
Flink CDC有谁搞过tidb-cdc的?
Flink CDC啥问题大佬们啊,有谁搞过tidb-cdc的?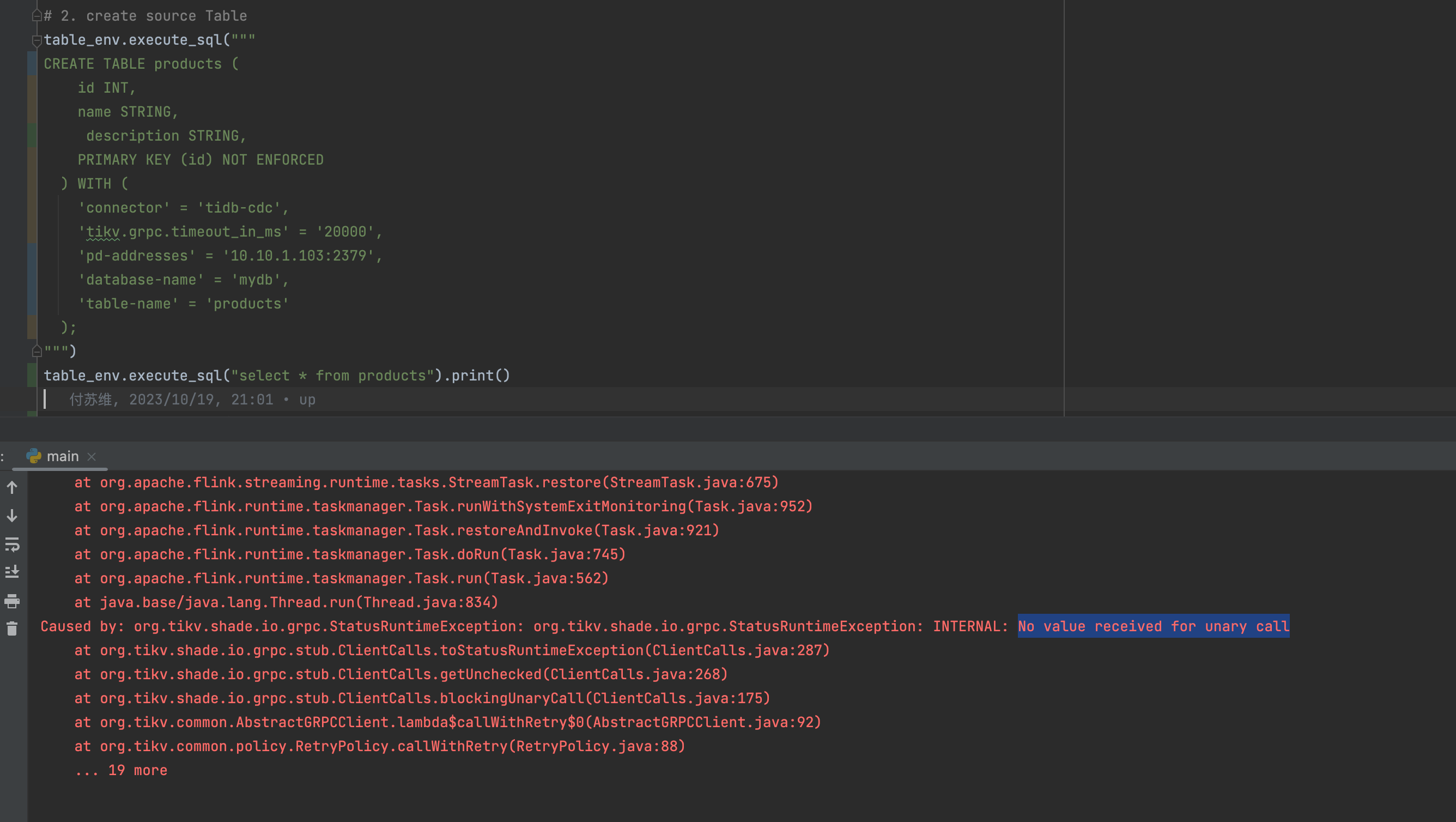
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
关于Flink CDC与TiDB-CDC的集成和使用,以下是一些可能遇到的问题及其解决方案,基于您提供的知识库内容进行整理和扩展:
1. TiDB-CDC的基本工作原理
TiDB-CDC 是一个用于捕获 TiDB 数据库中数据变更的工具。它通过监听 TiDB 的事务日志(TiKV 的 Raft Log)来捕获数据变更,并将这些变更以事件流的形式输出到下游系统(如 Kafka、Flink 等)。Flink CDC 可以通过连接 TiDB-CDC 提供的数据流,实现对 TiDB 数据变更的实时处理。
关键点: - TiDB-CDC 输出的数据格式通常为 Debezium 格式,因此 Flink CDC 可以直接使用 Debezium 连接器进行消费。 - 需要确保 TiDB-CDC 服务正常运行,并正确配置了下游数据输出的目标(如 Kafka)。
2. 常见问题及解决方案
2.1 数据延迟或丢失
问题描述: 在使用 Flink CDC 消费 TiDB-CDC 数据时,可能会出现数据延迟或丢失的情况。
原因分析: - TiDB-CDC 的日志同步速度较慢,导致数据未能及时写入下游。 - Flink 作业的 Checkpoint 配置不合理,可能导致数据处理中断或重复消费。
解决方案: 1. 优化 TiDB-CDC 配置: - 增加 TiDB-CDC 的并发度,提升日志同步速度。 - 调整 TiDB-CDC 的 sink-uri 参数,确保下游 Kafka 的分区数足够多,避免成为性能瓶颈。 2. 调整 Flink Checkpoint 配置: - 设置合理的 Checkpoint 间隔时间,例如每分钟触发一次: yaml execution.checkpointing.interval: 60s - 启用 Exactly-Once 语义,确保数据一致性: yaml execution.checkpointing.mode: EXACTLY_ONCE
2.2 数据类型不匹配
问题描述: 在 Flink 中消费 TiDB-CDC 数据时,可能会遇到数据类型不匹配的问题,例如数值类型被解析为字符串。
原因分析: - TiDB-CDC 输出的 Debezium 数据格式中,某些字段的类型可能与 Flink 的期望类型不一致。 - Flink CDC 默认的反序列化器未正确处理 TiDB 的数据类型。
解决方案: 1. 自定义反序列化器: - 使用 JsonDebeziumDeserializationSchema 并配置相关参数,确保数值类型正确解析。例如: ```java Properties properties = new Properties(); properties.setProperty("bigint.unsigned.handling.mode", "long"); properties.setProperty("decimal.handling.mode", "double");
MySqlSource.<String>builder()
.hostname(config.getHostname())
.port(config.getPort())
.databaseList(config.getDatabaseList())
.tableList(config.getTableList())
