
问题1:你好,想问下Dataphin如果选择hive作为数仓,每个派生指标计算完是把结果值update到汇总表上吗?因为我看好像是每个派生指标都生成一个计算SQL,这样每个指标算完都update上去效率会不会很差,还是说不是一个一个update上去的
问题2:哦同一个汇总表上的指标是在同一个SQL上一批算出来的吗?一个SQL的话,不同指标的业务限定、统计周期会不会有冲突,例如近七天的指标要用where date<7day这中条件
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
Dataphin 会为每个派生指标生成一个计算 SQL,该 SQL 中包含了该指标的计算逻辑和表达式。
在生成汇总 SQL 时,Dataphin 会将所有派生指标的计算 SQL 作为子查询嵌入到汇总 SQL 中。
最终的汇总 SQL 会将各个子查询的结果进行聚合计算,生成最终的结果值。
在Dataphin中,如果您选择Hive作为数仓,并使用派生指标计算任务,通常情况下不会直接将结果值更新到数据汇(即源数据表)。而是将计算得到的派生指标结果存储到一个新的表或视图中。
具体的流程如下:
定义派生指标:在Dataphin中,您可以定义需要计算的派生指标,包括指标计算逻辑、数据源等信息。这些派生指标的计算逻辑可以基于Hive SQL语句编写。
创建派生指标表或视图:在计算过程中,您可以选择创建一个新的表或视图来存储派生指标的计算结果。这个表或视图可以使用Hive表的方式创建,并保存计算结果。
执行派生指标计算任务:通过Dataphin的调度功能,执行派生指标计算任务。任务会根据预定义的计算逻辑,在Hive上执行相应的SQL语句,将计算结果保存到派生指标表或视图中。
查询派生指标结果:一旦计算任务完成,您可以通过查询派生指标表或视图来获取计算结果。这些结果与原始的源数据表是分开存储的,不会直接影响源数据的内容。
回答1:派生指标生成后,会挂在汇总表下面哈,调度是汇总表在周期调度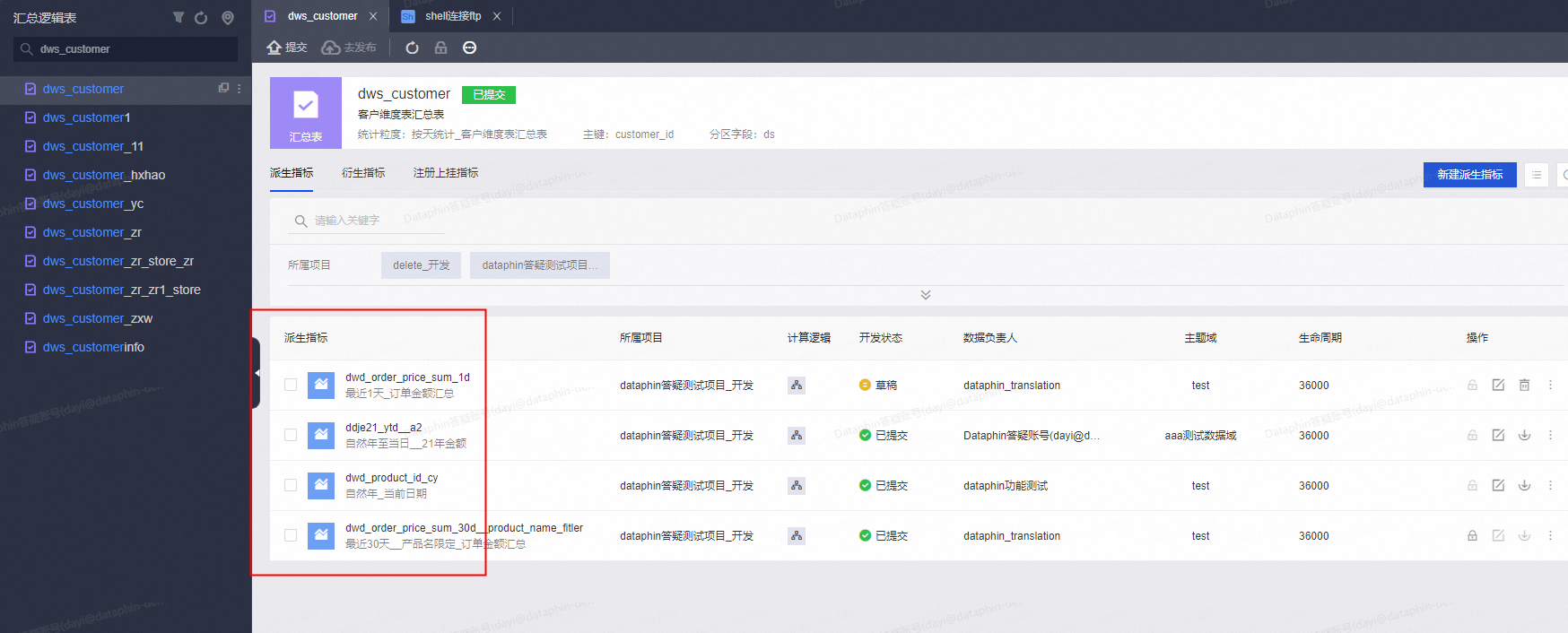
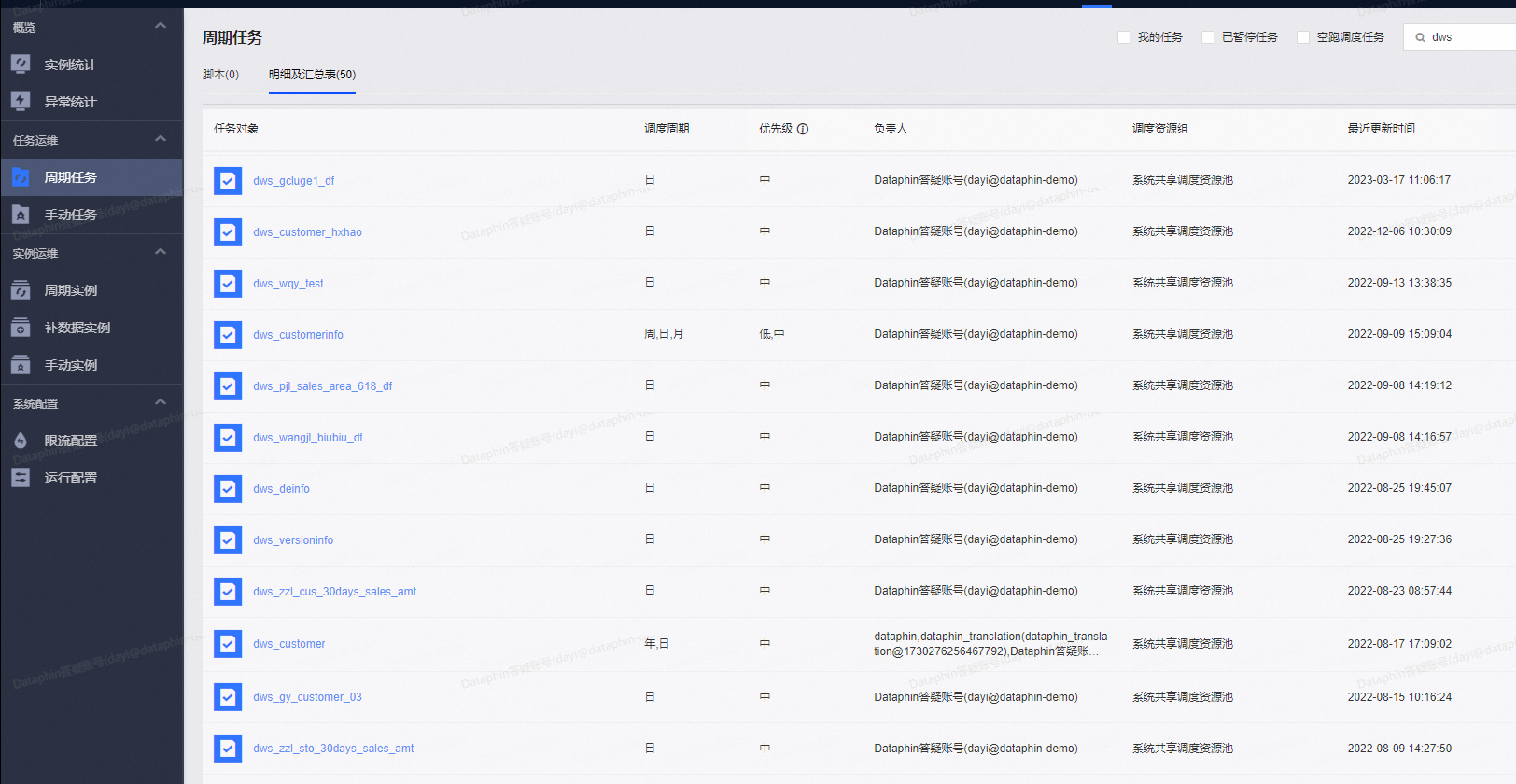
回答2:不是同一个sql,一个汇总表会有多个物化节点,每一个物化节点对应一个指标计算逻辑;像如下图: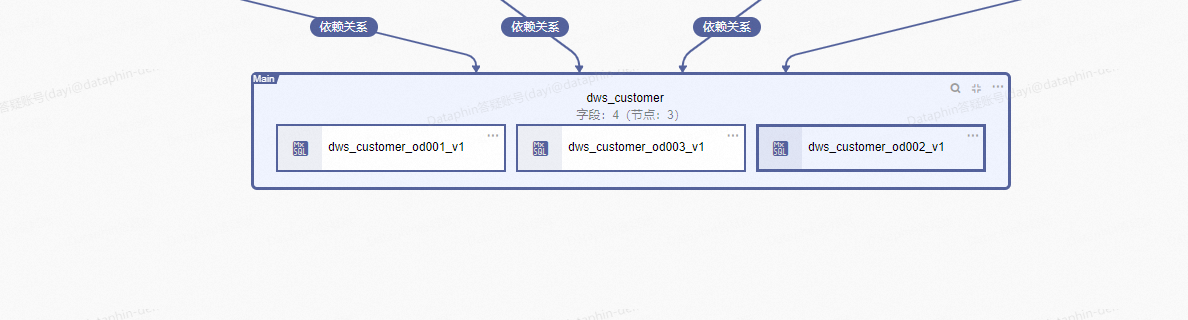
,此回答整理自钉群“Dataphin公共云答疑群”
问题1:在Dataphin中使用Hive作为数仓,派生指标的计算结果并不是通过逐个更新(update)到汇总表上的。通常情况下,Dataphin会生成一批计算SQL,这些SQL会以批处理的方式执行,并将计算结果写入到目标表中。这样可以提高计算的效率,避免逐个更新的性能问题。
具体的计算逻辑和执行方式可能会根据具体的数据仓库架构和计算引擎而有所不同。但无论是使用Hive还是其他计算引擎,Dataphin通常会优化计算过程,以提高计算效率和性能。
问题2:在同一个汇总表上的指标通常是在同一个SQL上一批算出来的。Dataphin会将相关的指标计算逻辑整合到一个SQL中,以便在一次查询中同时计算多个指标。这样可以减少查询的开销,并提高计算效率。
不同指标的业务限定和统计周期可以通过SQL中的条件语句(例如WHERE子句)来进行区分。例如,可以使用不同的条件来筛选近七天的数据和其他时间段的数据。通过合理设计SQL语句,可以确保不同指标的业务限定和统计周期不会产生冲突,并正确计算出相应的结果。


