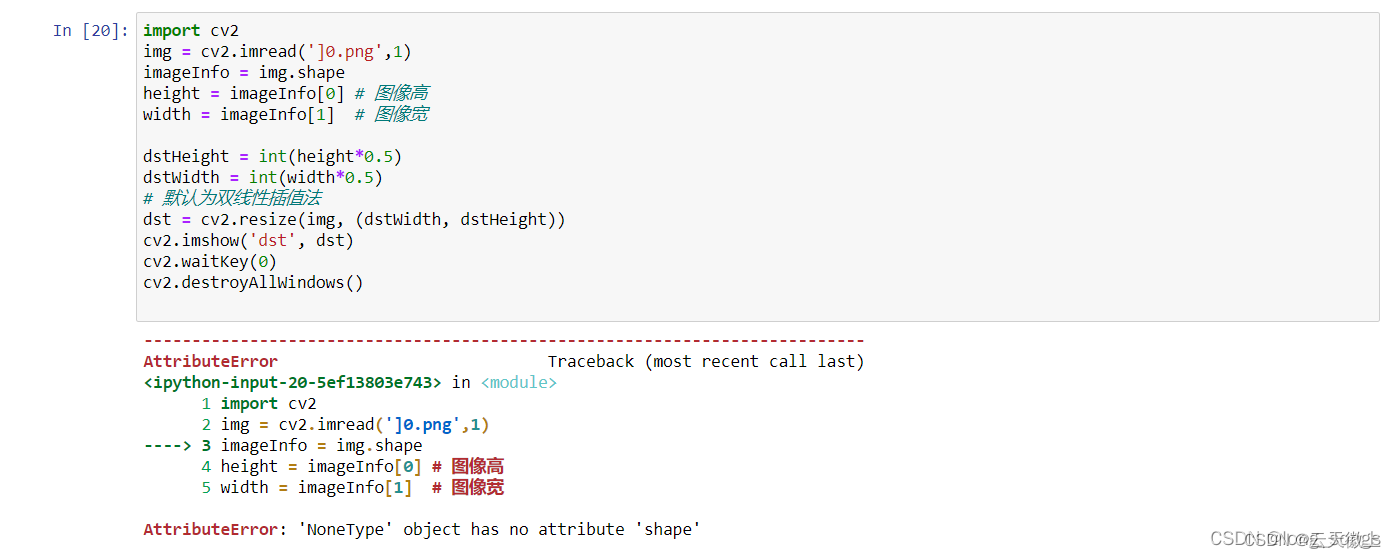
针对上述的错误原因,我们可以采取以下解决办法:
import numpy as np
def print_shape(arr):
if isinstance(arr, np.ndarray):
print(arr.shape)
else:
print("Error: 输入的不是NumPy数组")
示例用法
arr = np.array([[1, 2, 3], [4, 5, 6]])
print_shape(arr) # 输出: (2, 3)
tup = (1, 2, 3)
print_shape(tup) # 输出: Error: 输入的不是NumPy数组
def create_array():
# 原本错误地返回了一个元组
# return (1, 2, 3)
# 修正后,返回了一个NumPy数组
return np.array([1, 2, 3])
arr = create_array()
print(arr.shape) # 输出: (3,)
def process_array(arr):
if not isinstance(arr, np.ndarray):
raise TypeError("输入参数必须是NumPy数组")
# 后续处理...
print(arr.shape)
arr = np.array([[1, 2, 3], [4, 5, 6]])
process_array(arr) # 输出: (2, 3)
tup = (1, 2, 3)
process_array(tup) # 抛出TypeError: 输入参数必须是NumPy数组
tup = (1, 2, 3)
arr = np.array(tup)
print(arr.shape) # 输出: (3,)
注意:如果元组包含嵌套结构,转换可能需要更复杂的逻辑
参考文档https://blog.csdn.net/qq_38614074/article/details/139863248
MaxCompute(原ODPS)是一项面向分析的大数据计算服务,它以Serverless架构提供快速、全托管的在线数据仓库服务,消除传统数据平台在资源扩展性和弹性方面的限制,最小化用户运维投入,使您经济并高效的分析处理海量数据。