
分区表数据全分区扫描,数据量不大,数据查询过慢,有什么优化的方法吗?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
我建议你可以考虑以下五种优化方法:
增加分区数:增加分区数,将数据分散到更多的分区中,这样可以降低每个分区中的数据量,提高查询效率。但需要注意分区数过多会增加元数据的存储开销,需要根据实际情况进行权衡。
优化查询语句:优化查询语句,使用分区过滤条件等方式来减少需要扫描的分区数,进而提高查询效率。此外,可以根据实际情况使用合适的排序和分组方式,以及合适的数据压缩和序列化方式等来进一步提高查询效率。
增加资源配额:增加查询任务的资源配额,包括CPU、内存和并行度等,以提高查询效率。
使用缓存机制:使用缓存机制来缓存查询结果,减少重复查询的次数,进而提高查询效率。MaxCompute支持使用ODPS Cache和Tablestore缓存查询结果。
数据预处理:将查询频率较高的数据提前处理好,并将结果存储在表中,这样可以避免每次查询时都需要全量扫描分区表,提高查询效率。
MaxCompute查询过慢的话,可以通过MaxCompute的Logview功能诊断慢作业,在官方文档Logview诊断实践中将从几个阶段分析运行慢作业:编译阶段(主要表现为在某个子阶段卡住,即作业长时间停留在某一个子阶段) 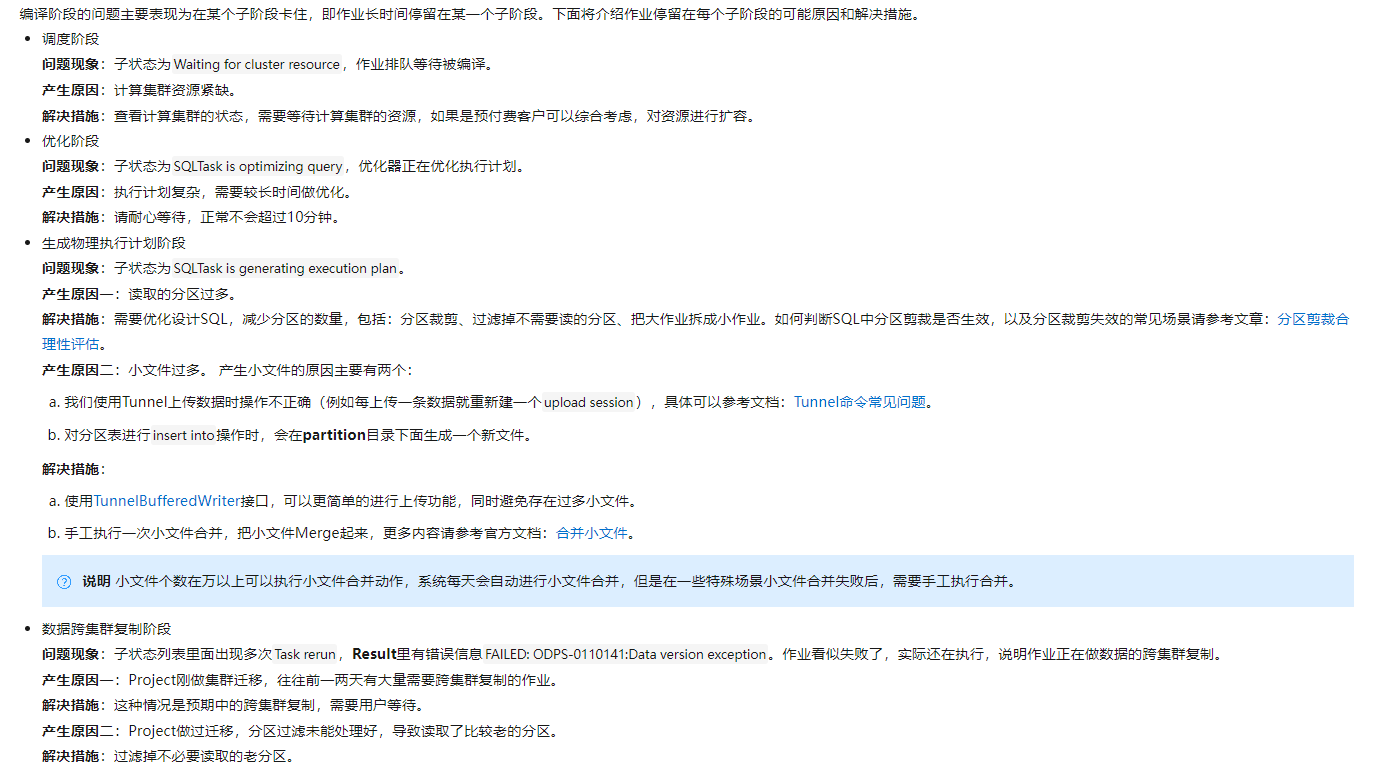 执行阶段(执行阶段卡住或执行时间比预期长的主要原因有等待资源,数据倾斜,UDF执行低效,数据膨胀等);结束阶段(大部分SQL作业在Fuxi作业结束后即停止,有时Fuxi作业结束时,作业总体进度仍然处于运行状态),关于各个阶段的详细问题处理方案可以参考文档:https://help.aliyun.com/document_detail/278738.html
执行阶段(执行阶段卡住或执行时间比预期长的主要原因有等待资源,数据倾斜,UDF执行低效,数据膨胀等);结束阶段(大部分SQL作业在Fuxi作业结束后即停止,有时Fuxi作业结束时,作业总体进度仍然处于运行状态),关于各个阶段的详细问题处理方案可以参考文档:https://help.aliyun.com/document_detail/278738.html
需要看下具体的logview。一般是因为小文件过多或者map阶段并发太小导致的。参考该链接 https://help.aliyun.com/document_detail/102614.html。此回答整理自钉钉群”MaxCompute开发者社区2群“
MaxCompute(原ODPS)是一项面向分析的大数据计算服务,它以Serverless架构提供快速、全托管的在线数据仓库服务,消除传统数据平台在资源扩展性和弹性方面的限制,最小化用户运维投入,使您经济并高效的分析处理海量数据。



