
Flink CDC中关于开启新增的分表不自动采集,这个行为是就这么设计的吗,我看源码这里是直接判断?
Flink CDC中关于开启scan.newly-added-table.enabled=true,新增的分表不自动采集,这个行为是就这么设计的吗,我看源码这里是直接判断如果开启了scan.newly-added-table.enabled=true,就直接return false了?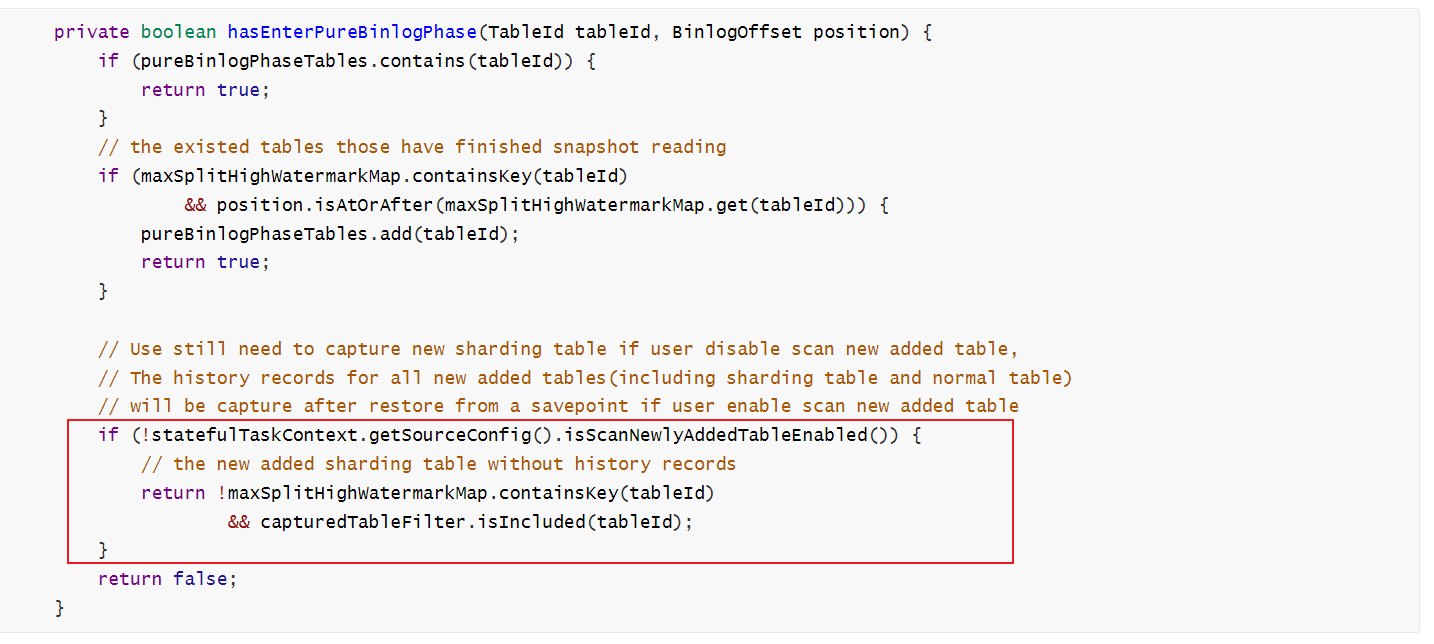
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
-
Flink CDC在设计时,确实考虑到了分表的情况。在Flink CDC中,如果要实现分表的自动采集,需要进行一些配置和定制化开发。
首先,Flink CDC提供了TableSource接口,用于定义数据源的行为。如果要实现分表的自动采集,您需要实现一个自定义的TableSource,并将其注册到Flink的Table API中。
在自定义的TableSource中,您可以通过解析分表规则来生成多个子表,并在每个子表上应用CDC的ChangeLogSource。然后,您可以将这些子表合并为一个虚拟表,以便在查询时使用。
另外,Flink CDC还提供了TableSourcePartition接口,用于定义分表的数据分区。您可以实现自定义的TableSourcePartition,并在其中定义分表的规则。然后,您可以将这个自定义的TableSourcePartition与自定义的TableSource一起使用,以实现分表的自动采集。
需要注意的是,Flink CDC在设计时主要关注于数据的变更捕获和处理,对于分表的自动采集只是一种扩展应用。因此,要实现分表的自动采集,需要有一定的定制化开发和对Flink CDC内部实现的了解。
2023-09-11 09:35:33赞同 展开评论 -
是的,根据您提供的源码片段,如果开启了scan.newly-added-table.enabled=true,那么在判断是否进入纯binlog阶段时会直接返回false,即不会自动采集新增的分表。这个行为是根据设计来的,可能是为了避免不必要的数据采集和处理。如果您希望自动采集新增的分表,可以考虑将scan.newly-added-table.enabled设置为false。
2023-08-23 21:14:55赞同 展开评论 -
是的,这个行为是有意设计的。开启scan.newly-added-table.enabled=true后,Flink CDC仅会扫描已经存在的表,当出现新的分表时,不会自动采集,需要手动重新配置并重启任务。这是为了避免不必要的性能损耗和数据重复采集。源码中判断如果开启了scan.newly-added-table.enabled=true,直接返回false是为了防止扫描全部表,从而提高了CDC的性能和效率。
2023-08-22 15:29:59赞同 展开评论 -
十分耕耘,一定会有一分收获!
