
Flink CDC中像这种情况,要怎么样才能保证数据的原始有序性?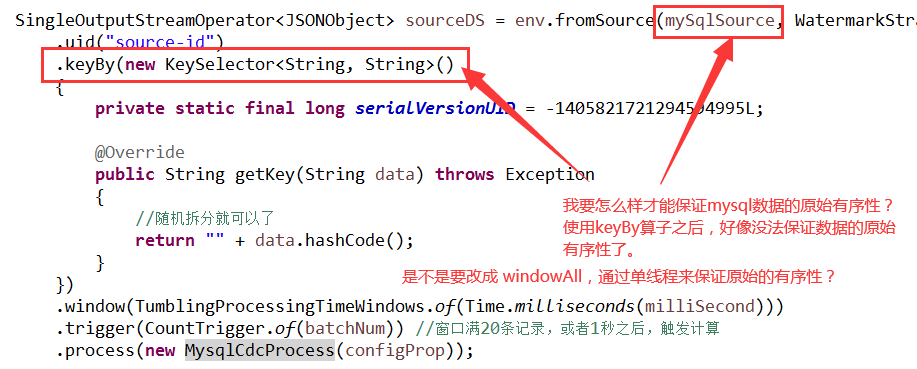 是不是不能使用keyBy算子?通过windowAll算子的单线程来保证原始的有序性?
是不是不能使用keyBy算子?通过windowAll算子的单线程来保证原始的有序性?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
keyBy 使得相同key 的数据会进入同一个并行子任务,每一个子任务可以处理多个不同的key。这样使数据保证了有序性,并且每个子任务直接相互隔离。
我们确保了相同键的数据在逻辑上是有序的。即使在高度并行的环境中,具有相同键的所有数据都会按照其到达的顺序进行处理。
当Flink执行keyBy操作时,它使用键(这里是userId)的散列值来确定哪个子任务应该处理该事件。例如,它可能决定将userId=1的所有事件发送给任务A,而userId=2和userId=3的事件发送给任务B。
关键点是,同一个userId的所有事件都被路由到同一个任务。每个Flink任务在单个线程内运行,则可以保证顺序性。
——参考链接。
在 Apache Flink 中,可以通过多种方式来保持数据的顺序性和原序性。在这种情况下,关键是要选择合适的方式来维护原有的顺序关系。在您提供的示例代码片段上,有几个点值得探讨一下:
避免 Keyed Operations
正如您所指出的那样,Keyed operations(如 keyBy)会导致分区内的乱序。这是因为不同的键会被分配到不同的 partition,而各个 partition 在各自的 worker 中独立处理数据。为了避免这个问题,请不要使用 keyBy 函数。
使用 Windowing and Process Function
窗口操作允许您基于特定的时间间隔对数据进行分组和处理。在此基础上,配合 process function,可以在一定程度上控制 window 中数据的处理过程。process function 经常用于替代传统的 mapWithState 或 reduceFunction ,并且更适合于定制化的状态管理和复杂的逻辑运算。
单线程模式下的窗口 All
Window all 让所有的记录都属于同一个窗口,从而实现了全局排序的效果。这意味着无论何时触发窗口,都将包含所有已有的数据,而不是仅仅只有一部分数据。这种模式下,只要保证窗口触发器不会早于数据到来,就能得到全局有序的结果。此外,还可以利用 watermark 来跟踪 event-time 的进度,进一步确保数据的顺序性。Watermark 是一种技术手段,用于追踪 event time 的进展,有助于消除延迟带来的影响。
建议采取的做法:
删除 keyBy 关联的操作;
使用TumblingProcessingTimeWindows 实现固定长度的滑动窗口;
设置 CountTrigger 触发窗口计算;
自定义 ProcessFunction,重载 processElement 方法并在其中完成具体的业务逻辑。
在大规模分布式系统中保障严格的顺序性往往代价较高,而且有时也不太现实。因此,在评估性能要求的同时,也需要权衡可用性和成本等因素。
在Apache Flink 中,窗口函数(Window Functions)是一种强大的特性,允许用户对事件序列进行分组并在特定的时间间隔内收集这些事件。然而,正如你在代码片段中提到的那样,窗口函数并不能完全保留原始事件顺序。这是因为窗口函数会对事件进行重新排序,以便满足窗口边界条件的要求。
如果你想保持原始事件的顺序,最好的做法可能是使用 TumblingProcessingTimeWindows.of(Time.milliseconds(milliSecond)) 替换为 SessionWindow.withStartEndOfEachBatch() ,后者不会改变事件之间的相对顺序,而是仅关注同一批次内部的数据。
你还可以考虑使用 CountTrigger.of(batchNum) 替换成 EventTimeWATERMARK(Materialized.as(WatermarkEstimator.WatermarkEstimate.named("event-time-watermark"))).processOnTimer(Timings.of(Time.seconds(1))),这种方式可以让系统每隔一秒就检测一次水印的变化情况,进而决定何时应该计算下一个批处理结果。
如果你确实想使用 KeySelector 来提取键值,那么请注意,Flink 并没有内置的方法来保存原始事件顺序。这意味着即使你使用 windowAll 方法,也无法恢复原始事件顺序。不过,你可以考虑自定义一个逻辑来跟踪事件之间关系的元数据存储方案,但这并不是一件简单的事情,而且可能会增加复杂度和开销。
虽然 Flink 提供了一些方便的功能来处理窗口化数据,但在某些场景下,你可能需要自己设计一些策略来维护原始事件顺序。
在 Flink CDC 中,要保证数据的原始有序性,您可以通过以下方式实现:
DataStream windowedData = sourceDS.keyBy(/ keySelector /)
.timeWindow(Time.seconds(5))
.apply(new WindowFunction() {
@Override
public void apply(String key, TimeWindow window, Iterable input, Collector out) {
// 在这里处理数据,原始数据会按照时间窗口有序排列
}
});
CopyCopy
sourceDS.keyBy(/ keySelector /)
.assignTimestampsAndWatermarks(new Assigner() {
@Override
public Long extractTimestamp(String element, long recordTimestamp) {
// 返回事件时间戳
return eventTimeStamp;
}
@Override
public Watermark extractWatermark(String element, long recordTimestamp, Watermark previousWatermark) {
// 返回 Watermark,用于处理事件时间
return watermark;
}
})
.window(Time.seconds(5))
.apply(new WindowFunction() {
@Override
public void apply(String key, TimeWindow window, Iterable input, Collector out) {
// 在这里处理数据,原始数据会按照事件时间窗口有序排列
}
});
CopyCopy
请注意,这些方法可以结合使用以实现数据的原始有序性。具体实现方式取决于您的业务需求和数据特点。
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。


