Flink cdc2.0用下来,发现全量故障恢复不能从checkpoint点恢复?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
楼主你好,如果你在使用阿里云Flink CDC 2.0时发现全量故障恢复无法从检查点恢复,可能是Checkpoint 配置问题,请确保正确配置了 Flink 的 Checkpoint 相关参数,包括 Checkpoint 间隔、最大并发数等,检查点机制是用来保证故障时的状态一致性,如果配置有误,可能导致无法从检查点恢复。
还有就是状态后端问题,检查点数据被存储在状态后端中,确保正确配置了 Flink 的状态后端,可以选择支持持久化的状态后端,如RocksDB 或 HDFS。如果状态后端配置不正确,可能导致检查点数据无法被正确恢复。
Flink cdc2.0在使用过程中,确实存在一些问题,特别是在全量故障恢复时可能无法从checkpoint点恢复。这可能是由于Flink cdc2.0的设计或者实现上的缺陷导致的。
为了解决这个问题,可以考虑以下几个方案:
升级Flink版本:Flink社区一直在不断改进和优化Flink的各个版本。如果您的Flink版本较旧,可以考虑升级到最新版本,以获得更好的性能和稳定性。
调整checkpoint参数:在Flink中,checkpoint是用于故障恢复的重要机制。可以通过调整checkpoint的参数,如checkpoint的频率、保存point的频率等,来提高故障恢复的效率和可靠性。
使用外部存储:如果Flink无法从内部存储中恢复,可以考虑使用外部存储来保存checkpoint和元数据。这样即使Flink出现问题,也可以从外部存储中恢复数据。
优化代码:如果以上方案都无法解决问题,可以考虑优化代码。例如,优化Flink cdc2.0的算法和数据结构,以提高性能和稳定性。
总之,解决Flink cdc2.0的全量故障恢复问题可能需要一些尝试和努力。建议根据实际情况选择合适的方案,并参考Flink社区的文档和资源来解决问题。
如果在使用 Flink CDC 2.0 过程中发现,全量故障恢复时不能从 checkpoint 点恢复,可能是由于以下原因导致的:
