
问题一:Users/cero/Softwares/anaconda3/envs/odpsUDF/bin/python /Users/cero/Softwares/anaconda3/envs/odpsUDF/bin/pyou -I sys.stdin udaf_waste_point.udaf_waste_point Traceback (most recent call last): File "/Users/cero/Softwares/anaconda3/envs/odpsUDF/bin/pyou", line 51, in main() File "/Users/cero/Softwares/anaconda3/envs/odpsUDF/bin/pyou", line 46, in main udf_runner = runners.get_default_runner(clz, delim, null_indicator, stdin) File "/Users/cero/Softwares/anaconda3/envs/odpsUDF/lib/python3.7/site-packages/odps/udf/tools/runners.py", line 35, in get_default_runner in_types, out_types = parse_proto(proto) File "/Users/cero/Softwares/anaconda3/envs/odpsUDF/lib/python3.7/site-packages/odps/udf/tools/runners.py", line 93, in parse_proto return _get_in_types(tokens[0].strip()), _get_types(tokens[1].strip()) File "/Users/cero/Softwares/anaconda3/envs/odpsUDF/lib/python3.7/site-packages/odps/udf/tools/runners.py", line 68, in _get_types raise Exception('type not in '+ ','.join(_allowed_data_types)) Exception: type not in bigint,string,datetime,double,boolean
Process finished with exit code 1
MaxCompute中这个报错怎么解决呢?
问题二: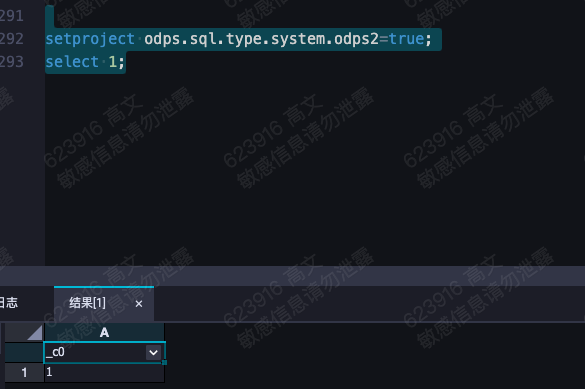 执行这个语句绑定的MaxCompute引擎和你本地测试udf绑定的引擎是一样的,本地测试还是报相同错误。# coding:utf-8 from odps.udf import annotate from odps.udf import BaseUDAF import numpy as np import pandas as pd
执行这个语句绑定的MaxCompute引擎和你本地测试udf绑定的引擎是一样的,本地测试还是报相同错误。# coding:utf-8 from odps.udf import annotate from odps.udf import BaseUDAF import numpy as np import pandas as pd
@annotate('*->array') class udaf_waste_point(BaseUDAF): def new_buffer(self): """ 初始化 [第一列未预约点位数, 第二列未预约点位数...] :return: """ return []
def iterate(self, buffer, *args):
"""
每行中未预约点位标记为1,然后按列求和
:param buffer:
:param args:原始一行点位
:return:
"""
# 初始buffer为空列表,将args中的未预约点位标记为1,直接装入buffer
if len(buffer) == 0:
for i in range(len(args)):
buffer.append(1 if i == 'cano' else 0)
pass
# buffer非空,将args中的未预约点位标记为1,遍历buffer求和
for i in range(len(args)):
buffer[i] += 1 if args[i] == 'cano' else 0
def merge(self, buffer, pbuffer):
# 初始buffer为空列表,将pbuffer直接装入buffer
if len(buffer) == 0:
buffer.extend(pbuffer)
pass
# buffer非空,将pbuffer,遍历buffer求和
for i in range(len(pbuffer)):
buffer[i] += pbuffer[i]
def terminate(self, buffer):
waste_point_df = self.to_waste_point_df(buffer)
changed_df = self.change_df(waste_point_df)
formated_df = self.format_df(changed_df)
waste_point_array = formated_df.T.loc['cnt', :].to_list()
