
在文字识别OCR中,试卷识别切题,有时候文字识别出来了 但是位置信息都错了,返回来坐标能全是0的。 "prism_wordsInfo": [{
"pos": [{
"x": 0,
"y": 0
}, {
"x": 0,
"y": 0
}, {
"x": 0,
"y": 0
}, {
"x": 0,
"y": 0
}],
"word": ".(每季16526135)
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
试卷切题
读光试卷切题可支持各学科的教辅试卷的结构化电子录入,将试卷中的题目进行自动化切分和结构化打标,并进行对应题目、题干、选项、答案等内容的结构化输出,能够大大释放手工录题成本,在教辅数字化、试卷批改有广泛应用。
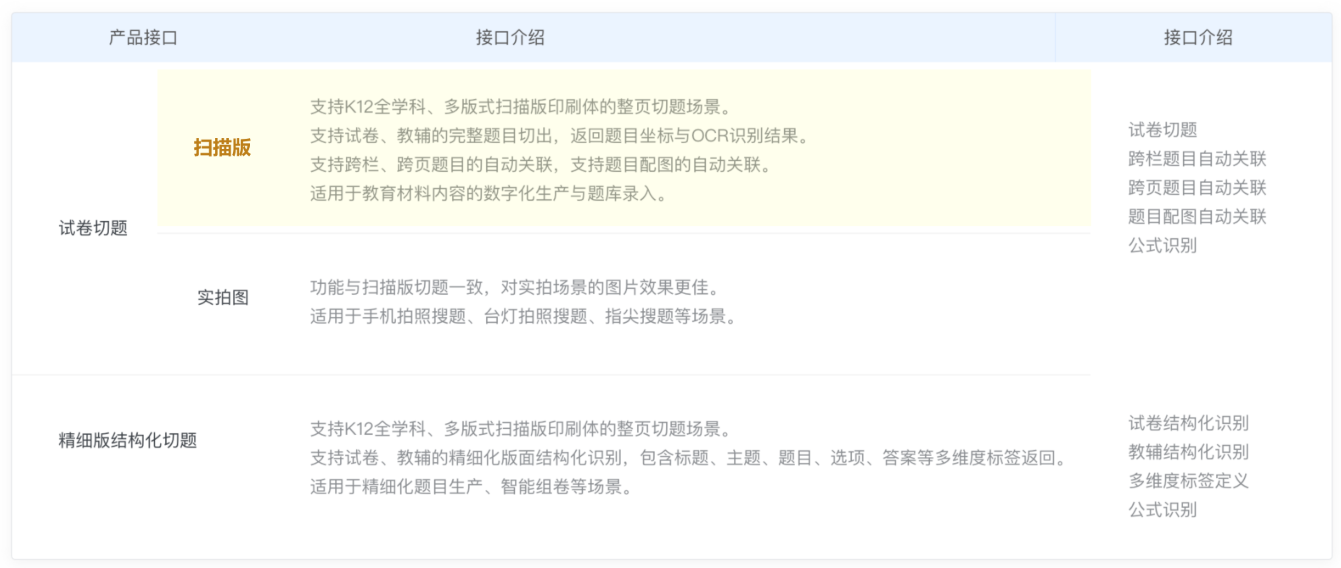
口算判题
读光口算判题可以识别小学数学口算题目并给出题目判断结果。可支持整数的加减乘除四则运算、整数的混合运算、大小比较、最大数最小数等。

整页试卷识别