.username(config.getUsername())
.password(config.getPassword())
.deserializer(new JsonDebeziumDeserializationSchema())
.debeziumProperties(properties)
.build();
```
- 检查 TiDB 表结构:
- 确保 TiDB 表中的字段类型与下游系统的字段类型兼容。如果不兼容,可以通过 Flink SQL 的
CAST函数进行类型转换。
- 确保 TiDB 表中的字段类型与下游系统的字段类型兼容。如果不兼容,可以通过 Flink SQL 的
2.3 全量阶段卡住或失败
问题描述: Flink CDC 在读取 TiDB 数据时,全量阶段可能会卡住或失败。
原因分析: - TiDB 的全量数据量过大,导致单个分片的数据处理时间过长,出现 OOM(内存溢出)问题。 - TiDB 的表结构复杂,包含大量索引或大字段,增加了全量读取的开销。
解决方案: 1. 增加并发度: - 提高 Flink 作业的并行度,加快全量数据的读取速度。例如: yaml parallelism.default: 4 2. 跳过全量阶段: - 如果不需要全量数据,可以通过 scan.startup.mode 参数跳过全量阶段,直接从增量数据开始消费: sql 'scan.startup.mode' = 'latest-offset'
2.4 时间戳字段时区问题
问题描述: 在读取 TiDB 数据时,timestamp 字段的时区可能与预期不符,例如相差 8 小时。
原因分析: - TiDB-CDC 输出的时间戳字段未正确设置时区信息。 - Flink CDC 的 server-time-zone 参数未与 TiDB 服务器的时区保持一致。
解决方案: 1. 配置时区参数: - 在 Flink CDC 的配置中,明确指定 server-time-zone 参数。例如: sql 'server-time-zone' = 'Asia/Shanghai' 2. 检查 TiDB 服务器时区: - 确保 TiDB 服务器的时区设置正确。可以通过以下命令查看和修改时区: sql SHOW VARIABLES LIKE 'time_zone'; SET GLOBAL time_zone = '+08:00';
3. 性能优化建议
为了提升 Flink CDC 与 TiDB-CDC 的集成性能,可以参考以下优化建议: 1. 合理分配资源: - 为 Flink 作业分配足够的 TaskManager 和内存资源,避免因资源不足导致性能瓶颈。 2. 启用数据压缩: - 如果下游存储支持数据压缩(如 Kafka 的 LZ4 或 Deflate),可以在 TiDB-CDC 的 sink-uri 中启用压缩功能。 3. 监控与告警: - 使用 Flink 的监控指标(如 currentEmitEventTimeLag)实时跟踪数据延迟情况,及时发现并解决问题。
4. 相关文档推荐
- SQL作业开发:了解如何使用 SQL 开发 Flink 作业,简化数据处理逻辑。
- CDC问题:汇总了 Flink CDC 使用过程中常见的问题及其解决方案。
- 数据同步模板:提供典型的数据同步案例,帮助优化数据同步任务。
以上是针对 Flink CDC 与 TiDB-CDC 集成的常见问题及解决方案。如果您有更具体的问题或场景,请进一步补充说明,我将为您提供更详细的解答!

实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。