print(waste_point_array)
# return waste_point_array[0]
return waste_point_array
@staticmethod
def to_waste_point_df(buffer):
"""
list: [3, 2, 1, 0] => dataframe: [[1, 1, 1, 0],
[1, 1, 0, 0],
[1, 0, 0, 0]]
:param buffer:
:return:
"""
data = [[1 if buffer[j] > i else 0 for j in range(len(buffer))] for i in range(max(buffer))]
waste_point_df = pd.DataFrame(data=data)
return waste_point_df
@staticmethod
def change_df(waste_point_df):
"""
遍历废点表,前后状态不一致时打标
dataframe: [[1, 1, 1, 0], => dataframe:[[b1, 1],
[1, 1, 0, 0], [b1, 1],
[1, 0, 0, 0]] [b1, 1],
[a1, 0],
[b2, 1],
[b2, 1],
[a2, 0],
[a2, 0],
[b3, 1],
[a4, 0],
[a4, 0],
[a4, 0]]
:param waste_point_df:
:return:
"""
# 结果集
res = []
# 起始计数
start = 0
# 标记
zero_flag = 'a'
one_flag = 'b'
for index, row in waste_point_df.iterrows():
# 起始状态
pre_value = 0
for item in row:
if item != pre_value:
start += 1
flag = zero_flag if item == 0 else one_flag
tag = '{}{}'.format(flag, start)
res.append([tag, item])
pre_value = item
new_df = pd.DataFrame(res, columns=['tag', 'value'])
return new_df
@staticmethod
def format_df(res_df):
"""
打标后的df按废点数量格式化输出1~10废点数量
dataframe:[[b1, 1], => dataframe:[[1], [1], [1], [0], [0], [0], [0], [0], [0], [0]]
[b1, 1],
[b1, 1],
[a1, 0],
[b2, 1],
[b2, 1],
[a2, 0],
[a2, 0],
[b3, 1],
[a4, 0],
[a4, 0],
[a4, 0]]
:param res_df:
:return:
"""
df = res_df.groupby('tag').agg({'value': sum}).reset_index().groupby('value').agg(
{'tag': np.size}).reset_index()
df = df.loc[(df['value'] > 0) & (df['value'] < 10)]
data = []
# 取1~10废点数量
for i in range(10):
tmp_list = df.loc[(df['value'] == i + 1), 'tag'].to_list()
if tmp_list:
data.append([tmp_list[0]])
else:
data.append([0])
formated_df = pd.DataFrame(data=data, columns=['cnt'])
return formated_df 测试数据是一个变长一维数组 问题三:我是udaf不需要evaluate,在返回值类型bigint已经测试通过了 ,帮忙看下? select store_id
,udaf_waste_point(8_1_point, 8_2_point , 8_3_point, 9_1_point, 9_2_point , 9_3_point, 10_1_point, 10_2_point , 10_3_point, 11_1_point, 11_2_point , 11_3_point, 12_1_point, 12_2_point , 12_3_point, 13_1_point, 13_2_point , 13_3_point, 14_1_point, 14_2_point , 14_3_point, 15_1_point, 15_2_point , 15_3_point, 16_1_point, 16_2_point , 16_3_point, 17_1_point, 17_2_point , 17_3_point, 18_1_point, 18_2_point , 18_3_point, 19_1_point, 19_2_point , 19_3_point, 20_1_point, 20_2_point , 20_3_point, 21_1_point, 21_2_point , 21_3_point, 22_1_point, 22_2_point , 22_3_point)
