
对于Flink CDC,从库全量数据读取时,scan.startup.mode这个参数该用哪个,我现在用“initial”,但发现并没有全量读取?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
scan.startup.mode参数的initial模式应当会执行全量数据扫描,然后跟上Binlog的实时变化。如果未按预期全量读取,可能是其他配置或使用情况的问题。请确保数据库配置正确,server-id是唯一的,并且scan.incremental.snapshot.enabled是true以开启增量快照。如果需要,可以尝试earliest-offset模式,但这要求从最早的Binlog开始,且在此期间表结构没有变化。如有必要,检查数据库的Binlog设置和Flink作业配置。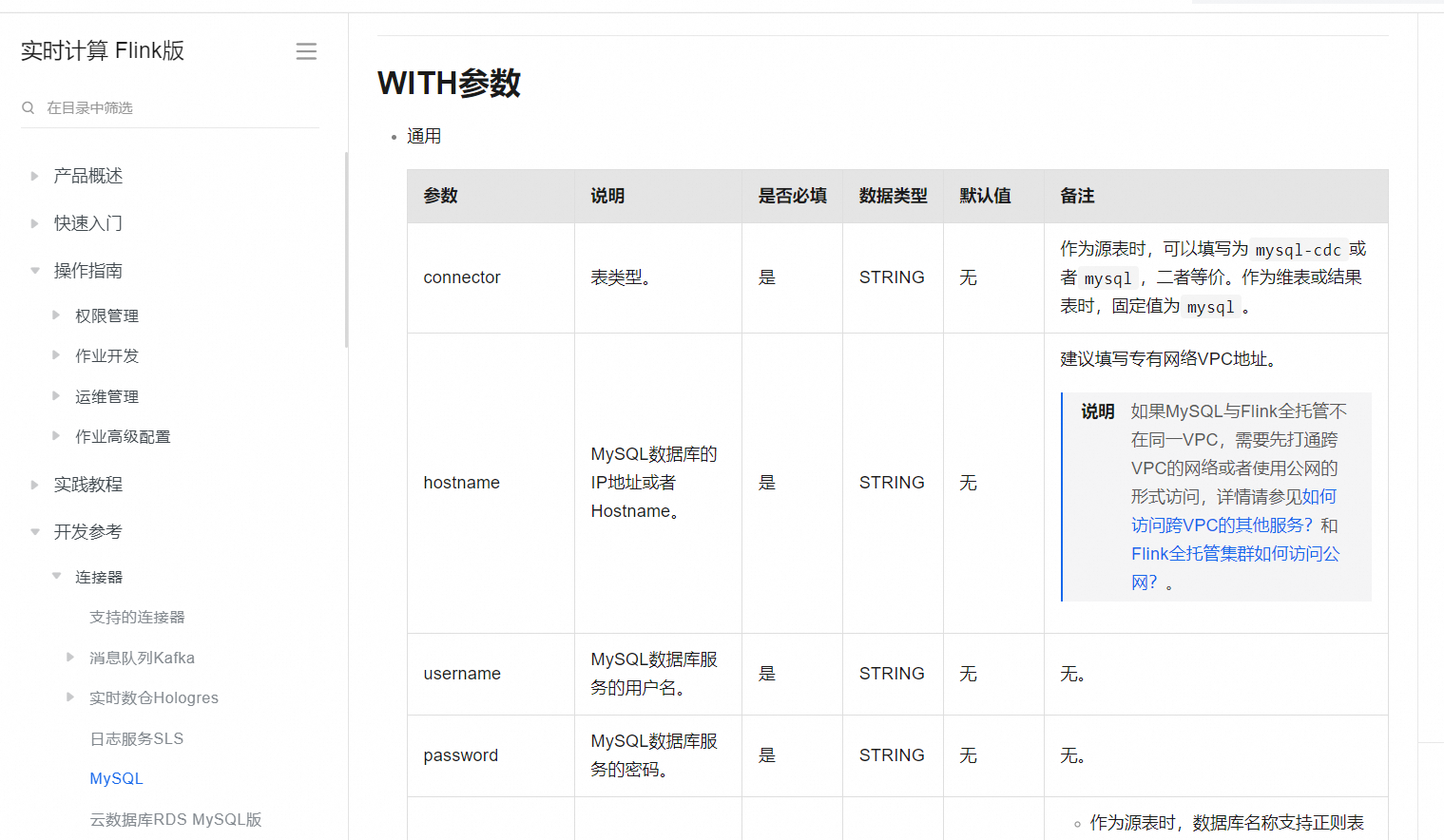
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。