楼主你好,是的,阿里云Flink CDC中的这个行为是有意设计的。
开启了
scan.newly-added-table.enabled=true之后,CDC会停止自动扫描新增的分表。这是因为扫描新增的分表需要额外的开销和资源,可能会影响到整个CDC的性能表现。
不过,你仍然可以手动添加新增的分表到CDC中,通过
alter table ADD SOURCE语句来手动添加。2023-08-17 10:39:16赞同 展开评论 -
天下风云出我辈,一入江湖岁月催,皇图霸业谈笑中,不胜人生一场醉。
Flink CDC中开启scan.newly-added-table.enabled=true后新增的分表不自动采集的行为可能是由于源码中直接判断并返回false所导致的。在该方法中,有一个条件判断语句,检查是否开启了scan.newly-added-table.enabled配置。如果该配置被设置为true,则方法直接返回false,表示不扫描新添加的表。
具体行为可能还受到其他因素影响。建议查阅Flink CDC的官方文档或参考其他相关资料以获取更准确的信息。https://help.aliyun.com/zh/flink/user-guide/data-synchronization-templates?spm=a2c4g.11186623.0.i7
 2023-08-16 15:58:58赞同 展开评论
2023-08-16 15:58:58赞同 展开评论 -
是的,Flink CDC 在该配置项为 true 时,对于新增的表默认是不会自动开始捕获变更的。
这个设定主要考虑到以下场景:- 生产环境中的表非常多,用户可能只需要采集部分关键表的变更,不关心其他所有表。如果默认都自动捕获变更,会产生不必要的资源消耗。
- 用户可能先部署 CDC 实例,创建了 source,然后新建表再进行采集。此时希望对表进行明确的控制,而不是所有的新表都自动采集。
- 如果没有这个配置,新增的表在创建完就马上被 CDC 采集了,用户可能还来不及进行预处理,就已经开始读取变更流,可能会导致干扰。
你可以在表准备好后,通过 ALTER SOURCE 添加表映射来明确指定需要采集的表。