from tbl where ds = '20230509' group by store_id ddl CREATE TABLE IF NOT EXISTS dwd_participant_store_schedule_table_di ( store_id STRING COMMENT '门店id', schedule_date STRING COMMENT '排单日期', max_index BIGINT COMMENT '最大点位数', start_appointment_time STRING COMMENT '开始预约时间', stop_appointment_time STRING COMMENT '结束预约时间', service_interval_minute BIGINT COMMENT '服务间隔-分钟', service_cnt_per_period BIGINT COMMENT '每个时间段服务数', row_no STRING COMMENT '行号', 8_1_point STRING COMMENT '8点第1个点位', 8_2_point STRING COMMENT '8点第2个点位', 8_3_point STRING COMMENT '8点第3个点位', 8_4_point STRING COMMENT '8点第4个点位', 8_5_point STRING COMMENT '8点第5个点位', 8_6_point STRING COMMENT '8点第6个点位', 9_1_point STRING COMMENT '9点第1个点位', 9_2_point STRING COMMENT '9点第2个点位', 9_3_point STRING COMMENT '9点第3个点位', 9_4_point STRING COMMENT '9点第4个点位', 9_5_point STRING COMMENT '9点第5个点位', 9_6_point STRING COMMENT '9点第6个点位', 10_1_point STRING COMMENT '10点第1个点位', 10_2_point STRING COMMENT '10点第2个点位', 10_3_point STRING COMMENT '10点第3个点位', 10_4_point STRING COMMENT '10点第4个点位', 10_5_point STRING COMMENT '10点第5个点位', 10_6_point STRING COMMENT '10点第6个点位', 11_1_point STRING COMMENT '11点第1个点位', 11_2_point STRING COMMENT '11点第2个点位', 11_3_point STRING COMMENT '11点第3个点位', 11_4_point STRING COMMENT '11点第4个点位', 11_5_point STRING COMMENT '11点第5个点位', 11_6_point STRING COMMENT '11点第6个点位', 12_1_point STRING COMMENT '12点第1个点位', 12_2_point STRING COMMENT '12点第2个点位', 12_3_point STRING COMMENT '12点第3个点位', 12_4_point STRING COMMENT '12点第4个点位', 12_5_point STRING COMMENT '12点第5个点位', 12_6_point STRING COMMENT '12点第6个点位', 13_1_point STRING COMMENT '13点第1个点位', 13_2_point STRING COMMENT '13点第2个点位', 13_3_point STRING COMMENT '13点第3个点位', 13_4_point STRING COMMENT '13点第4个点位', 13_5_point STRING COMMENT '13点第5个点位', 13_6_point STRING COMMENT '13点第6个点位', 14_1_point STRING COMMENT '14点第1个点位', 14_2_point STRING COMMENT '14点第2个点位', 14_3_point STRING COMMENT '14点第3个点位', 14_4_point STRING COMMENT '14点第4个点位', 14_5_point STRING COMMENT '14点第5个点位', 14_6_point STRING COMMENT '14点第6个点位', 15_1_point STRING COMMENT '15点第1个点位', 15_2_point STRING COMMENT '15点第2个点位', 15_3_point STRING COMMENT '15点第3个点位', 15_4_point STRING COMMENT '15点第4个点位', 15_5_point STRING COMMENT '15点第5个点位', 15_6_point STRING COMMENT '15点第6个点位', 16_1_point STRING COMMENT '16点第1个点位', 16_2_point STRING COMMENT '16点第2个点位', 16_3_point STRING COMMENT '16点第3个点位', 16_4_point STRING COMMENT '16点第4个点位', 16_5_point