ExecutionConfig#setCheckpointingMode() 和 StreamExecutionEnvironment#enableCheckpointing() 来启用和配置 checkpoint。state.backend 和 state.checkpoints.dir 来为 checkpoint 提供持久化存储。如果上述步骤都已经排查,并仍然无法从 checkpoint 点进行全量恢复,请查看日志文件以获取更多详细的错误信息。可能还需要进一步分析和调试来确定具体的故障原因。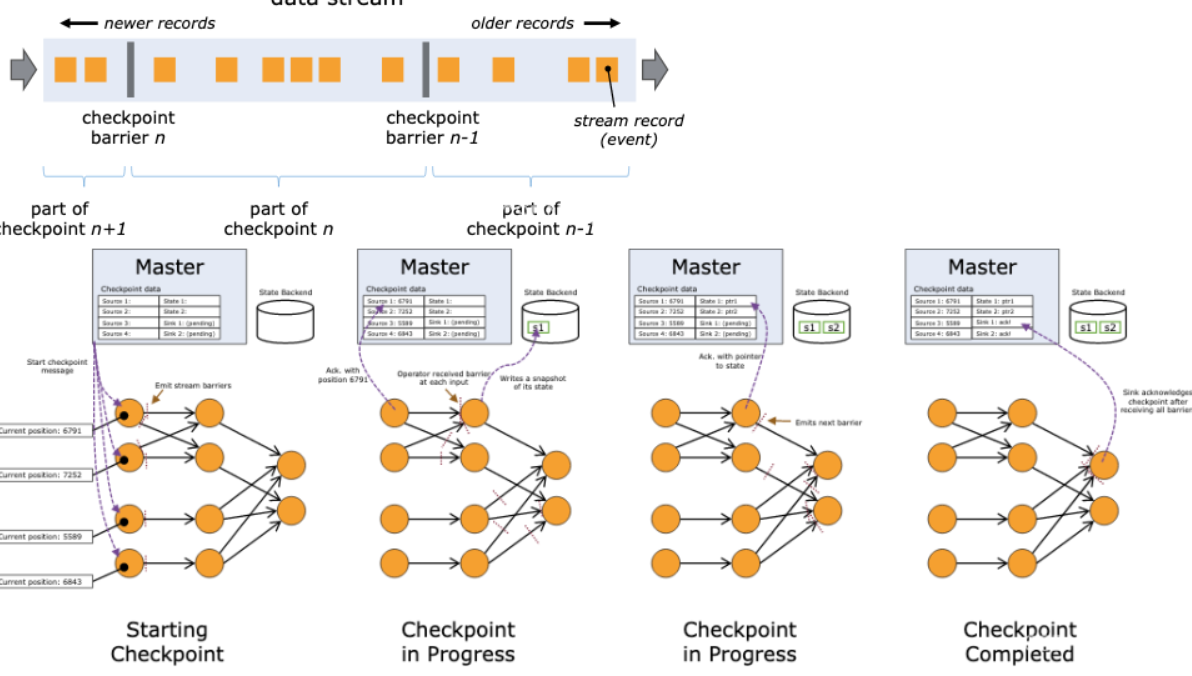
可以从checkpoint点恢复。
Checkpoint是一种分布式快照:在某一时刻,对一个Flink 作业所有的task做一个快照(snapshot),并且将快照保存在 memory / file system等存储系统中。这样,在任务进行故障恢复的时候,就可以还原到任务故障前最近一次检查点的状态,从而保证数据的一致性。当然,为了保证exactly-once / at-least-once的特性,还需要数据源支持数据回放。
Flink 分布式快照的核心在与stream barrier,barrier是一种特殊的标记消息,会和正常的消息记录一起在数据流中向前流动。Checkpoint Coordinator 在需要触发检查点的时候要求数据源向数据流中注入barrie,barrier和正常的数据流中的消息一起向前流动,相当于将数据流中的消息切分到了不同的检查点中。当一个operator从它所有的input channel 中都收到了barrier,则会触发当前operator 的快照操作,并向其下游 channel 中发射 barrier。当所有的sink都反馈完成了快照之后,CheckpointCoordinator认为检查点创建完毕。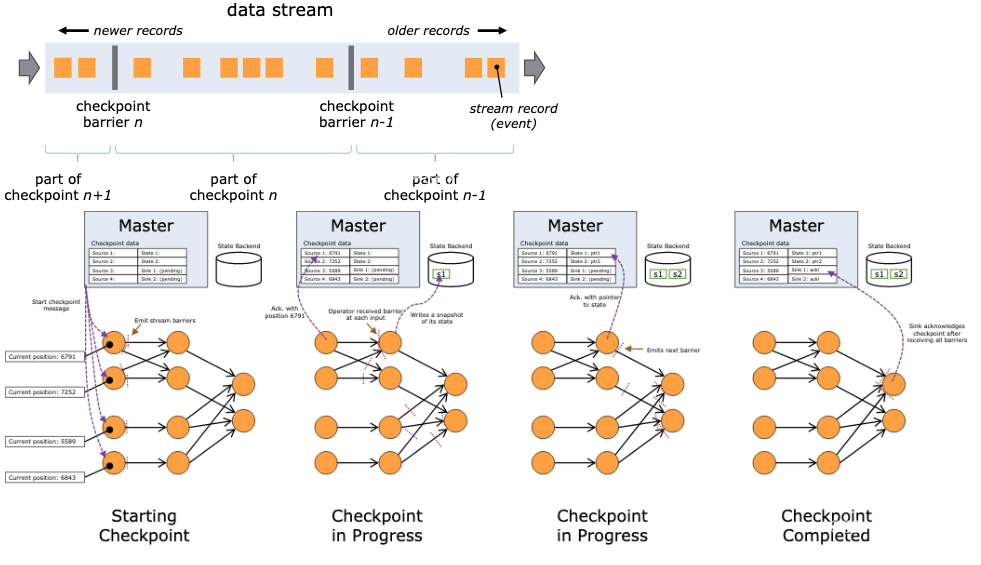
——参考链接。
Apache Flink 的 CDC (Change Data Capture) 功能可以帮助实时捕获数据库的变更并将其转换为事件流。对于 Flink CDC 在全量阶段的故障恢复问题,确实有可能出现无法从 checkpoint 点恢复的情况,尤其是涉及到全量同步阶段的故障。全量同步通常是指首次运行时或者重新初始化时拉取数据库的完整数据快照。为什么全量阶段可能无法从 checkpoint 恢复?