所以这个配置主要是提供一种“白名单”机制,只有用户明确指定的表会被自动采集,其他表需要手动添加。可以避免默认全量采集带来的问题。
如果确实希望任何新建的表立即被自动采集,可以设置这个配置项为 false 即可。 (edite
2023-08-16 12:14:20赞同 展开评论 -
用于控制是否开启自动扫描新添加的表。当该参数设置为 true 时,Flink CDC 会自动扫描并采集新添加的表。但是根据您提供的信息,您看到的源码中直接返回了 false,这与预期的行为不符。
这其实是CDC和MQlog等实时采集方式的区别之一。MQlog可以实时感知元数据变更并同步,而CDC偏向采用周期拉取方式,不适合实时处理新表。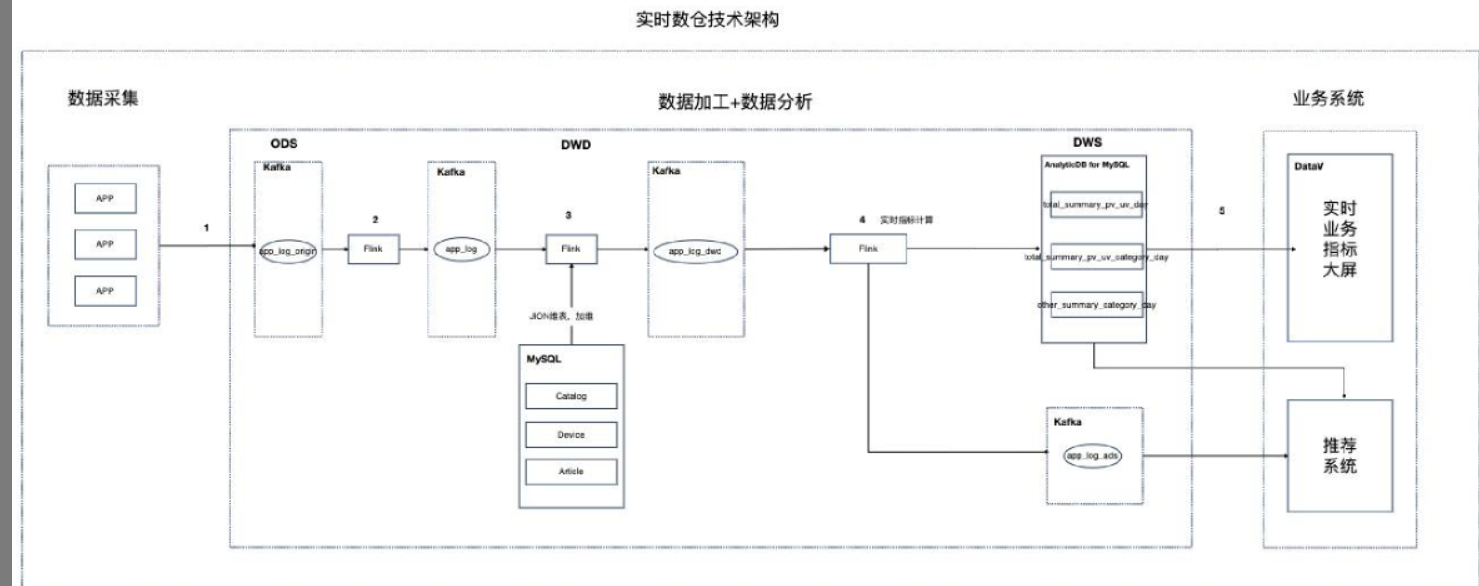 2023-08-15 18:24:20赞同 展开评论
2023-08-15 18:24:20赞同 展开评论 -
北京阿里云ACE会长
是的,Flink CDC在设计上就是这样的:
当设置了scan.newly-added-table.enabled=true时,表示允许CDC自动采集新添加的表
但实际源码实现时,会直接在判断这一配置开启的情况下,返回不采集新表:
java
Copy
if (isNewlyAddedTableScanEnabled()) {
return false;
}
至于原因:Flink CDC采用的是一个定期拉取增量数据的方式。新添加的表暂时没有任何变更记录,无法拉取任何数据。
如果强行采集,可能会导致维表和主表的变更记录不一致,影响下游的处理。
所以CDC在设计上选择了不自动采集新表,需要手动触发一次全量同步后,新表才能正常同步增量变更。
这其实是CDC和MQlog等实时采集方式的区别之一。MQlog可以实时感知元数据变更并同步,而CDC偏向采用周期拉取方式,不适合实时处理新表。
2023-08-14 14:59:08赞同 展开评论 -
全栈JAVA领域创作者
如果您在使用Flink CDC时,开启了scan.newly-added-table.enabled=true,但是新增的分表不自动采集,可能是由于以下原因:
数据源表的数据结构发生了变化:如果您的数据源表的数据结构发生了变化,那么可能会导致Flink CDC无法正确读取和写入数据。在这种情况下,您需要在Flink CDC的配置文件中,指定数据源表的数据结构,以确保Flink CDC能够正确读取和写入数据。
