
文字识别OCR在标注阶段是两个独立的字段,返回的信息将两个字段合并了,怎么处理?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在处理OCR识别出的两个独立字段并返回的信息时,您可以使用一些处理方法将这两个字段合并成一段。例如,如果这两个字段之间用特定的符号或字符分隔,您可以使用这些符号或字符作为分隔符,将两个字段的信息连接起来。
另外,您还可以考虑使用正则表达式来匹配和提取需要的信息。通过编写合适的正则表达式模式,您可以从返回的信息中准确地提取出两个字段的内容,并将它们合并成一段。
如果您使用的是Python编程语言,可以使用字符串的join方法或者replace方法来实现这个目标。下面是一个示例代码,展示了如何使用replace方法将两个字段的信息合并:
# 假设 field1 和 field2 是您要合并的两个字段
field1 = "第一段文字"
field2 = "第二段文字"
# 使用 replace 方法将两个字段的信息合并
merged_field = field1.replace("第一段文字", "").replace("第二段文字", "")
print(merged_field)
在文字识别OCR的过程中,如果标注阶段设定了两个独立的字段,但在返回的信息中却合并成了一个字段,那么有几种可能的方法来解决这个问题:
在OCR的文字识别过程中,可能有时会出现两个独立字段被错误地标记为一个字段,导致信息无法按预期的方式分开。以下是一些可能的解决方案:
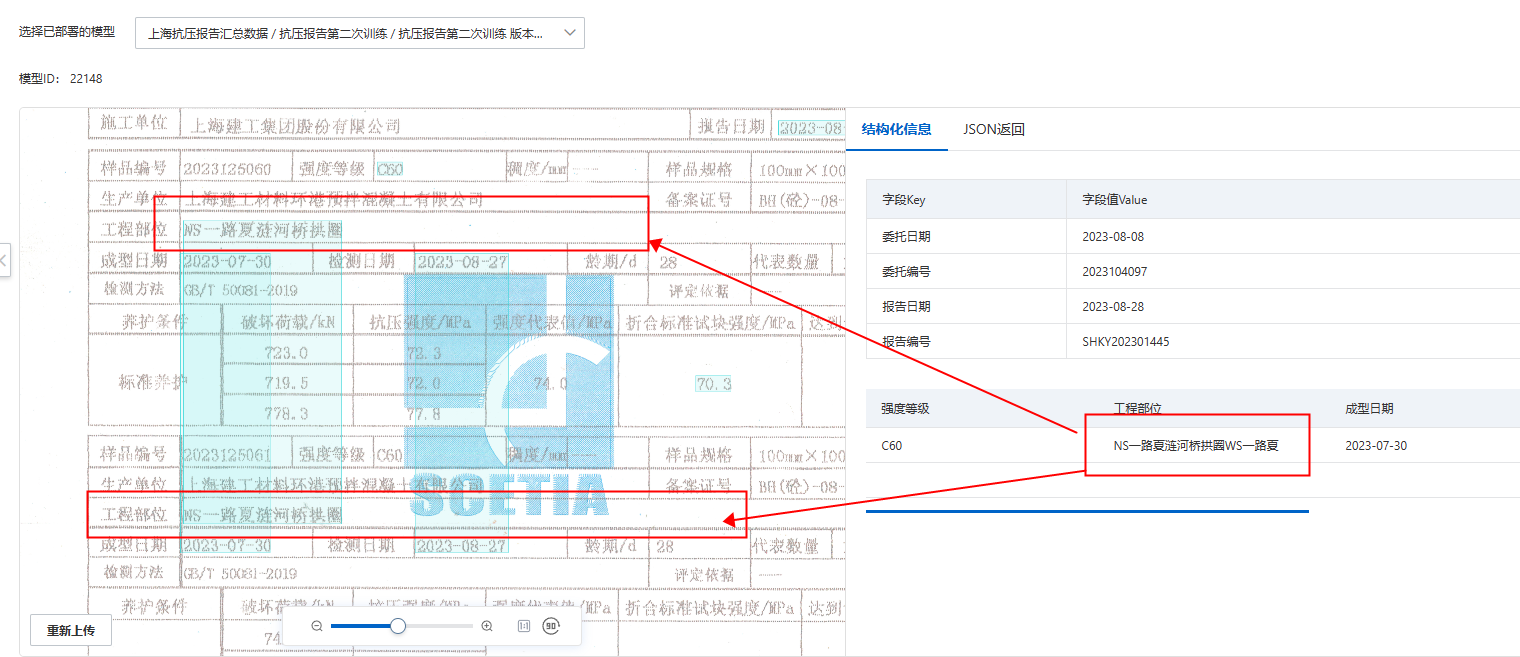
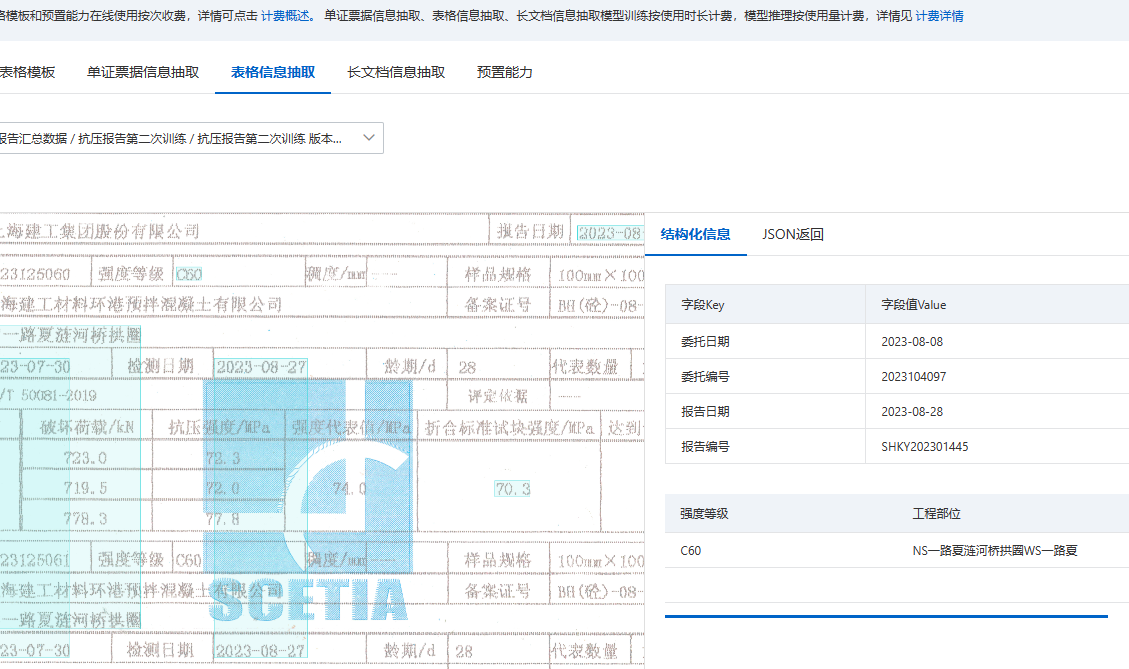
表格信息抽取的表格抽取题目只适合list列表型表格,这类kv字段型表格可以用kv字段做抽取。此回答整理自钉群“【官方】阿里云OCR文档自学习用户答疑群”