整页试卷识别是教育的基础OCR识别能力。支持K12全学科扫描场景的整页内容文字识别。接口支持印刷体文本及公式的OCR识别和坐标返回,此外,接口还可对题目中的配图位置进行检测并返回坐标位置。适用于对练习册、教辅、教材等内容进行整页识别与题目检索。
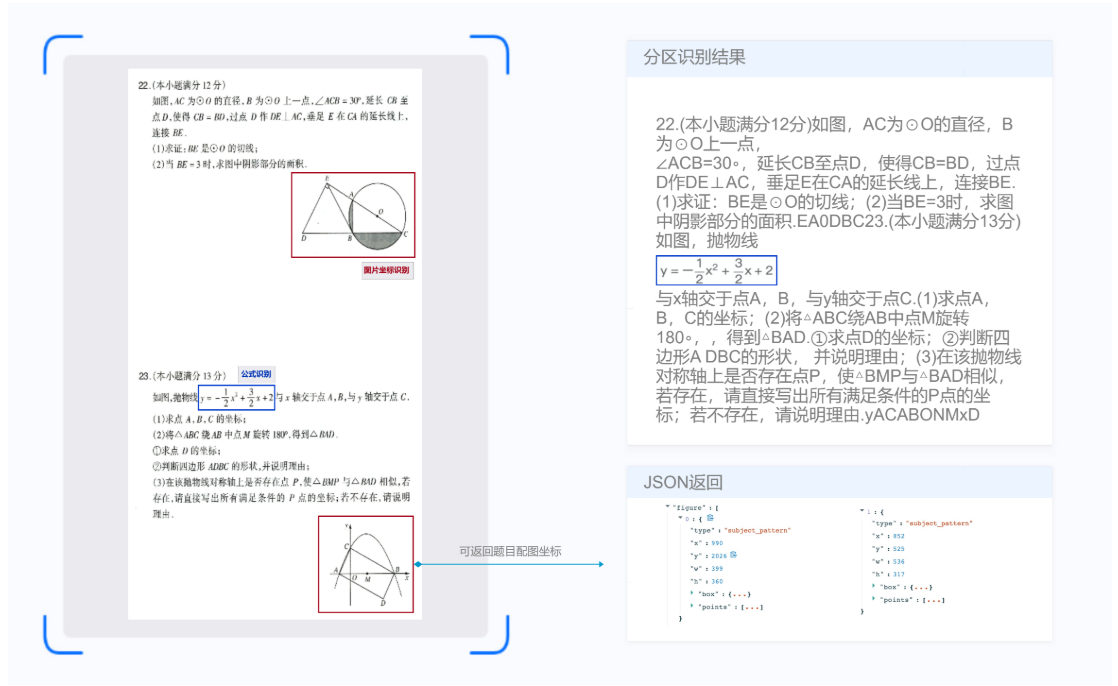
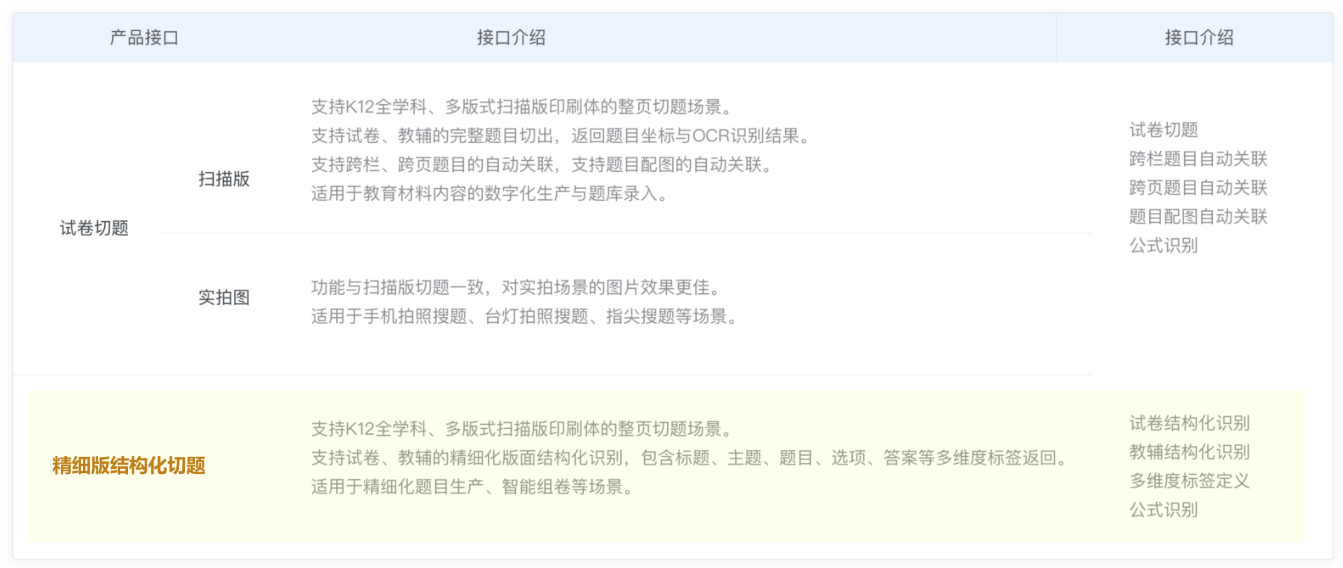
精细版结构化识别
试卷切题识别可将整页练习册、试卷或教辅中的题目进行自动切题,并识别出其中的文字内容和坐标位置。该产品按扫描版、实拍版、精细版划分,以适应不同的场景。
楼主你好,在这种情况下,可能是因为图片中文字的位置信息没有正确识别出来,导致返回的坐标都是0。这种情况下,建议对图片进行一些预处理,如图像增强、去除噪声等,以提高识别准确率和位置信息的精度。同时,也可以尝试更换OCR的识别模型或参数,以获得更好的识别结果。

在文字识别OCR中,有时候会出现文字被正确识别但位置信息错误的情况。这可能是由于以下原因导致的: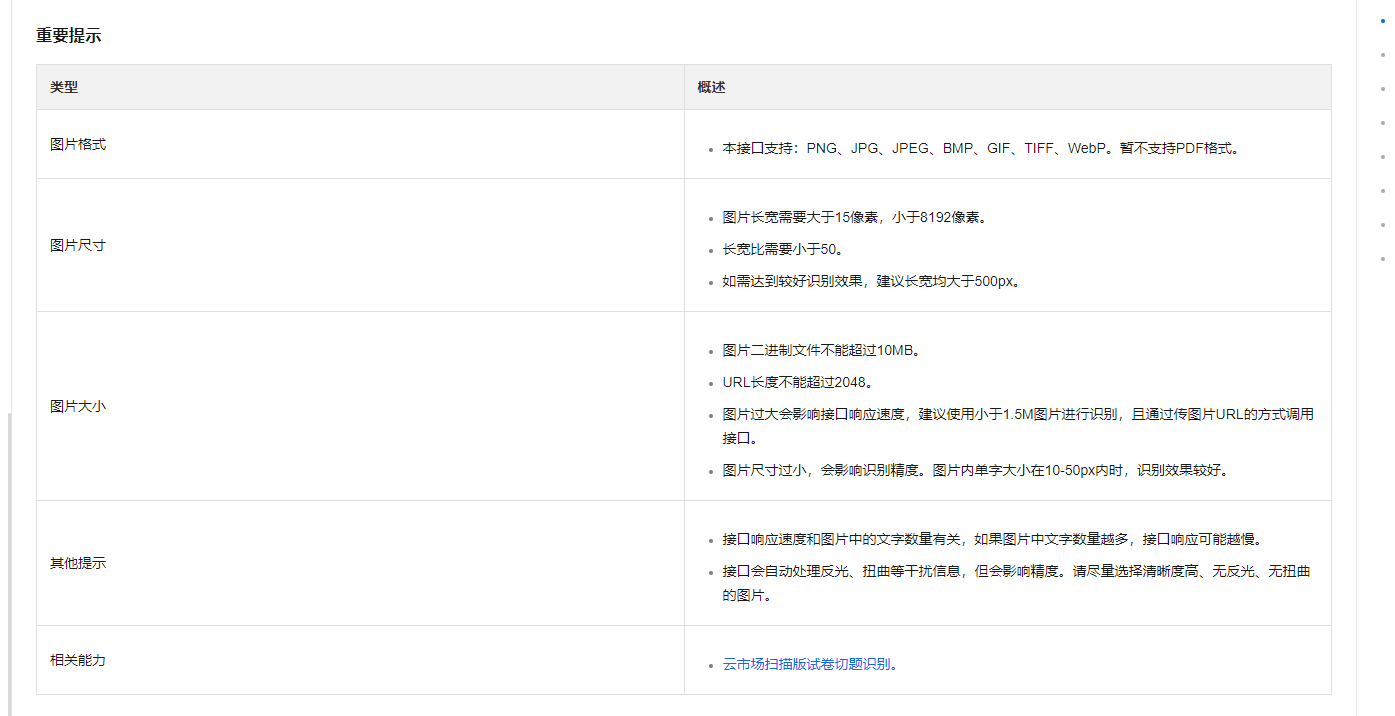
图像质量问题:如果试卷图像的质量较低,例如模糊、光照不均或者倾斜等问题,可能会导致OCR算法无法准确识别文字的位置。建议优化图像质量,确保图像清晰度和对比度,以提高文字检测和定位的准确性。
OCR模型限制:OCR模型在处理复杂的场景时可能存在局限性。例如,特殊的字体、手写字、镶嵌在表格或图形中的文本等,可能会导致位置信息错误。尽管OCR技术已经取得了很大进展,但对于一些复杂场景仍有挑战。你可以尝试使用更先进的OCR模型或进行针对特定场景的定制训练,以改善识别结果。
算法参数调整:OCR算法中的参数设置可能会影响文字位置的准确性。你可以尝试调整相关参数,如文字检测的阈值、连通区域的最小面积等,以达到更好的位置识别结果。
后处理策略:有时OCR识别结果需要经过后处理步骤,如文本校正、文字排序等,以纠正位置错误。你可以尝试应用一些图像处理和文本处理的技术来改进位置信息。
如果所有返回的坐标都是0,可能是由于某种问题在OCR流程中导致了识别失败。建议检查代码实现是否正确,并确保输入图像格式和参数设置正确。