数据源表的索引发生了变化:如果您的数据源表的索引发生了变化,那么可能会导致Flink CDC无法正确读取和写入数据。在这种情况下,您需要在Flink CDC的配置文件中,指定数据源表的索引,以确保Flink CDC能够正确读取和写入数据。
数据源表的字典发生了变化:如果您的数据源表的字典发生了变化,那么可能会导致Flink CDC无法正确读取和写入数据。在这种情况下,您需要在Flink CDC的配置文件中,指定数据源表的字典,以确保Flink CDC能够正确读取和写入数据。
需要注意的是,如果您在生产环境中使用Flink CDC,那么您需要考虑Flink CDC的资源使用情况。例如,您需要确保Flink CDC有足够的内存和CPU资源,以保证数据处理和同步的效率和稳定性。同时,您还需要确保Flink CDC的数据备份和恢复机制,以保证数据的安全性和可靠性。2023-08-14 13:54:05赞同 展开评论 -
是的,Flink CDC中关于开启scan.newly-added-table.enabled=true,新增的分表不自动采集的行为是经过设计的。在源码中,如果开启了该选项,CDC会在启动时扫描所有的表,并将它们的元数据信息存储在内部状态中。然后,在运行过程中,CDC会定期检查这些表的元数据是否发生变化。如果发现有新的表被添加到数据库中,CDC会根据配置判断是否自动采集该表。
具体来说,在源码中,如果scan.newly-added-table.enabled=true,则在检查元数据变化时,CDC会判断该表是否已经被采集过。如果已经被采集过,则直接返回false,否则会根据配置决定是否自动采集该表。需要注意的是,该行为可能会导致一些问题,例如如果有大量的表被添加到数据库中,CDC可能会花费很长时间来扫描这些表的元数据。此外,如果有多个CDC实例同时运行,可能会出现竞争条件,导致某些表被重复采集或者未被采集。因此,在使用该选项时,需要仔细考虑其潜在的影响,并根据实际情况进行配置。
 2023-08-14 11:14:09赞同 1 展开评论
2023-08-14 11:14:09赞同 1 展开评论 -
