
怎么理解MapReduce的执行过程?
版权声明:本文内容由阿里云实名注册用户自发贡献,版权归原作者所有,阿里云开发者社区不拥有其著作权,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有涉嫌抄袭的内容,填写侵权投诉表单进行举报,一经查实,本社区将立刻删除涉嫌侵权内容。
MapReduce 简要执行过程如下图所示,
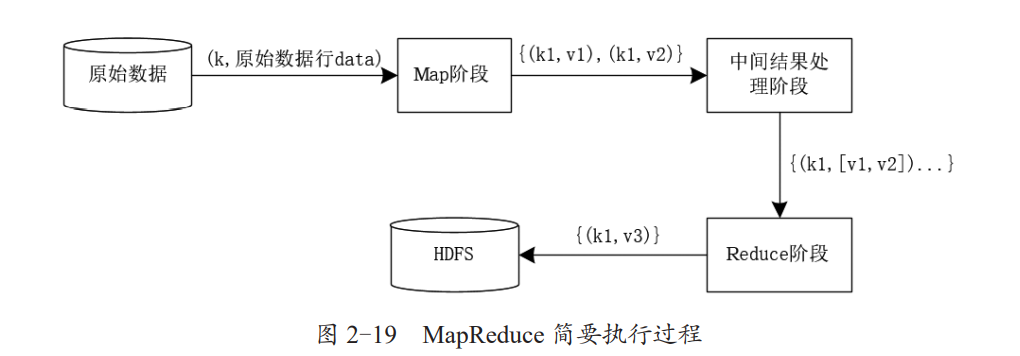
可以看出,原始数据以“(k, 原始数据行 data)”的形式输入 Map 阶段;经过Map 阶段的 map() 函数的一系列并行处理后,将中间结果数据以“{(k1, v1), (k1, v2)}”的形式输出到本地;然后经过 MapReduce 框架的中间结果处理阶段的处理(中间结果处理阶段会根据键对数据进行排序和聚合处理,将键相同的数据发送到同一个 reduce() 函数处理);
接下来就进入 Reduce 阶段,Reduce 阶段接收到的数据都是以“{k1,[v1, v2]...}”形式存在的数据,这些数据经过 Reduce 阶段的处理之后,最终得出“{(k1,v3)}”格式的键值对结果数据,并将最终结果数据输出到 HDFS。
以上内容摘自《海量数据处理与大数据技术实战》电子书,点击https://developer.aliyun.com/topic/download?id=8205可下载完整版


