大模型
产品
解决方案
权益
定价
云市场
伙伴
服务
了解阿里云
查看 "" 全部搜索结果
AI 助理
文档
备案
控制台
开发者社区
首页
计算机视觉
自然语言处理
语音
多模态
科学计算
魔搭社区官网
探索云世界
热门
百炼大模型
Modelscope模型即服务
弹性计算
通义灵码
云原生
数据库
云效DevOps
龙蜥操作系统
云计算
弹性计算
无影
存储
网络
倚天
云原生
容器
serverless
中间件
微服务
可观测
消息队列
数据库
关系型数据库
NoSQL数据库
数据仓库
数据管理工具
PolarDB开源
向量数据库
大数据
大数据计算
实时数仓Hologres
实时计算Flink
E-MapReduce
DataWorks
Elasticsearch
机器学习平台PAI
智能搜索推荐
数据可视化DataV
人工智能
机器学习平台PAI
视觉智能开放平台
智能语音交互
自然语言处理
多模态模型
pythonsdk
通用模型
开发与运维
云效DevOps
钉钉宜搭
镜像站
开发者社区
ModelScope模型即服务
语音
正文
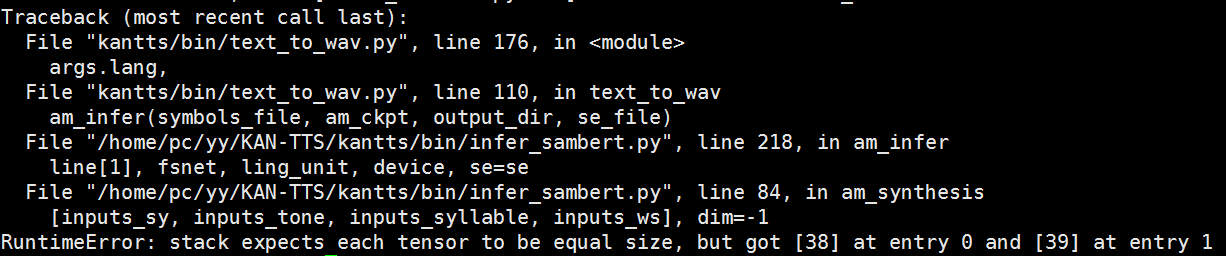
在使用text_to_wav.py进行推理时,使用--lang Sichuan 参数出现以下错误:
展开
收起
SambertHifigan个性化语音合成-中文-预训练-16k
游客yavauo4zjdmem
2023-04-06 17:33:48
453
分享
版权
1
条回答
写回答
取消
提交回答
ModelScope小助手-渡渡航
kantts相关问题,建议直接在kantts github中提issue给开发者
2023-05-10 18:01:10
赞同
展开评论
相关问答
语音
购买阿里国外的云服务器是否可以访问谷歌?
92900
50
0
this xml file does not appear to have any style in
61448
11
0
访问ECS服务器的网站提示“由于你访问的URL可能对网站造成安全威胁,您的访问被阻断”,这是什么原因?
142258
16
0
C语言数组赋值报错,打印出来的是乱码,怎么解决?
1633
1
0
#支付宝 授权提示请在支付宝客户端打开链接
24985
19
0
阿里云怎样设置二级域名以及域名解析?
66944
14
0
支付宝H5 下载的时候,提示 【请确保该下载文件来源安全,如需浏览,请长按网址复制后使用浏览器访问】
284854
11
0
基础语言百问-Python
69765
30
0
C语言中default使用注意事项是什么?
1658
1
0
搭建dnf私服需要大概啥配置的
10474
2
0
ModelScope模型即服务
语音
包括语音识别、语音合成、语音唤醒、声学设计及信号处理、声纹识别、音频事件检测等多个领域
我要提问
相关文章
基于MFCC(梅尔频率倒谱系数)和GMM(高斯混合模型)的语音识别
小结
构建智能客服:阿里云智能语音交互+函数计算的低成本方案
docker安装部署FunASR
【深度建议】打破设备壁垒:关于通义千问实现“全平台智能语音交互”与“知识闭环”的五大核心建议
热门讨论
热门文章
目录空间都删的只剩2G了,还报OSError: [Errno 122] Disk quota exc
ffmpeg提取mp4文件为wav, wav文件比mp4文件小不了多少,怎么办
modelscope报错
你好,请问cv_scp,指代的是验证集数据吗?
如何进行有停顿的音频控制,便于一个故事一次性有感情有停顿的讲完而不需要多次录制?
语音合成速度太慢,且无法并行
modelscope上跑报错,提示要pip install ttsfrd,搞不定
DFSMN回声消除的动态库下载地址禁止访问
模型训练速度太慢
使用modelscope线上16K VAD报错TypeError: 'NoneType' objec
展开全部
docker安装部署FunASR
CosyVoice 2.0:阿里开源升级版语音生成大模型,支持多语言和跨语言语音合成,提升发音和音色等的准确性
FireRedASR:精准识别普通话、方言和歌曲歌词!小红书开源工业级自动语音识别模型
ClearerVoice-Studio:阿里通义开源的语音处理框架,提供语音增强、分离和说话人提取等功能
百聆:集成Deepseek API及语音技术的开源AI语音对话助手,实时交互延迟低至800ms
3D-Speaker:阿里通义开源的多模态说话人识别项目,支持说话人识别、语种识别、多模态识别、说话人重叠检测和日志记录
Step-Audio:开源语音交互新标杆!这个国产AI能说方言会rap,1个模型搞定ASR+TTS+角色扮演
Dolphin:40语种+22方言!清华联合海天瑞声推出的语音识别大模型,识别精度超Whisper两代
Clone-voice:开源的声音克隆工具,支持文本转语音或改变声音风格,支持16种语言
Voice-Pro:开源AI音频处理工具,集成转录、翻译、TTS等一站式服务
展开全部
还有其他疑问?
咨询AI助理