
请教下有flink cdc 对接mysql5.6的demo么?我这边显示各种包错误
请教下有flink cdc 对接mysql5.6的demo么?我这边显示各种包错误
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
-
网站:http://ixiancheng.cn/ 微信订阅号:小马哥学JAVA
MySql Binlog--->Canal--->Kafka--->Flink,MySQL binlog日志处理流程,例如Canal监听binlog把日志写入到kafka中,而Apache Flink实时消费Kafka的数据实现MySql数据的同步。整个流程分为以下几个阶段 1.MySql开启binlog 2.Canal同步binlog数据写入到kafka 3.Flink读取Kafka中binlog数据进行相关的业务处理
2022-11-24 19:51:27赞同 展开评论 -
基于FlinkCDC同步MySQL分库分表构建实时数据湖在 OLTP 系统中,为了解决单表数据量大的问题,通常采用分库分表的方式将单个大表进行拆分以提高系统的吞吐量。 但是为了方便数据分析,通常需要将分库分表拆分出的表在同步到数据仓库、数据湖时,再合并成一个大表。
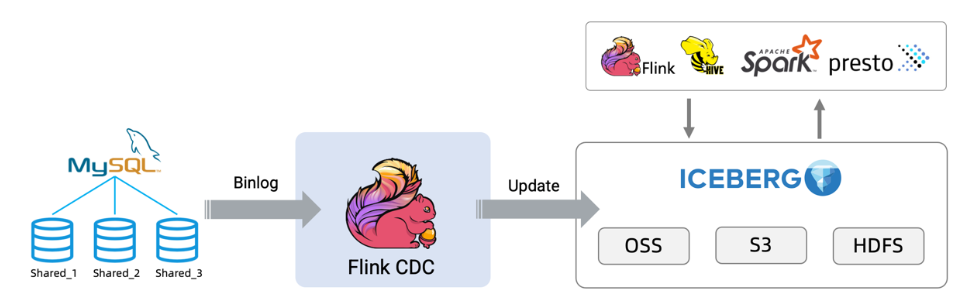 2022-11-23 17:19:23赞同 展开评论
2022-11-23 17:19:23赞同 展开评论 -
十年摸盘键,代码未曾试。 今日码示君,谁有上云事。
CDC是(change data capture),翻译过来就是 捕获数据变更。通常数据处理上,我们说的 CDC 技术主要面向 数据库的变更,是一种用于捕获数据库中数据变更的技术。 它的使用场景(作用)主要有: 1- 数据同步,用于备份,容灾 2- 数据分发,一个数据源分发给多个下游 3- 数据采集(E),面向数据仓库/数据湖的 ETL 数据集成 根据实现机制可以分为两个方向,基于查询和基于日志。 基于查询是就是select进行全表扫描过滤出变更的数据。 基于日志就是连续实时读取数据库的操作log,例如msyql的binlog FlinkCDC采集mysql 到 mysql的demo 前置条件:Mysql 必须是 5.7 或 8.0.X 1- mysql必须开启binlog 2- 创建一个用户,权限 SELECT, RELOAD, SHOW DATABASES, REPLICATION SLAVE, REPLICATION CLIENT 。必须有reload Flink必须是 1.12以上的,如果使用flinkCDC2.0且使用flinkSQL,必须是1.13,java 8 3- 将flink-cdc-connectors的 jar包放入 <FLINK_HOME>/lib 目录下。 4- 引入依赖 (注意 打包成 jar的时候,不要打包进去。不然会报错)
2022-11-23 15:16:17赞同 展开评论 -
天下风云出我辈,一入江湖岁月催,皇图霸业谈笑中,不胜人生一场醉。
FlinkCDC采集mysql 到 mysql的demo一般前置条件都是5.7 或 8.0.X,并且 mysql必须开启binlog,创建一个用户,权限 SELECT, RELOAD, SHOW DATABASES, REPLICATION SLAVE, REPLICATION CLIENT 。必须有reload,flink-cdc-connectors的 jar包放入 <FLINK_HOME>/lib 目录下,下载网页flink-cdc-connector(包括了 mysql postgres和mongdb)->https://github.com/ververica/flink-cdc-connectors/releases 引入依赖 (注意 打包成 jar的时候,不要打包进去。不然会报错),之后就是调试测试了
2022-11-23 14:54:31赞同 展开评论


实时计算Flink版是阿里云提供的全托管Serverless Flink云服务,基于 Apache Flink 构建的企业级、高性能实时大数据处理系统。提供全托管版 Flink 集群和引擎,提高作业开发运维效率。
