
Flink CDC有什么办法调整一下把这个数据跑完么?
Flink CDC有什么办法调整一下把这个数据跑完么?
我有个测试库,有8000W数据,只是读出来,做chekcpoint的时候,报数组分配溢出了?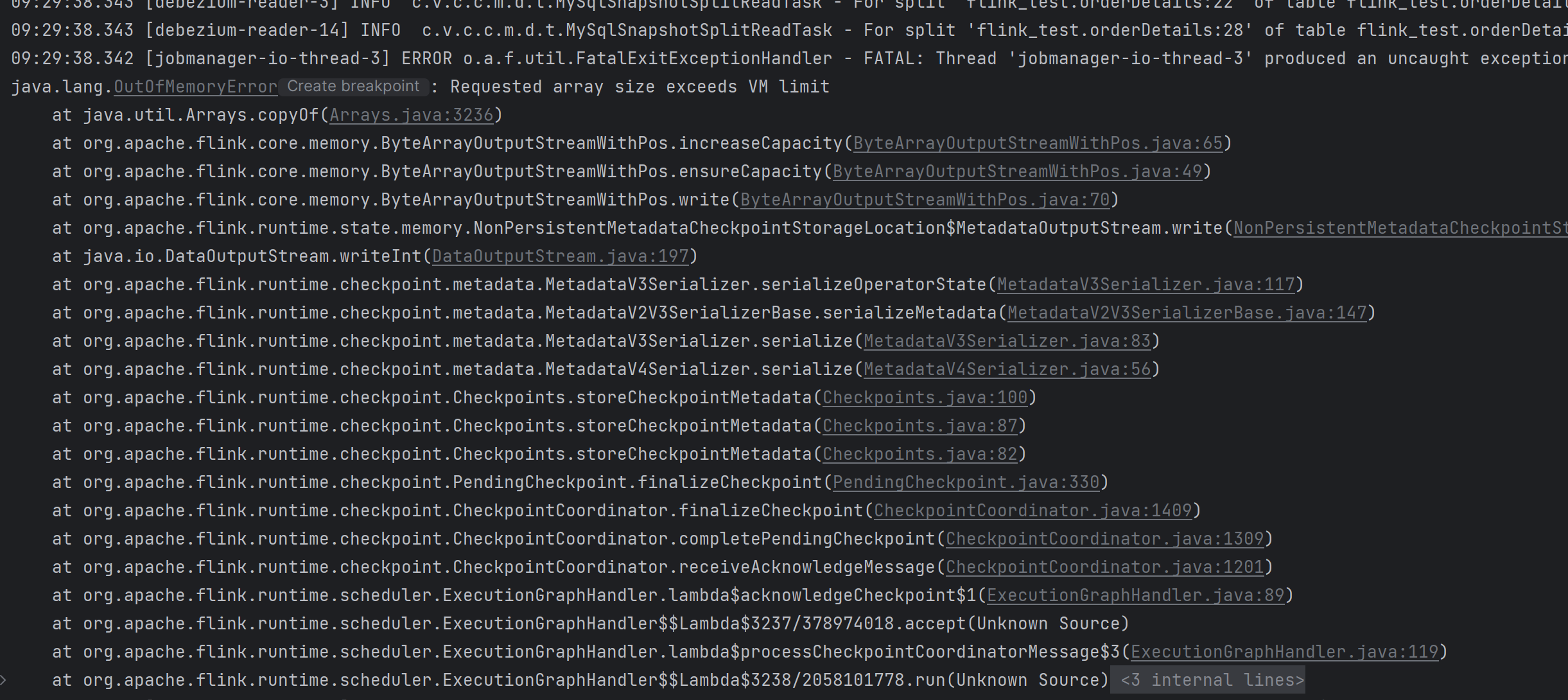
展开
收起
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
4
条回答
写回答
-
面对过去,不要迷离;面对未来,不必彷徨;活在今天,你只要把自己完全展示给别人看。
遇到这个问题可能是因为数据量太大或者 Flink Checkpoint 记录了太多的历史信息。可以通过以下方式调整任务:
- 限制 Checkpoint 的数量和大小:可以在 flink-conf.yaml 中设置 checkpointing.checkpoints.max-retained 参数来限制 Checkpoint 数量。
- 缩减 Checkpoint 中的状态信息:可以在 flink-conf.yaml 中设置 state.backend.local-recovery 和 state.backend.fs.checkpointdir 参数,精简 Checkpoint 中保存的内容。
- 关闭 Checkpoint:对于实时数据传输,您可以尝试关闭 Checkpoint 功能,然后定期保存快照,以节省空间。
2023-11-02 14:59:43赞同 展开评论 -
在Flink中,处理大量数据时,可能会遇到内存分配溢出的问题。这通常是由于Flink任务试图分配超出可用内存的内存量所导致的。对于这种情况,以下是一些可能的解决方案:
- 增加TaskManager的内存:如果您的Flink集群具有足够的资源,可以尝试增加TaskManager的总内存大小。这可以通过调整
taskmanager.memory.process.size参数来实现。增加TaskManager的内存可以使得Flink任务有更多的内存来处理数据。 - 调整任务并行度:通过调整任务的并行度,您可以控制同时运行的任务数量。降低任务的并行度可以减少同时处理的数据量,从而降低内存需求。但是请注意,这可能会影响整体的处理速度。
- 优化代码逻辑:检查您的Flink作业的代码逻辑,看是否存在可以优化的地方。例如,您可以尝试减少状态转换、缓存或数据倾斜等操作,这些操作可能会消耗大量的内存。
- 使用合适的数据类型:在Flink中,使用合适的数据类型可以有效地减少内存需求。例如,如果您知道您的数据不会有大范围的值,那么使用范围较小的数据类型可能更合适。
- 使用持久化层:如果可能的话,可以考虑在处理数据时使用持久化层。这样,即使在发生故障时,您也可以从持久化层恢复数据,而不需要将所有数据都存储在内存中。
- 调整Flink的配置参数:Flink提供了一些配置参数来调整内存使用。例如,您可以调整任务内存和管理内存的大小,以及其他与内存相关的参数。
对于您提到的"数组分配溢出",这可能是由于在创建和操作大型数组时超过了可用内存。在Flink中处理大量数据时,建议使用具有良好空间复杂性的数据结构,并避免创建过大的数组。
2023-11-02 14:45:43赞同 展开评论 - 增加TaskManager的内存:如果您的Flink集群具有足够的资源,可以尝试增加TaskManager的总内存大小。这可以通过调整
-
-
Flink CDC有一些优化策略和参数可以帮助提高性能和稳定性。以下是一些建议:
- 可以使用Flink CDC的分流模式,将全量数据和增量数据分别写入不同的目标表,以减少写入压力和冲突。
- 可以使用Flink CDC的并行度参数,根据数据源表的分区数和目标表的分片数,合理设置并行度,以提高读写效率。
- 可以使用Flink CDC的扫描间隔参数,根据数据变化频率和延迟要求,合理设置扫描间隔,以减少对数据源表的压力和资源消耗。
- 可以使用Flink CDC的重试策略参数,根据网络状况和容错能力,合理设置重试次数和重试间隔,以应对可能出现的异常或故障。
2023-11-01 14:53:20赞同 1 展开评论

问答分类:
问答地址:
开发者社区
>
大数据与机器学习
>
实时计算 Flink
>
问答
相关问答

实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。
相关文章
热门讨论
热门文章
展开全部
还有其他疑问?
咨询AI助理