
麻烦问下Flink有遇到checkpoint卡在某个算子不往下走的问题吗?这个卡到最后就超时了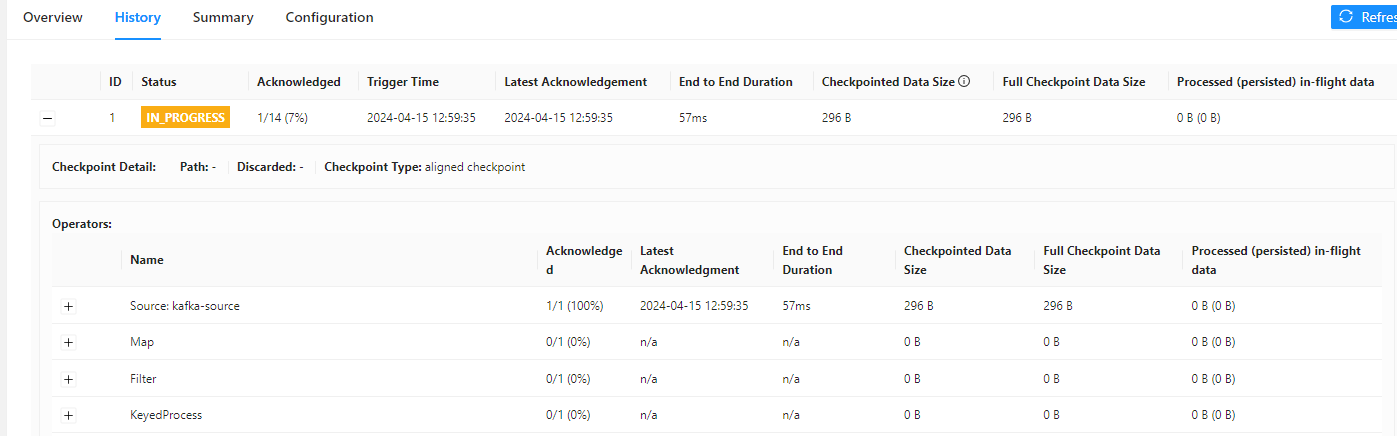
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
在Flink作业中,如果遇到Checkpoint卡在某个算子不往下走的问题,并最终导致超时,通常是由于同步阶段或异步阶段的性能瓶颈引起的。以下是问题的详细分析和解决方法:
根据知识库资料,Flink的Checkpoint分为两个主要阶段: - 同步阶段:Barrier在算子间传递并对齐,延迟与数据记录的延迟成正比。 - 异步阶段:算子将本地状态数据上传至远程持久化存储,上传时间与状态数据大小成正比。
同步阶段瓶颈:
Sync Duration或Alignment Duration较长,说明Barrier对齐时间过长,可能是由于反压、网络延迟或数据倾斜导致的。异步阶段瓶颈:
Async Duration较长且Checkpointed Data Size较大,说明状态数据量过大,上传到远程存储的时间过长。其他潜在问题:
为了定位问题,可以按照以下步骤进行诊断:
在运维中心 > 作业运维页面的Checkpoints历史中,观察不同级别的Checkpoint指标: - Sync Duration 和 Alignment Duration:如果这两个值较长,说明瓶颈在同步阶段。 - Async Duration 和 Checkpointed Data Size:如果这两个值较大,说明瓶颈在异步阶段。
在监控告警页签中查看以下指标: - lastCheckpointDuration:最近一个Checkpoint的持续时间。 - lastCheckpointSize:最近一个Checkpoint的大小。
通过以下方式排查具体算子的异常: - Job Manager异常:查看是否有Failover或其他异常信息。 - 慢Checkpoint对应的Task Managers日志:定位慢Checkpoint关联的TM日志,分析具体原因。
根据问题的具体原因,可以采取以下调优措施:
启用Unaligned Checkpoint:
优化反压问题:
调整Checkpoint间隔:
execution.checkpointing.interval,减少Checkpoint频率,降低同步阶段的压力。增加并发资源:
使用原生快照:
优化状态管理:
state.backend.latency-track.keyed-state-enabled,监控状态访问延迟,优化状态清理和访问性能。检查网络连通性:
调整Postgres CDC连接器参数:
execution.checkpointing.tolerable-failed-checkpoints。通过上述诊断和调优方法,可以有效解决Flink作业中Checkpoint卡在某个算子的问题。建议优先从同步阶段和异步阶段的性能瓶颈入手,结合具体的日志和指标分析问题根源,并采取相应的优化措施。
实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。