全量阶段未包含在 checkpoint 中:CDC 的全量加载通常是一个独立于正常增量流处理过程的任务阶段。全量数据抓取可能并未集成到常规的 Flink Checkpoint 机制中,这意味着全量阶段的进度和状态可能不在常规的 checkpoint 数据里。
全量数据一次性加载:全量阶段往往一次性加载大量数据,完成后才开始记录增量变更。如果全量加载过程中出现故障,那么从 checkpoint 恢复通常意味着重新开始整个全量同步过程。
设计与实现细节:Flink CDC 库的具体实现决定了全量阶段是否支持故障恢复以及如何恢复。一些开源项目可能只实现了增量数据的故障恢复,而全量阶段的恢复策略可能需要额外的定制逻辑。
解决办法可能包括:
重新执行全量导入:如果全量阶段没有被checkpoint管理,那么在故障后,通常需要重新执行一次全量导入,直到成功完成。
优化全量导入流程:针对全量阶段,开发者可以考虑设计更健壮的重试机制,并确保每次全量加载都可以安全地暂停和恢复。
检查及调整配置:确认所使用的Flink CDC插件是否支持全量阶段的故障恢复功能,并按照官方文档或最佳实践调整相应的配置项。
对于Flink CDC 2.x系列版本而言,全量故障恢复应该能够从 checkpoint 点恢复。然而,有一些因素可能会影响这一过程的成功与否:
Checkpoint间隔: 全量备份的频率对能否成功恢复至关重要。如果备份过于频繁,则每次备份都会覆盖掉之前的备份,导致无法恢复至特定的时间点。相反,如果备份间隔太长,那么中间可能会有大量的变更未能得到保存,使得恢复变得困难甚至不可能。
Checkpoints的状态一致性: Checkpoint 状态应尽可能保持一致性和完整性。否则,即使可以从指定的 checkpoint 处开始恢复,但在后续的流处理任务中仍然有可能引入不一致性的结果。
硬件限制: 如果硬件设备存在瓶颈,比如磁盘空间不足、网络带宽受限等问题,可能会阻碍 checkpoint 的生成和加载,进而影响到全量恢复的过程。
软件配置不当: 如果 Flink CDC 的配置存在问题,比如启用了不必要的特性或是设置了不合适的安全级别,都可能导致全量恢复失败。
数据质量问题: 如果输入数据的质量不高,比如含有大量无效或缺失的信息,也会增加全量恢复的难度。
网络延迟: 如果网络延迟过高,会导致备份和恢复之间的数据不匹配,从而破坏了恢复的效果。
Flink CDC (Change Data Capture) 2.0 支持从检查点 (checkpoint) 恢复。但是,为了从检查点恢复,您需要确保在执行全量故障恢复之前已经设置了检查点。
以下是从检查点恢复的基本步骤:
全量Checkpoint与增量Checkpoint的大小一致,是否正常?
如果您在使用Flink的情况下,观察到全量Checkpoint与增量Checkpoint的大小一致,您需要:
检查增量快照是否正常配置并生效。
是否为特定情况。在特定情况下,这种现象是正常的,例如:
在数据注入前(18:29之前),作业没有处理任何数据,此时Checkpoint只包含了初始化的源(Source)状态信息。由于没有其他状态数据,此时的Checkpoint实际上是一个全量Checkpoint。
在18:29时注入了100万条数据。假设数据在接下来的Checkpoint间隔时间(3分钟)内被完全处理,并且期间没有其他数据注入,此时发生的第一个增量Checkpoint将会包含这100万条数据产生的所有状态信息。
在这种情况下,全量Checkpoint和增量Checkpoint的大小一致是符合预期的。因为第一个增量Checkpoint需要包含全量数据状态,以确保能够从该点恢复整个状态,导致它实际上也是一个全量Checkpoint。
增量Checkpoint通常是从第二个Checkpoint开始体现出来的,在数据稳定输入且没有大规模的状态变更时,后续的增量Checkpoint应该显示出大小上的差异,表明系统正常地只对状态的增量部分进行快照。如果仍然一致,则需要进一步审查系统状态和行为,确认是否存在问题。
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。