STRING COMMENT '16点第5个点位', 16_6_point STRING COMMENT '16点第6个点位', 17_1_point STRING COMMENT '17点第1个点位', 17_2_point STRING COMMENT '17点第2个点位', 17_3_point STRING COMMENT '17点第3个点位', 17_4_point STRING COMMENT '17点第4个点位', 17_5_point STRING COMMENT '17点第5个点位', 17_6_point STRING COMMENT '17点第6个点位', 18_1_point STRING COMMENT '18点第1个点位', 18_2_point STRING COMMENT '18点第2个点位', 18_3_point STRING COMMENT '18点第3个点位', 18_4_point STRING COMMENT '18点第4个点位', 18_5_point STRING COMMENT '18点第5个点位', 18_6_point STRING COMMENT '18点第6个点位', 19_1_point STRING COMMENT '19点第1个点位', 19_2_point STRING COMMENT '19点第2个点位', 19_3_point STRING COMMENT '19点第3个点位', 19_4_point STRING COMMENT '19点第4个点位', 19_5_point STRING COMMENT '19点第5个点位', 19_6_point STRING COMMENT '19点第6个点位', 20_1_point STRING COMMENT '20点第1个点位', 20_2_point STRING COMMENT '20点第2个点位', 20_3_point STRING COMMENT '20点第3个点位', 20_4_point STRING COMMENT '20点第4个点位', 20_5_point STRING COMMENT '20点第5个点位', 20_6_point STRING COMMENT '20点第6个点位', 21_1_point STRING COMMENT '21点第1个点位', 21_2_point STRING COMMENT '21点第2个点位', 21_3_point STRING COMMENT '21点第3个点位', 21_4_point STRING COMMENT '21点第4个点位', 21_5_point STRING COMMENT '21点第5个点位', 21_6_point STRING COMMENT '21点第6个点位', 22_1_point STRING COMMENT '22点第1个点位', 22_2_point STRING COMMENT '22点第2个点位', 22_3_point STRING COMMENT '22点第3个点位', 22_4_point STRING COMMENT '22点第4个点位', 22_5_point STRING COMMENT '22点第5个点位', 22_6_point STRING COMMENT '22点第6个点位', created_at STRING COMMENT '创建时间', updated_at STRING COMMENT '更新时间', version STRING COMMENT '版本' ) COMMENT '排单表' PARTITIONED BY ( ds STRING COMMENT '分区' );
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
针对问题一的回答:type not in bigint,string,datetime,double,boolean,看这报错像是命中了数据类型1.0的类型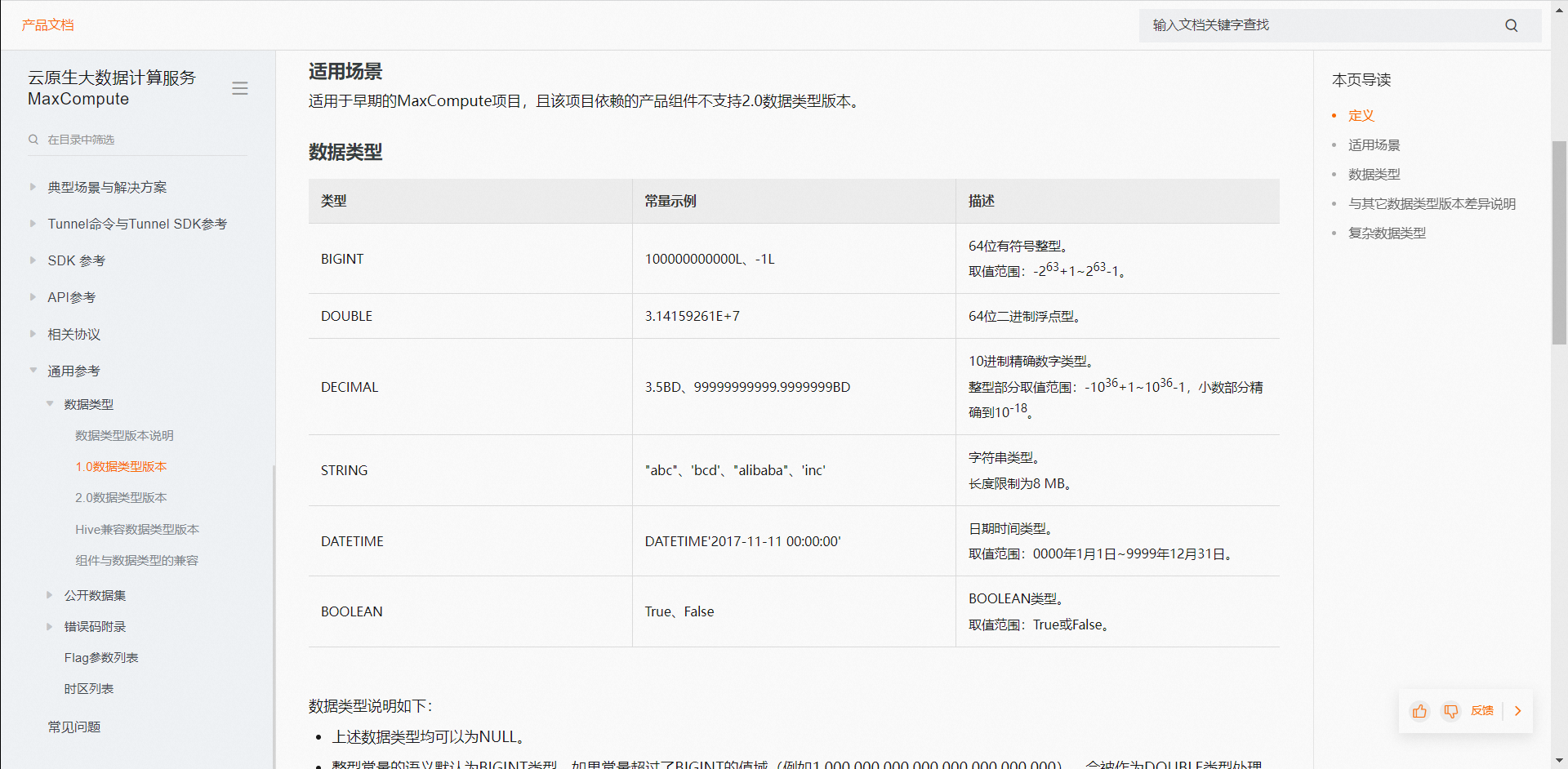 ,确定项目开了2.0开关?可以在DataWorks的SQL节点执行一下这句话setproject odps.sql.type.system.odps2=true;select 1; 针对问题二的回答:你这个udf看着没有evaluate方法呢 https://help.aliyun.com/document_detail/154431.html?spm=a2c4g.317819.0.0.a9e93475Biljqf#section-ys0-064-qyv,此回答整理自钉群“MaxCompute开发者社区2群”
,确定项目开了2.0开关?可以在DataWorks的SQL节点执行一下这句话setproject odps.sql.type.system.odps2=true;select 1; 针对问题二的回答:你这个udf看着没有evaluate方法呢 https://help.aliyun.com/document_detail/154431.html?spm=a2c4g.317819.0.0.a9e93475Biljqf#section-ys0-064-qyv,此回答整理自钉群“MaxCompute开发者社区2群”
MaxCompute(原ODPS)是一项面向分析的大数据计算服务,它以Serverless架构提供快速、全托管的在线数据仓库服务,消除传统数据平台在资源扩展性和弹性方面的限制,最小化用户运维投入,使您经济并高效的分析处理海量数据。

