
各位请教一个Flink CDC问题,我的系统现在报这个异步检查点问题,之前任务失败了重启了,就报这个问题,哪个大佬知道什么情况吗?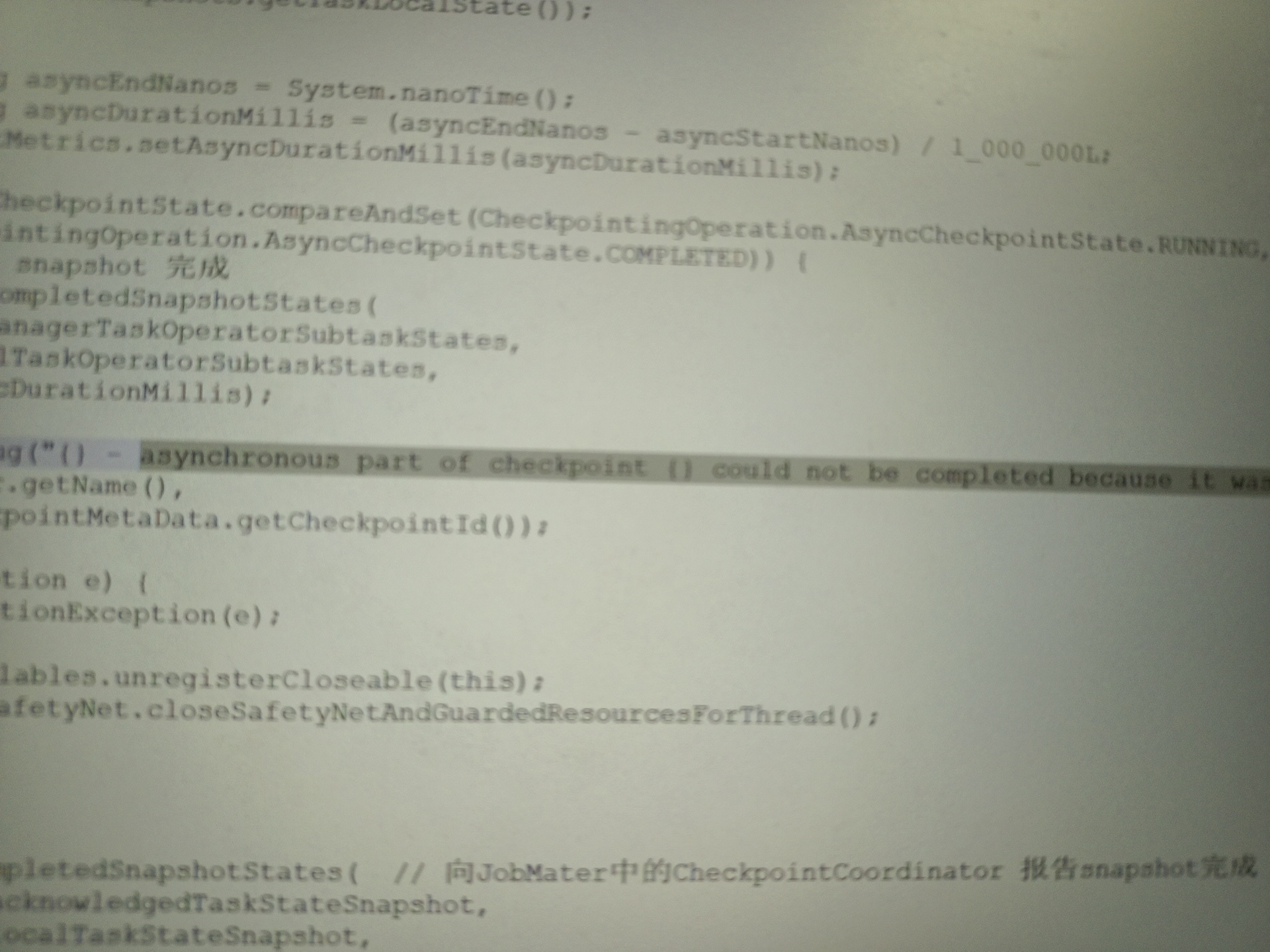
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
根据您描述的问题,Flink CDC任务在重启后报出异步检查点相关的错误。以下是可能的原因分析及解决方案:
Flink CDC任务依赖于检查点(Checkpoint)机制来保证数据一致性。如果任务失败后重启时出现异步检查点问题,可能是以下原因之一导致的: - Binlog位点丢失或过期:MySQL服务器上的Binlog文件可能已被清理,导致任务无法从上次停止的位置恢复。 - 检查点状态不一致:任务重启时,检查点的状态与当前数据库的状态不匹配,例如表结构变更或数据不一致。 - 资源不足:Flink作业运行时的资源(如内存、网络带宽)不足,导致检查点无法正常完成。 - Debezium相关配置问题:CDC连接器的Debezium参数配置不当,可能导致增量阶段的数据读取异常。
SHOW MASTER STATUS;
如果发现Binlog文件已被清理,您需要重新启动任务并选择从最新的Binlog位置开始消费。
execution.checkpointing.interval: 60000 # 检查点间隔时间(毫秒)
execution.checkpointing.mode: EXACTLY_ONCE # 检查点模式
execution.checkpointing.timeout: 10min # 检查点超时时间
state.backend.incremental: true # 启用增量检查点
如果资源有限,可以适当延长检查点间隔时间或调整超时时间。
debezium.snapshot.mode:建议设置为initial或schema_only,避免因快照模式导致的问题。debezium.inconsistent.schema.handling.mode:设置为warn,以避免因Schema不一致导致的任务失败。Replication slot "xxxx" is activeEncountered change event for table xxx.xxx whose schema isn't known to this connector通过以上步骤,您可以逐步排查并解决Flink CDC任务中异步检查点相关的问题。如果问题仍未解决,建议提供更详细的日志信息以便进一步分析。
希望以上内容对您有所帮助!您可以复制页面截图提供更多信息,我可以进一步帮您分析问题原因。