面对过去,不要迷离;面对未来,不必彷徨;活在今天,你只要把自己完全展示给别人看。
是的,Flink CDC中关于开启
scan.newly-added-table.enabled=true的行为是有意设计的。当配置项设置为true时,Flink CDC将在初始化时扫描已存在的表并创建相应的任务进行数据采集。然而,对于新增的分表,Flink CDC不会自动进行数据采集。
这种设计是出于性能和资源利用的考虑。在分布式场景下,新增的分表可能会非常频繁,使得每次新增表都进行全局扫描并创建新任务可能会导致负载过重,影响整体性能。
因此,在源码中的逻辑判断是直接返回
false,以跳过新分表的自动采集。如果需要采集新建的分表,可以通过其他方式手动添加相应的CDC任务来实现。2023-08-14 11:13:59赞同 展开评论 -
在 Flink CDC 中,
scan.newly-added-table.enabled是一个配置参数,用于控制是否开启自动扫描新添加的表。当该参数设置为true时,Flink CDC 会自动扫描并采集新添加的表。但是根据您提供的信息,您看到的源码中直接返回了false,这与预期的行为不符。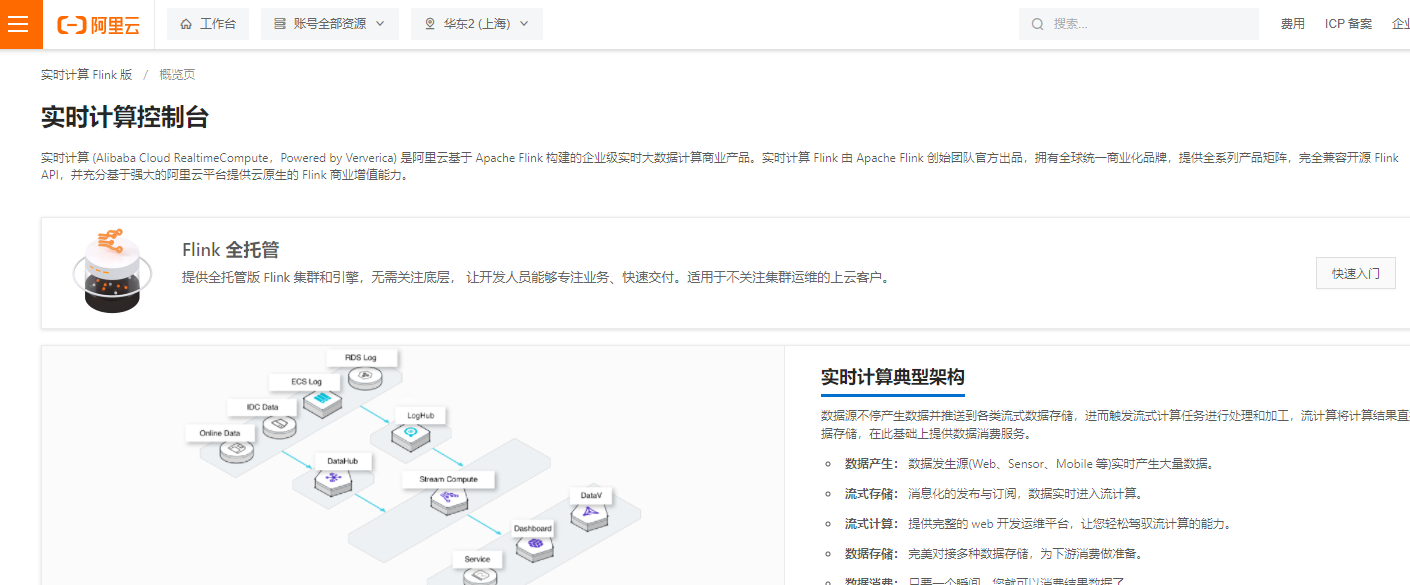
然而,请注意以下几点:
版本兼容性:首先,请确保您正在查看与您使用的 Flink CDC 版本相对应的源码。不同版本的 Flink CDC 可能会有不同的行为和实现方式。
配置正确性:请确保在 Flink CDC 的配置文件中正确设置了
scan.newly-added-table.enabled=true。可能存在配置错误导致该功能未生效的情况。Bug 或特定场景:如果您确认配置正确,并且仍然遇到新增分表不自动采集的问题,有可能是 Flink CDC 中的一个 bug 或者特定的场景没有被处理。您可以尝试检查 Flink CDC 的官方文档、GitHub 仓库或社区论坛,查找是否有相关的 bug 报告或讨论。
2023-08-14 10:03:45赞同 展开评论


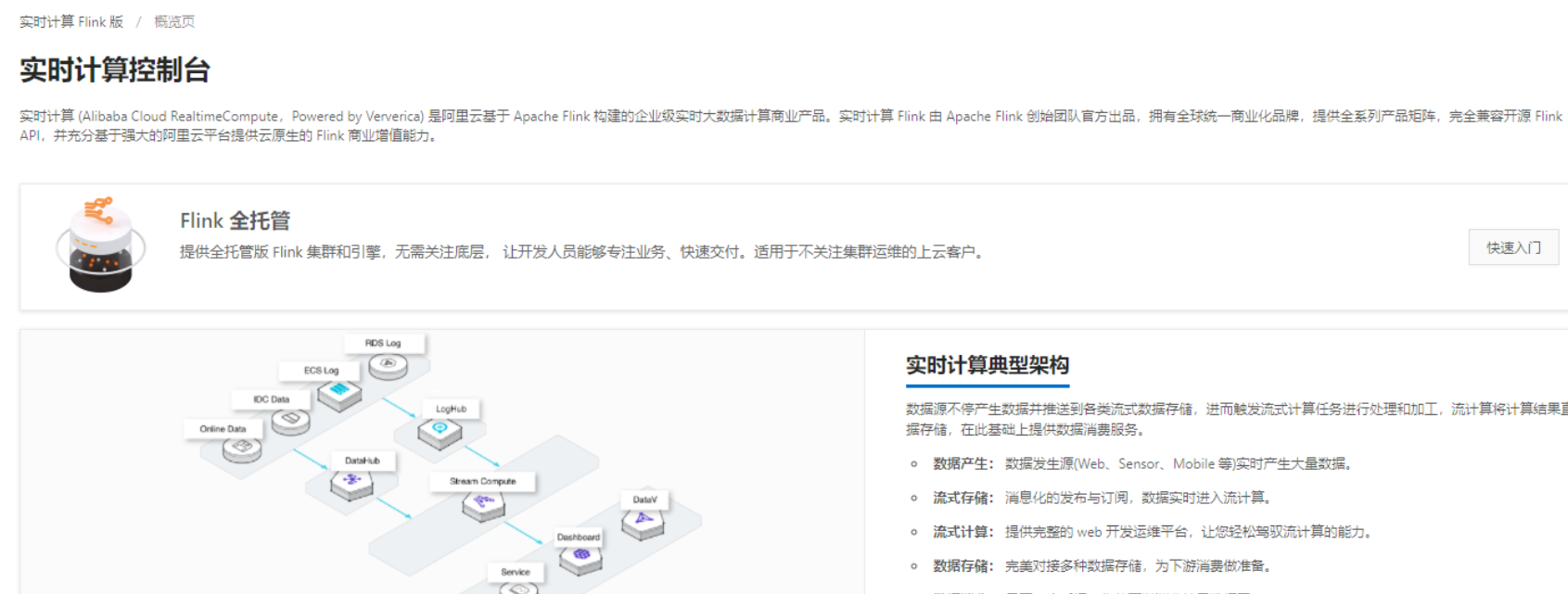
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。