
我在使用modelscope中的space-t 表格预训练模型,我想自己微调,但是对这个数据格式有一些疑问 ,阿里云OpenAPI 这里面的wvi_corenlp bertindex_knowledge header_knowledge units schema_link 分别是什么意思?该如何获取到呢?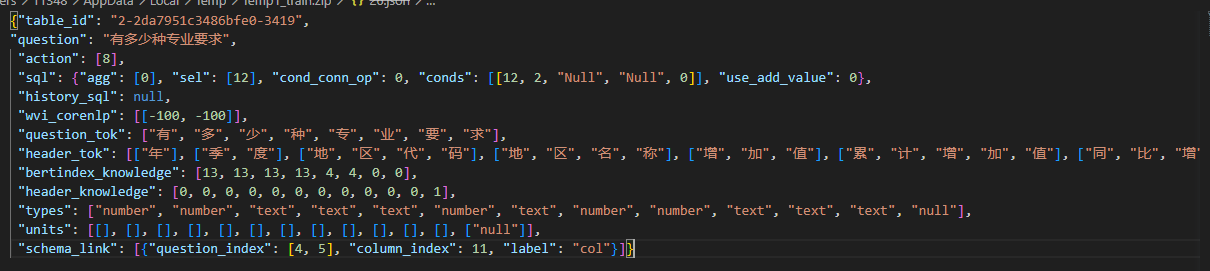
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
wvi_corenlp:表示单元格的自然语言文字(Word, Value, Instance),用于语义解析。
bert_index_knowledge:表示bert编码的实体/知识索引,用于实体和知识引用。
header_knowledge:表示列标题的知识信息,用于提取表格特征和理解。
units:表示要被特征化的表格单位,例如单元格文本、位置等。
schema_link:表示表格列标题之间的逻辑关系。
这些参数可能是针对阿里云某个具体服务的API请求参数,而不是与ModelScope中的预训练模型直接相关的参数。因此,下面我会就这些参数的含义和获取方式进行一些解释。
wvi_corenlp:该参数可能是指阿里云的自然语言处理API服务,使用该服务可以实现文本分析、情感分析、关键词提取等功能。在使用该服务时,您需要先创建一个阿里云账号,并在控制台中开通自然语言处理API服务。然后,您可以在API文档中查看具体的API请求参数和响应内容,以实现调用和使用该服务的功能。
bertindex_knowledge:该参数可能是指阿里云的BERT索引服务,使用该服务可以实现基于BERT算法的文本搜索和相似度匹配功能。在使用该服务时,您需要先创建一个阿里云账号,并在控制台中开通BERT索引服务。然后,您可以在API文档中查看具体的API请求参数和响应内容,以实现调用和使用该服务的功能。
header_knowledge:该参数可能是指阿里云的知识图谱API服务,使用该服务可以实现基于知识图谱的数据查询和关联分析功能。在使用该服务时,您需要先创建一个阿里云账号,并在控制台中开通知识图谱API服务。然后,您可以在API文档中查看具体的API请求参数和响应内容,以实现调用和使用该服务的功能。
units:该参数可能是指阿里云的机器学习服务,使用该服务可以实现基于机器学习算法的数据分析和预测功能。在使用该服务时,您需要先创建一个阿里云账号,并在控制台中开通机器学习服务。然后,您可以在API文档中查看具体的API请求参数和响应内容,以实现调用和使用该服务的功能。
schema_link:该参数可能是指阿里云的数据集成服务,使用该服务可以实现数据的连接、集成和转换等功能。在使用该服务时,您需要先创建一个阿里云账号,并在控制台中开通数据集成服务。然后,您可以在API文档中查看具体的API请求参数和响应内容,以实现调用和使用该服务的功能。
在使用 ModelScope 中的 Space-T 表格预训练模型进行微调时,以下是对数据格式中的字段的解释:
wvi_corenlp:表示表格中的单元格内容。wvi_corenlp 是一个列表,包含了每个单元格的文本内容。
bertindex_knowledge:表示表格中每个单元格的 BERT 编码。bertindex_knowledge 是一个列表,包含了每个单元格的 BERT 编码。
header_knowledge:表示表头的信息。header_knowledge 是一个列表,包含了表格的列名或属性。
units:表示表格的结构。units 是一个列表,包含了每行的单位数据,每个单位数据是一个字典,包含了单元格的位置信息和对应的单元格 ID。
schema_link:表示表格中的链接信息。schema_link 是一个字典,用于记录表格中的外部链接信息。
对于如何获取这些数据,可以按照以下方式进行:
wvi_corenlp 和 bertindex_knowledge:可以使用 NLP 工具(如 CoreNLP)对表格数据进行文本处理和编码,得到相应的结果。
header_knowledge:可以从表格的列名或属性数据中获取。
units:可以通过解析表格文件(如 Excel、CSV 等)读取表格的数据,并将数据转换为合适的格式。
schema_link:根据表格的特定要求,如有需要可手动添加链接信息。
具体如何获取这些数据取决于你的应用场景和数据来源。你可以根据自己的需求和数据处理流程,使用相应的工具和方法来提取和生成这些数据。同时,建议在处理过程中保持数据的一致性和完整性,确保与模型的输入要求相符。
wvi_corenlp表示WHERE条件中每个值对应question中的序号,如果只为-100表示没有对应到question。 bert_knowledge:与question_tok等长,每一位表示question中的token是否和table schema有linking header_knowledge:与header等长,每一位表示该header是否和question中的token是否有linking
这些参数是通过一种基于特定算法生成的知识库。具体来说,bertindex_knowledge参数是指在预训练模型中用于存储表格中每个单元格的BERT索引信息。而header_knowledge参数则是用于存储表格中每个表头的相关信息。这些信息可以用于帮助模型更好地理解表格内容,从而提高模型的准确率。
根据您提供的信息,我推测您正在使用 ModelScope 中的 space-t 表格预训练模型进行微调。以下是对于阿里云 OpenAPI 中的一些字段的解释:
wvi_corenlp:这个字段代表表格中每个单元格的自然语言表示。它通常通过将表格中的文本内容输入到 CoreNLP(一个自然语言处理工具)进行处理而得到。
bertindex_knowledge:这个字段是用于知识库索引的 BERT 表示。它可以用于在模型中引入先验知识,以提高模型在特定领域的效果。
header_knowledge:这个字段包含表头的知识表示。它可以用于帮助模型理解表格的结构和语义。
units:这个字段表示表格中每个单元格的内容。
schema_link:这个字段表示表格的列名或者语义模式。
上述信息可能需要进一步的数据准备和处理才能用于微调任务。您可以参考阿里云 OpenAPI 的相关文档来了解更多关于这些字段的详细说明和使用方法。

